 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlux Already Knows - Activating Subject-Driven Image Generation without Training
Apr 12, 2025We propose a simple yet effective zero-shot framework for subject-driven image generation using a vanilla Flux model. By framing the task as grid-based image completion and simply replicating the subject image(s) in a mosaic layout, we activate strong identity-preserving capabilities without any additional data, training, or inference-time fine-tuning. This "free lunch" approach is further strengthened by a novel cascade attention design and meta prompting technique, boosting fidelity and versatility. Experimental results show that our method outperforms baselines across multiple key metrics in benchmarks and human preference studies, with trade-offs in certain aspects. Additionally, it supports diverse edits, including logo insertion, virtual try-on, and subject replacement or insertion. These results demonstrate that a pre-trained foundational text-to-image model can enable high-quality, resource-efficient subject-driven generation, opening new possibilities for lightweight customization in downstream applications.
Score Normalization for a Faster Diffusion Exponential Integrator Sampler
Nov 10, 2023Recently, Zhang et al. have proposed the Diffusion Exponential Integrator Sampler (DEIS) for fast generation of samples from Diffusion Models. It leverages the semi-linear nature of the probability flow ordinary differential equation (ODE) in order to greatly reduce integration error and improve generation quality at low numbers of function evaluations (NFEs). Key to this approach is the score function reparameterisation, which reduces the integration error incurred from using a fixed score function estimate over each integration step. The original authors use the default parameterisation used by models trained for noise prediction -- multiply the score by the standard deviation of the conditional forward noising distribution. We find that although the mean absolute value of this score parameterisation is close to constant for a large portion of the reverse sampling process, it changes rapidly at the end of sampling. As a simple fix, we propose to instead reparameterise the score (at inference) by dividing it by the average absolute value of previous score estimates at that time step collected from offline high NFE generations. We find that our score normalisation (DEIS-SN) consistently improves FID compared to vanilla DEIS, showing an improvement at 10 NFEs from 6.44 to 5.57 on CIFAR-10 and from 5.9 to 4.95 on LSUN-Church 64x64. Our code is available at https://github.com/mtkresearch/Diffusion-DEIS-SN
Image generation with shortest path diffusion
Jun 01, 2023The field of image generation has made significant progress thanks to the introduction of Diffusion Models, which learn to progressively reverse a given image corruption. Recently, a few studies introduced alternative ways of corrupting images in Diffusion Models, with an emphasis on blurring. However, these studies are purely empirical and it remains unclear what is the optimal procedure for corrupting an image. In this work, we hypothesize that the optimal procedure minimizes the length of the path taken when corrupting an image towards a given final state. We propose the Fisher metric for the path length, measured in the space of probability distributions. We compute the shortest path according to this metric, and we show that it corresponds to a combination of image sharpening, rather than blurring, and noise deblurring. While the corruption was chosen arbitrarily in previous work, our Shortest Path Diffusion (SPD) determines uniquely the entire spatiotemporal structure of the corruption. We show that SPD improves on strong baselines without any hyperparameter tuning, and outperforms all previous Diffusion Models based on image blurring. Furthermore, any small deviation from the shortest path leads to worse performance, suggesting that SPD provides the optimal procedure to corrupt images. Our work sheds new light on observations made in recent works and provides a new approach to improve diffusion models on images and other types of data.
Towards Fast Simulation of Environmental Fluid Mechanics with Multi-Scale Graph Neural Networks
May 05, 2022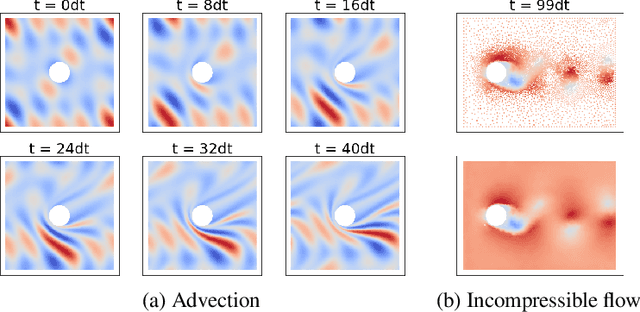

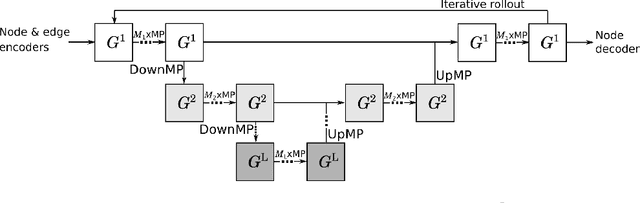

Numerical simulators are essential tools in the study of natural fluid-systems, but their performance often limits application in practice. Recent machine-learning approaches have demonstrated their ability to accelerate spatio-temporal predictions, although, with only moderate accuracy in comparison. Here we introduce MultiScaleGNN, a novel multi-scale graph neural network model for learning to infer unsteady continuum mechanics in problems encompassing a range of length scales and complex boundary geometries. We demonstrate this method on advection problems and incompressible fluid dynamics, both fundamental phenomena in oceanic and atmospheric processes. Our results show good extrapolation to new domain geometries and parameters for long-term temporal simulations. Simulations obtained with MultiScaleGNN are between two and four orders of magnitude faster than those on which it was trained.
Disentangling ODE parameters from dynamics in VAEs
Aug 26, 2021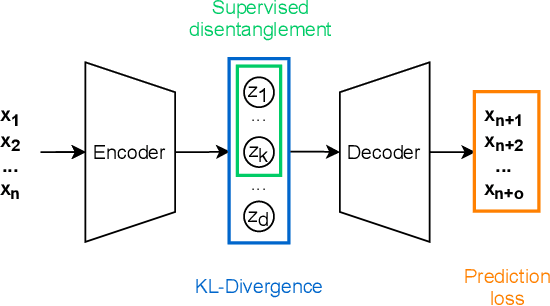
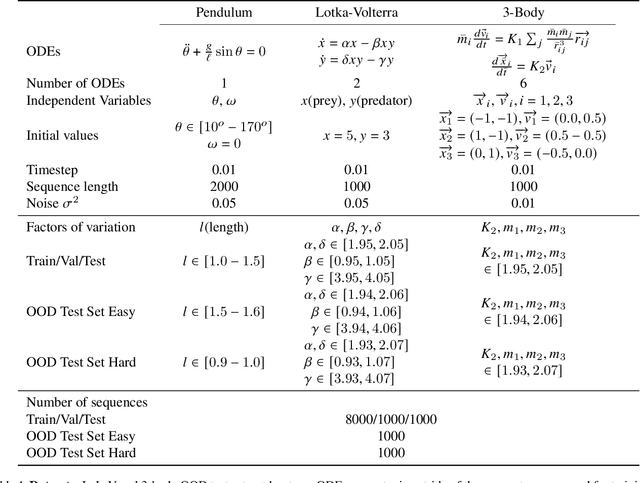
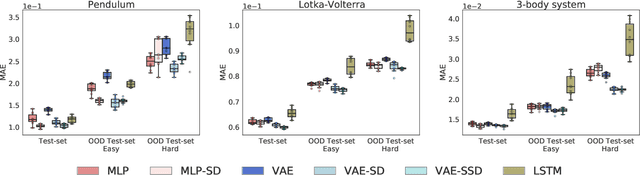

Deep networks have become increasingly of interest in dynamical system prediction, but generalization remains elusive. In this work, we consider the physical parameters of ODEs as factors of variation of the data generating process. By leveraging ideas from supervised disentanglement in VAEs, we aim to separate the ODE parameters from the dynamics in the latent space. Experiments show that supervised disentanglement allows VAEs to capture the variability in the dynamics and extrapolate better to ODE parameter spaces that were not present in the training data.
Simulating Continuum Mechanics with Multi-Scale Graph Neural Networks
Jun 09, 2021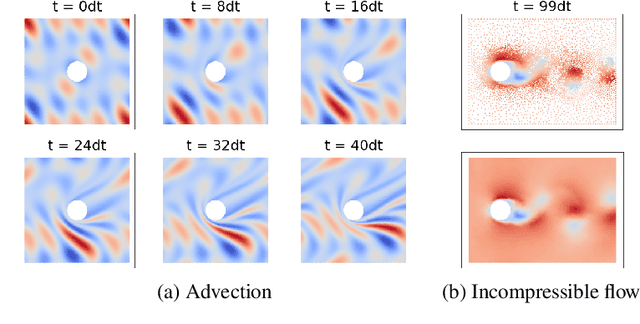
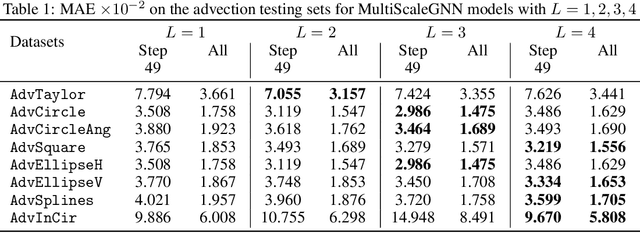
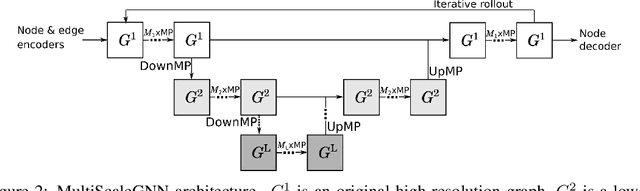

Continuum mechanics simulators, numerically solving one or more partial differential equations, are essential tools in many areas of science and engineering, but their performance often limits application in practice. Recent modern machine learning approaches have demonstrated their ability to accelerate spatio-temporal predictions, although, with only moderate accuracy in comparison. Here we introduce MultiScaleGNN, a novel multi-scale graph neural network model for learning to infer unsteady continuum mechanics. MultiScaleGNN represents the physical domain as an unstructured set of nodes, and it constructs one or more graphs, each of them encoding different scales of spatial resolution. Successive learnt message passing between these graphs improves the ability of GNNs to capture and forecast the system state in problems encompassing a range of length scales. Using graph representations, MultiScaleGNN can impose periodic boundary conditions as an inductive bias on the edges in the graphs, and achieve independence to the nodes' positions. We demonstrate this method on advection problems and incompressible fluid dynamics. Our results show that the proposed model can generalise from uniform advection fields to high-gradient fields on complex domains at test time and infer long-term Navier-Stokes solutions within a range of Reynolds numbers. Simulations obtained with MultiScaleGNN are between two and four orders of magnitude faster than the ones on which it was trained.
Simulating Surface Wave Dynamics with Convolutional Networks
Dec 01, 2020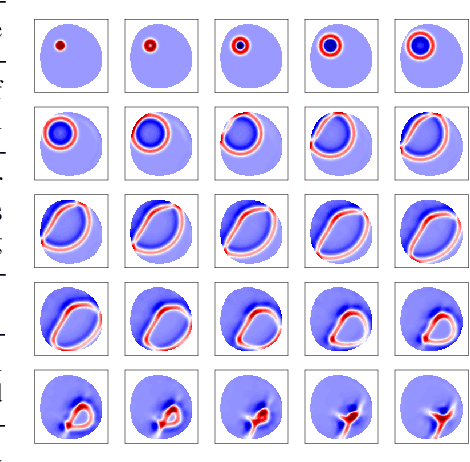
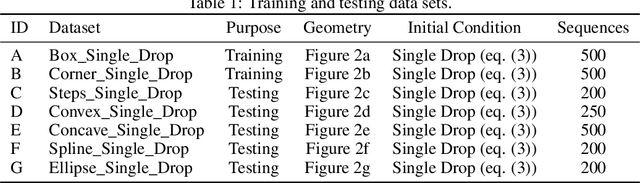
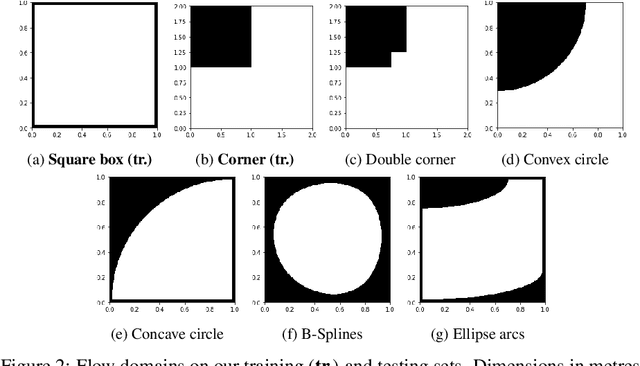
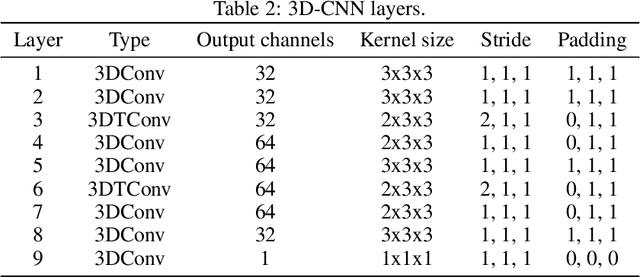
We investigate the performance of fully convolutional networks to simulate the motion and interaction of surface waves in open and closed complex geometries. We focus on a U-Net architecture and analyse how well it generalises to geometric configurations not seen during training. We demonstrate that a modified U-Net architecture is capable of accurately predicting the height distribution of waves on a liquid surface within curved and multi-faceted open and closed geometries, when only simple box and right-angled corner geometries were seen during training. We also consider a separate and independent 3D CNN for performing time-interpolation on the predictions produced by our U-Net. This allows generating simulations with a smaller time-step size than the one the U-Net has been trained for.
Comparing recurrent and convolutional neural networks for predicting wave propagation
Mar 09, 2020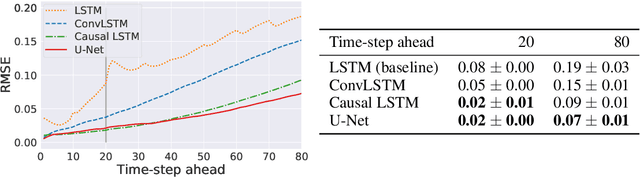

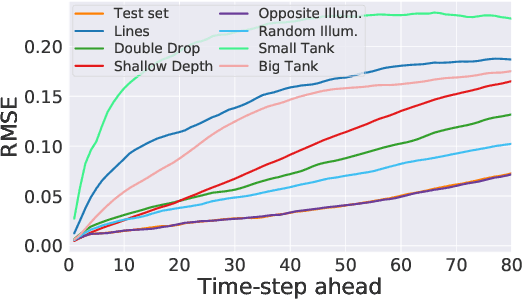
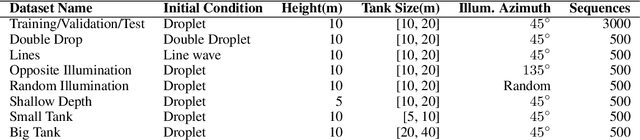
Dynamical systems can be modelled by partial differential equations and numerical computations are used everywhere in science and engineering. In this work, we investigate the performance of recurrent and convolutional deep neural network architectures to predict the surface waves. The system is governed by the Saint-Venant equations. We improve on the long-term prediction over previous methods while keeping the inference time at a fraction of numerical simulations. We also show that convolutional networks perform at least as well as recurrent networks in this task. Finally, we assess the generalisation capability of each network by extrapolating in longer time-frames and in different physical settings.
An Empirical Evaluation of Adversarial Robustness under Transfer Learning
May 23, 2019
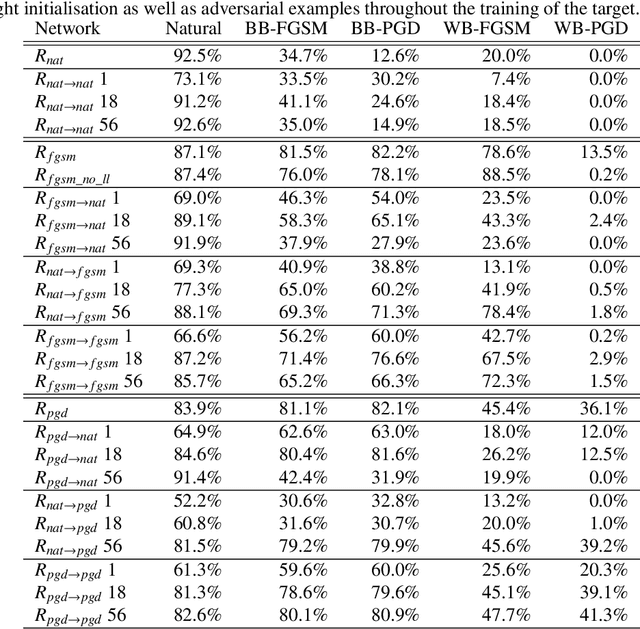
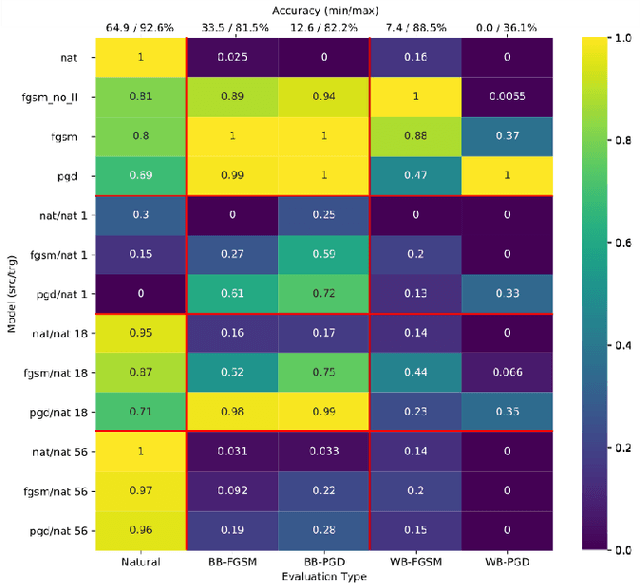
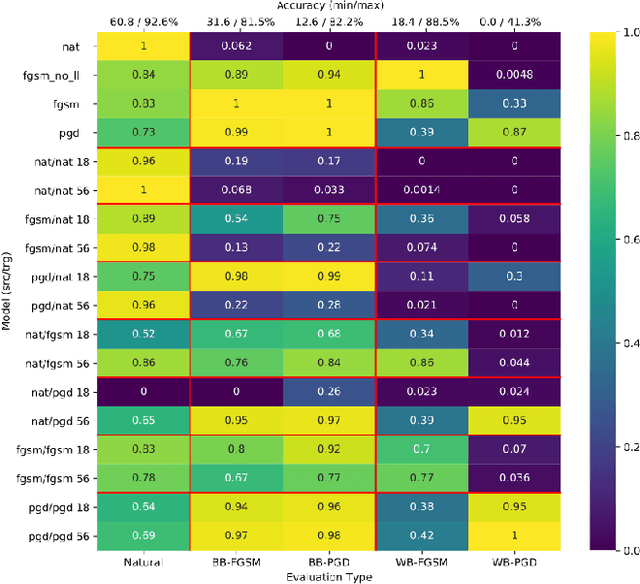
In this work, we evaluate adversarial robustness in the context of transfer learning from a source trained on CIFAR 100 to a target network trained on CIFAR 10. Specifically, we study the effects of using robust optimisation in the source and target networks. This allows us to identify transfer learning strategies under which adversarial defences are successfully retained, in addition to revealing potential vulnerabilities. We study the extent to which features learnt by a fast gradient sign method (FGSM) and its iterative alternative (PGD) can preserve their defence properties against black and white-box attacks under three different transfer learning strategies. We find that using PGD examples during training on the source task leads to more general robust features that are easier to transfer. Furthermore, under successful transfer, it achieves 5.2% more accuracy against white-box PGD attacks than suitable baselines. Overall, our empirical evaluations give insights on how well adversarial robustness under transfer learning can generalise.