 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM3-LiteText: An Anatomical Study of the SAM3 Text Encoder for Efficient Vision-Language Segmentation
Feb 12, 2026Vision-language segmentation models such as SAM3 enable flexible, prompt-driven visual grounding, but inherit large, general-purpose text encoders originally designed for open-ended language understanding. In practice, segmentation prompts are short, structured, and semantically constrained, leading to substantial over-provisioning in text encoder capacity and persistent computational and memory overhead. In this paper, we perform a large-scale anatomical analysis of text prompting in vision-language segmentation, covering 404,796 real prompts across multiple benchmarks. Our analysis reveals severe redundancy: most context windows are underutilized, vocabulary usage is highly sparse, and text embeddings lie on low-dimensional manifold despite high-dimensional representations. Motivated by these findings, we propose SAM3-LiteText, a lightweight text encoding framework that replaces the original SAM3 text encoder with a compact MobileCLIP student that is optimized by knowledge distillation. Extensive experiments on image and video segmentation benchmarks show that SAM3-LiteText reduces text encoder parameters by up to 88%, substantially reducing static memory footprint, while maintaining segmentation performance comparable to the original model. Code: https://github.com/SimonZeng7108/efficientsam3/tree/sam3_litetext.
MoonSeg3R: Monocular Online Zero-Shot Segment Anything in 3D with Reconstructive Foundation Priors
Dec 17, 2025In this paper, we focus on online zero-shot monocular 3D instance segmentation, a novel practical setting where existing approaches fail to perform because they rely on posed RGB-D sequences. To overcome this limitation, we leverage CUT3R, a recent Reconstructive Foundation Model (RFM), to provide reliable geometric priors from a single RGB stream. We propose MoonSeg3R, which introduces three key components: (1) a self-supervised query refinement module with spatial-semantic distillation that transforms segmentation masks from 2D visual foundation models (VFMs) into discriminative 3D queries; (2) a 3D query index memory that provides temporal consistency by retrieving contextual queries; and (3) a state-distribution token from CUT3R that acts as a mask identity descriptor to strengthen cross-frame fusion. Experiments on ScanNet200 and SceneNN show that MoonSeg3R is the first method to enable online monocular 3D segmentation and achieves performance competitive with state-of-the-art RGB-D-based systems. Code and models will be released.
Attentive Feature Aggregation or: How Policies Learn to Stop Worrying about Robustness and Attend to Task-Relevant Visual Cues
Nov 13, 2025The adoption of pre-trained visual representations (PVRs), leveraging features from large-scale vision models, has become a popular paradigm for training visuomotor policies. However, these powerful representations can encode a broad range of task-irrelevant scene information, making the resulting trained policies vulnerable to out-of-domain visual changes and distractors. In this work we address visuomotor policy feature pooling as a solution to the observed lack of robustness in perturbed scenes. We achieve this via Attentive Feature Aggregation (AFA), a lightweight, trainable pooling mechanism that learns to naturally attend to task-relevant visual cues, ignoring even semantically rich scene distractors. Through extensive experiments in both simulation and the real world, we demonstrate that policies trained with AFA significantly outperform standard pooling approaches in the presence of visual perturbations, without requiring expensive dataset augmentation or fine-tuning of the PVR. Our findings show that ignoring extraneous visual information is a crucial step towards deploying robust and generalisable visuomotor policies. Project Page: tsagkas.github.io/afa
GFix: Perceptually Enhanced Gaussian Splatting Video Compression
Nov 10, 2025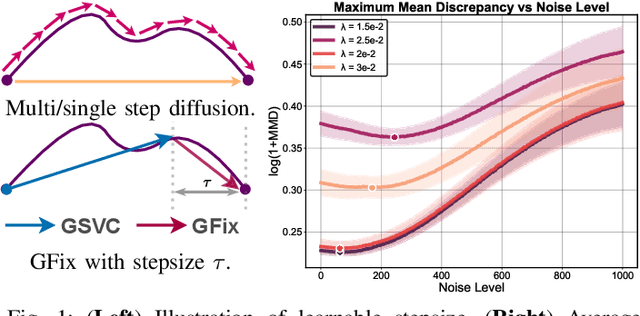
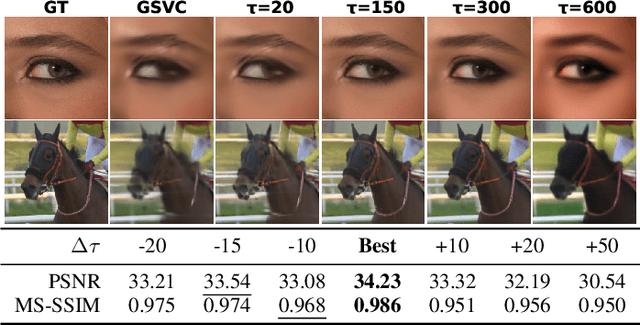
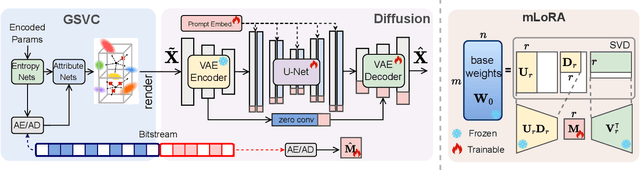
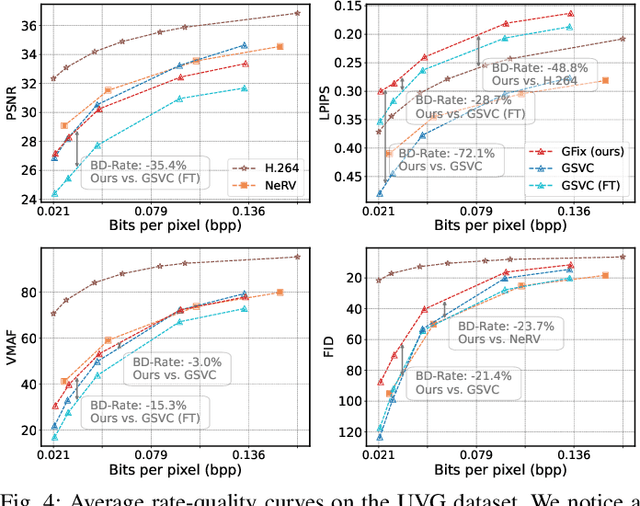
3D Gaussian Splatting (3DGS) enhances 3D scene reconstruction through explicit representation and fast rendering, demonstrating potential benefits for various low-level vision tasks, including video compression. However, existing 3DGS-based video codecs generally exhibit more noticeable visual artifacts and relatively low compression ratios. In this paper, we specifically target the perceptual enhancement of 3DGS-based video compression, based on the assumption that artifacts from 3DGS rendering and quantization resemble noisy latents sampled during diffusion training. Building on this premise, we propose a content-adaptive framework, GFix, comprising a streamlined, single-step diffusion model that serves as an off-the-shelf neural enhancer. Moreover, to increase compression efficiency, We propose a modulated LoRA scheme that freezes the low-rank decompositions and modulates the intermediate hidden states, thereby achieving efficient adaptation of the diffusion backbone with highly compressible updates. Experimental results show that GFix delivers strong perceptual quality enhancement, outperforming GSVC with up to 72.1% BD-rate savings in LPIPS and 21.4% in FID.
When Pre-trained Visual Representations Fall Short: Limitations in Visuo-Motor Robot Learning
Feb 05, 2025The integration of pre-trained visual representations (PVRs) into visuo-motor robot learning has emerged as a promising alternative to training visual encoders from scratch. However, PVRs face critical challenges in the context of policy learning, including temporal entanglement and an inability to generalise even in the presence of minor scene perturbations. These limitations hinder performance in tasks requiring temporal awareness and robustness to scene changes. This work identifies these shortcomings and proposes solutions to address them. First, we augment PVR features with temporal perception and a sense of task completion, effectively disentangling them in time. Second, we introduce a module that learns to selectively attend to task-relevant local features, enhancing robustness when evaluated on out-of-distribution scenes. Our experiments demonstrate significant performance improvements, particularly in PVRs trained with masking objectives, and validate the effectiveness of our enhancements in addressing PVR-specific limitations.
DepthCues: Evaluating Monocular Depth Perception in Large Vision Models
Nov 26, 2024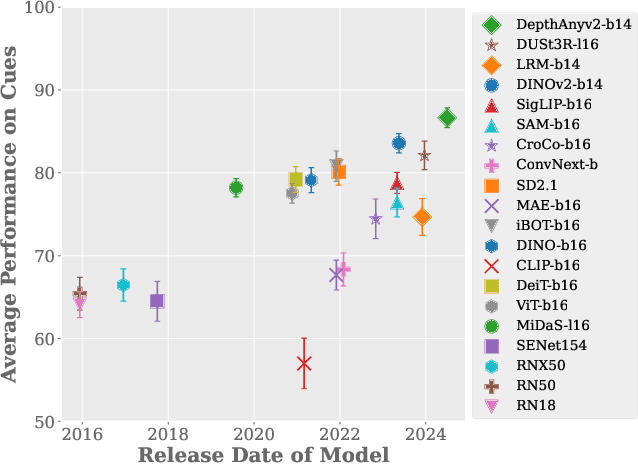
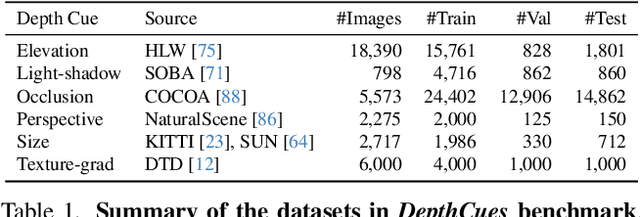
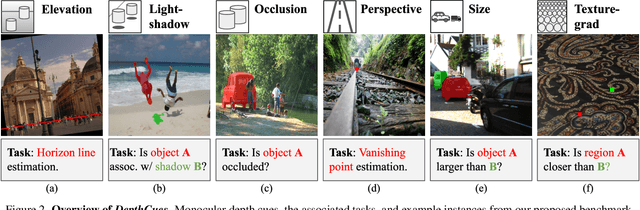
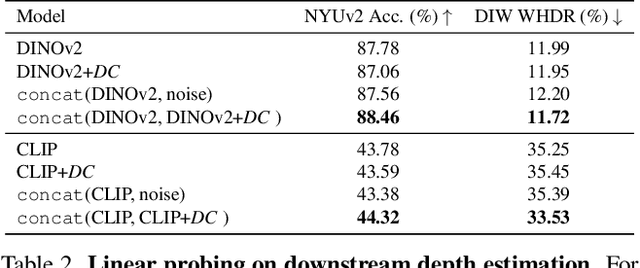
Large-scale pre-trained vision models are becoming increasingly prevalent, offering expressive and generalizable visual representations that benefit various downstream tasks. Recent studies on the emergent properties of these models have revealed their high-level geometric understanding, in particular in the context of depth perception. However, it remains unclear how depth perception arises in these models without explicit depth supervision provided during pre-training. To investigate this, we examine whether the monocular depth cues, similar to those used by the human visual system, emerge in these models. We introduce a new benchmark, DepthCues, designed to evaluate depth cue understanding, and present findings across 20 diverse and representative pre-trained vision models. Our analysis shows that human-like depth cues emerge in more recent larger models. We also explore enhancing depth perception in large vision models by fine-tuning on DepthCues, and find that even without dense depth supervision, this improves depth estimation. To support further research, our benchmark and evaluation code will be made publicly available for studying depth perception in vision models.
MVAD: A Multiple Visual Artifact Detector for Video Streaming
May 31, 2024Visual artifacts are often introduced into streamed video content, due to prevailing conditions during content production and/or delivery. Since these can degrade the quality of the user's experience, it is important to automatically and accurately detect them in order to enable effective quality measurement and enhancement. Existing detection methods often focus on a single type of artifact and/or determine the presence of an artifact through thresholding objective quality indices. Such approaches have been reported to offer inconsistent prediction performance and are also impractical for real-world applications where multiple artifacts co-exist and interact. In this paper, we propose a Multiple Visual Artifact Detector, MVAD, for video streaming which, for the first time, is able to detect multiple artifacts using a single framework that is not reliant on video quality assessment models. Our approach employs a new Artifact-aware Dynamic Feature Extractor (ADFE) to obtain artifact-relevant spatial features within each frame for multiple artifact types. The extracted features are further processed by a Recurrent Memory Vision Transformer (RMViT) module, which captures both short-term and long-term temporal information within the input video. The proposed network architecture is optimized in an end-to-end manner based on a new, large and diverse training database that is generated by simulating the video streaming pipeline and based on Adversarial Data Augmentation. This model has been evaluated on two video artifact databases, Maxwell and BVI-Artifact, and achieves consistent and improved prediction results for ten target visual artifacts when compared to seven existing single and multiple artifact detectors. The source code and training database will be available at https://chenfeng-bristol.github.io/MVAD/.
RMT-BVQA: Recurrent Memory Transformer-based Blind Video Quality Assessment for Enhanced Video Content
May 15, 2024With recent advances in deep learning, numerous algorithms have been developed to enhance video quality, reduce visual artefacts and improve perceptual quality. However, little research has been reported on the quality assessment of enhanced content - the evaluation of enhancement methods is often based on quality metrics that were designed for compression applications. In this paper, we propose a novel blind deep video quality assessment (VQA) method specifically for enhanced video content. It employs a new Recurrent Memory Transformer (RMT) based network architecture to obtain video quality representations, which is optimised through a novel content-quality-aware contrastive learning strategy based on a new database containing 13K training patches with enhanced content. The extracted quality representations are then combined through linear regression to generate video-level quality indices. The proposed method, RMT-BVQA, has been evaluated on the VDPVE (VQA Dataset for Perceptual Video Enhancement) database through a five-fold cross validation. The results show its superior correlation performance when compared to ten existing no-reference quality metrics.
Full-reference Video Quality Assessment for User Generated Content Transcoding
Dec 19, 2023



Unlike video coding for professional content, the delivery pipeline of User Generated Content (UGC) involves transcoding where unpristine reference content needs to be compressed repeatedly. In this work, we observe that existing full-/no-reference quality metrics fail to accurately predict the perceptual quality difference between transcoded UGC content and the corresponding unpristine references. Therefore, they are unsuited for guiding the rate-distortion optimisation process in the transcoding process. In this context, we propose a bespoke full-reference deep video quality metric for UGC transcoding. The proposed method features a transcoding-specific weakly supervised training strategy employing a quality ranking-based Siamese structure. The proposed method is evaluated on the YouTube-UGC VP9 subset and the LIVE-Wild database, demonstrating state-of-the-art performance compared to existing VQA methods.
BVI-Artefact: An Artefact Detection Benchmark Dataset for Streamed Videos
Dec 14, 2023
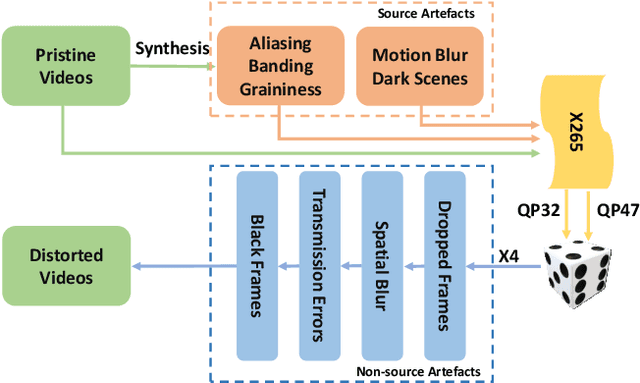
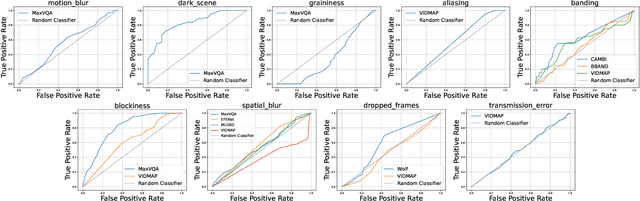
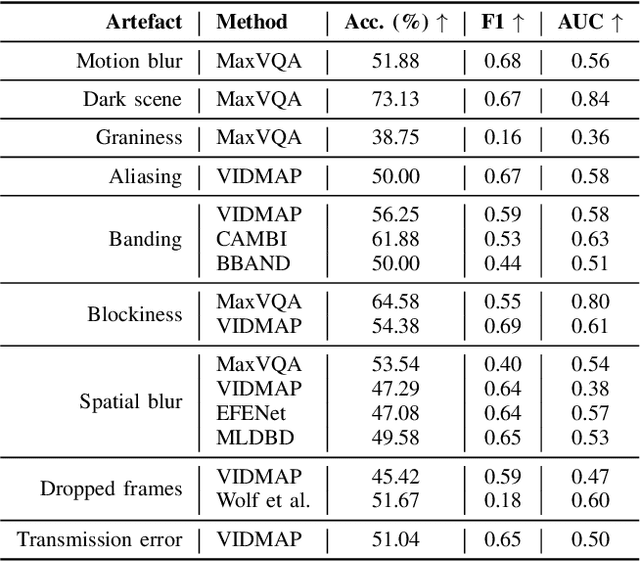
Professionally generated content (PGC) streamed online can contain visual artefacts that degrade the quality of user experience. These artefacts arise from different stages of the streaming pipeline, including acquisition, post-production, compression, and transmission. To better guide streaming experience enhancement, it is important to detect specific artefacts at the user end in the absence of a pristine reference. In this work, we address the lack of a comprehensive benchmark for artefact detection within streamed PGC, via the creation and validation of a large database, BVI-Artefact. Considering the ten most relevant artefact types encountered in video streaming, we collected and generated 480 video sequences, each containing various artefacts with associated binary artefact labels. Based on this new database, existing artefact detection methods are benchmarked, with results showing the challenging nature of this tasks and indicating the requirement of more reliable artefact detection methods. To facilitate further research in this area, we have made BVI-Artifact publicly available at https://chenfeng-bristol.github.io/BVI-Artefact/