 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance Data Condensation for Image Super-Resolution
May 27, 2025
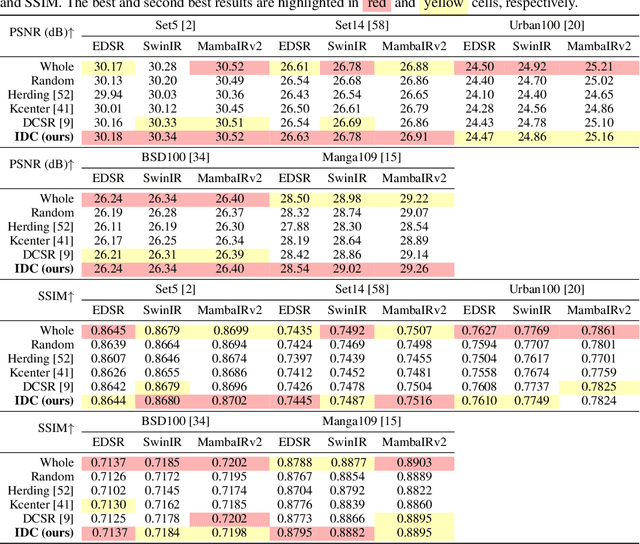
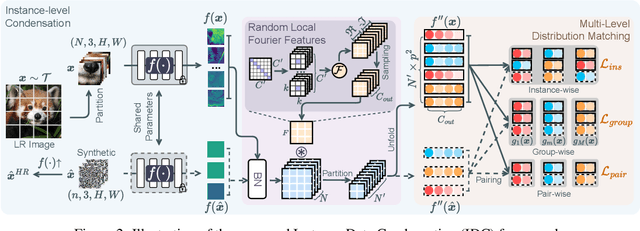
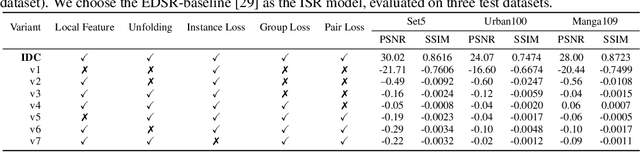
Deep learning based image Super-Resolution (ISR) relies on large training datasets to optimize model generalization; this requires substantial computational and storage resources during training. While dataset condensation has shown potential in improving data efficiency and privacy for high-level computer vision tasks, it has not yet been fully exploited for ISR. In this paper, we propose a novel Instance Data Condensation (IDC) framework specifically for ISR, which achieves instance-level data condensation through Random Local Fourier Feature Extraction and Multi-level Feature Distribution Matching. This aims to optimize feature distributions at both global and local levels and obtain high-quality synthesized training content with fine detail. This framework has been utilized to condense the most commonly used training dataset for ISR, DIV2K, with a 10% condensation rate. The resulting synthetic dataset offers comparable or (in certain cases) even better performance compared to the original full dataset and excellent training stability when used to train various popular ISR models. To the best of our knowledge, this is the first time that a condensed/synthetic dataset (with a 10% data volume) has demonstrated such performance. The source code and the synthetic dataset have been made available at https://github.com/.
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024
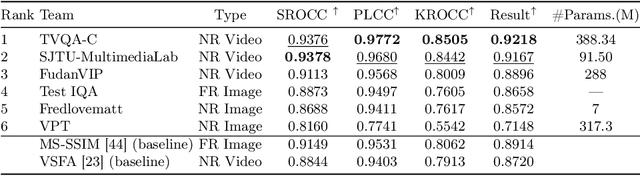
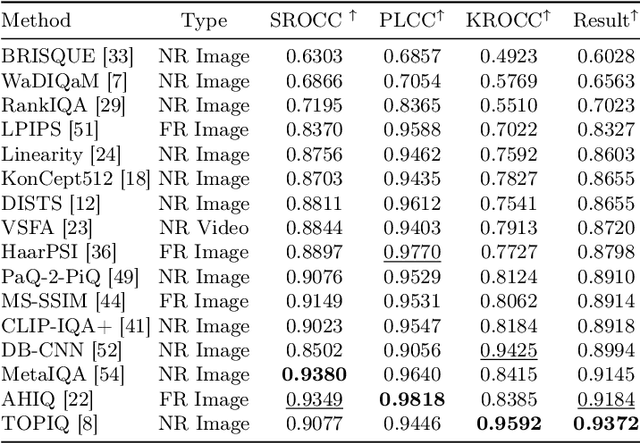
Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
BVI-UGC: A Video Quality Database for User-Generated Content Transcoding
Aug 13, 2024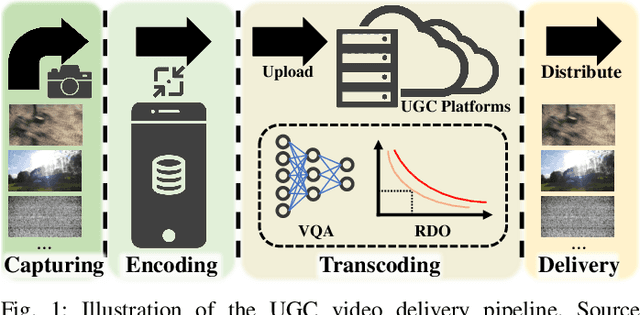



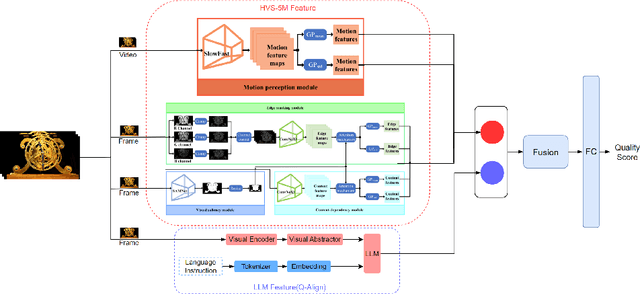
In recent years, user-generated content (UGC) has become one of the major video types consumed via streaming networks. Numerous research contributions have focused on assessing its visual quality through subjective tests and objective modeling. In most cases, objective assessments are based on a no-reference scenario, where the corresponding reference content is assumed not to be available. However, full-reference video quality assessment is also important for UGC in the delivery pipeline, particularly associated with the video transcoding process. In this context, we present a new UGC video quality database, BVI-UGC, for user-generated content transcoding, which contains 60 (non-pristine) reference videos and 1,080 test sequences. In this work, we simulated the creation of non-pristine reference sequences (with a wide range of compression distortions), typical of content uploaded to UGC platforms for transcoding. A comprehensive crowdsourced subjective study was then conducted involving more than 3,500 human participants. Based on this collected subjective data, we benchmarked the performance of 10 full-reference and 11 no-reference quality metrics. Our results demonstrate the poor performance (SROCC values are lower than 0.6) of these metrics in predicting the perceptual quality of UGC in two different scenarios (with or without a reference).
AIS 2024 Challenge on Video Quality Assessment of User-Generated Content: Methods and Results
Apr 24, 2024



This paper reviews the AIS 2024 Video Quality Assessment (VQA) Challenge, focused on User-Generated Content (UGC). The aim of this challenge is to gather deep learning-based methods capable of estimating the perceptual quality of UGC videos. The user-generated videos from the YouTube UGC Dataset include diverse content (sports, games, lyrics, anime, etc.), quality and resolutions. The proposed methods must process 30 FHD frames under 1 second. In the challenge, a total of 102 participants registered, and 15 submitted code and models. The performance of the top-5 submissions is reviewed and provided here as a survey of diverse deep models for efficient video quality assessment of user-generated content.
NTIRE 2024 Challenge on Short-form UGC Video Quality Assessment: Methods and Results
Apr 17, 2024



This paper reviews the NTIRE 2024 Challenge on Shortform UGC Video Quality Assessment (S-UGC VQA), where various excellent solutions are submitted and evaluated on the collected dataset KVQ from popular short-form video platform, i.e., Kuaishou/Kwai Platform. The KVQ database is divided into three parts, including 2926 videos for training, 420 videos for validation, and 854 videos for testing. The purpose is to build new benchmarks and advance the development of S-UGC VQA. The competition had 200 participants and 13 teams submitted valid solutions for the final testing phase. The proposed solutions achieved state-of-the-art performances for S-UGC VQA. The project can be found at https://github.com/lixinustc/KVQChallenge-CVPR-NTIRE2024.
Contrastive Pre-Training with Multi-View Fusion for No-Reference Point Cloud Quality Assessment
Mar 27, 2024

No-reference point cloud quality assessment (NR-PCQA) aims to automatically evaluate the perceptual quality of distorted point clouds without available reference, which have achieved tremendous improvements due to the utilization of deep neural networks. However, learning-based NR-PCQA methods suffer from the scarcity of labeled data and usually perform suboptimally in terms of generalization. To solve the problem, we propose a novel contrastive pre-training framework tailored for PCQA (CoPA), which enables the pre-trained model to learn quality-aware representations from unlabeled data. To obtain anchors in the representation space, we project point clouds with different distortions into images and randomly mix their local patches to form mixed images with multiple distortions. Utilizing the generated anchors, we constrain the pre-training process via a quality-aware contrastive loss following the philosophy that perceptual quality is closely related to both content and distortion. Furthermore, in the model fine-tuning stage, we propose a semantic-guided multi-view fusion module to effectively integrate the features of projected images from multiple perspectives. Extensive experiments show that our method outperforms the state-of-the-art PCQA methods on popular benchmarks. Further investigations demonstrate that CoPA can also benefit existing learning-based PCQA models.
Transferable Learned Image Compression-Resistant Adversarial Perturbations
Jan 06, 2024Adversarial attacks can readily disrupt the image classification system, revealing the vulnerability of DNN-based recognition tasks. While existing adversarial perturbations are primarily applied to uncompressed images or compressed images by the traditional image compression method, i.e., JPEG, limited studies have investigated the robustness of models for image classification in the context of DNN-based image compression. With the rapid evolution of advanced image compression, DNN-based learned image compression has emerged as the promising approach for transmitting images in many security-critical applications, such as cloud-based face recognition and autonomous driving, due to its superior performance over traditional compression. Therefore, there is a pressing need to fully investigate the robustness of a classification system post-processed by learned image compression. To bridge this research gap, we explore the adversarial attack on a new pipeline that targets image classification models that utilize learned image compressors as pre-processing modules. Furthermore, to enhance the transferability of perturbations across various quality levels and architectures of learned image compression models, we introduce a saliency score-based sampling method to enable the fast generation of transferable perturbation. Extensive experiments with popular attack methods demonstrate the enhanced transferability of our proposed method when attacking images that have been post-processed with different learned image compression models.
Full-reference Video Quality Assessment for User Generated Content Transcoding
Dec 19, 2023



Unlike video coding for professional content, the delivery pipeline of User Generated Content (UGC) involves transcoding where unpristine reference content needs to be compressed repeatedly. In this work, we observe that existing full-/no-reference quality metrics fail to accurately predict the perceptual quality difference between transcoded UGC content and the corresponding unpristine references. Therefore, they are unsuited for guiding the rate-distortion optimisation process in the transcoding process. In this context, we propose a bespoke full-reference deep video quality metric for UGC transcoding. The proposed method features a transcoding-specific weakly supervised training strategy employing a quality ranking-based Siamese structure. The proposed method is evaluated on the YouTube-UGC VP9 subset and the LIVE-Wild database, demonstrating state-of-the-art performance compared to existing VQA methods.
Corner-to-Center Long-range Context Model for Efficient Learned Image Compression
Nov 29, 2023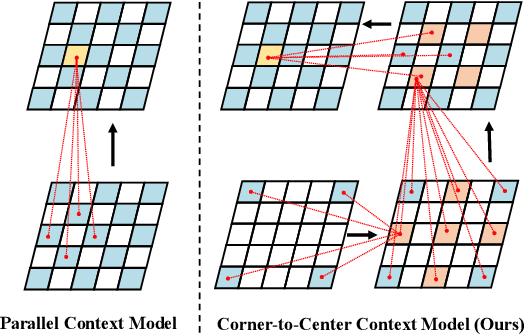
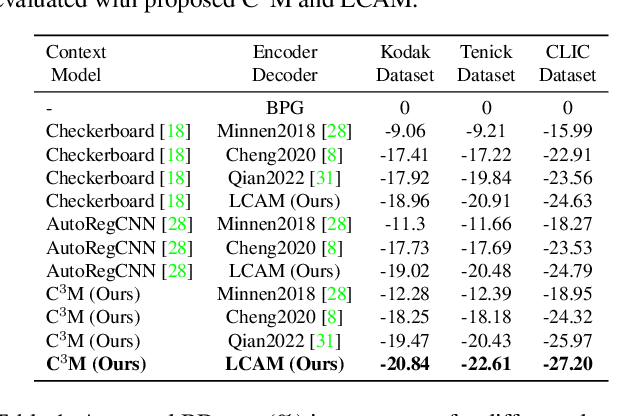
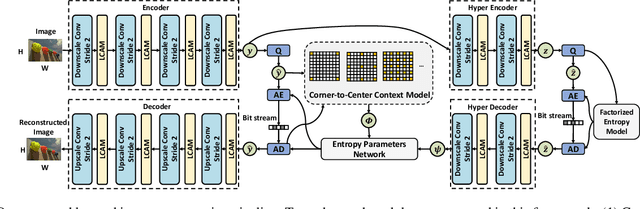

In the framework of learned image compression, the context model plays a pivotal role in capturing the dependencies among latent representations. To reduce the decoding time resulting from the serial autoregressive context model, the parallel context model has been proposed as an alternative that necessitates only two passes during the decoding phase, thus facilitating efficient image compression in real-world scenarios. However, performance degradation occurs due to its incomplete casual context. To tackle this issue, we conduct an in-depth analysis of the performance degradation observed in existing parallel context models, focusing on two aspects: the Quantity and Quality of information utilized for context prediction and decoding. Based on such analysis, we propose the \textbf{Corner-to-Center transformer-based Context Model (C$^3$M)} designed to enhance context and latent predictions and improve rate-distortion performance. Specifically, we leverage the logarithmic-based prediction order to predict more context features from corner to center progressively. In addition, to enlarge the receptive field in the analysis and synthesis transformation, we use the Long-range Crossing Attention Module (LCAM) in the encoder/decoder to capture the long-range semantic information by assigning the different window shapes in different channels. Extensive experimental evaluations show that the proposed method is effective and outperforms the state-of-the-art parallel methods. Finally, according to the subjective analysis, we suggest that improving the detailed representation in transformer-based image compression is a promising direction to be explored.
SJTU-TMQA: A quality assessment database for static mesh with texture map
Sep 27, 2023In recent years, static meshes with texture maps have become one of the most prevalent digital representations of 3D shapes in various applications, such as animation, gaming, medical imaging, and cultural heritage applications. However, little research has been done on the quality assessment of textured meshes, which hinders the development of quality-oriented applications, such as mesh compression and enhancement. In this paper, we create a large-scale textured mesh quality assessment database, namely SJTU-TMQA, which includes 21 reference meshes and 945 distorted samples. The meshes are rendered into processed video sequences and then conduct subjective experiments to obtain mean opinion scores (MOS). The diversity of content and accuracy of MOS has been shown to validate its heterogeneity and reliability. The impact of various types of distortion on human perception is demonstrated. 13 state-of-the-art objective metrics are evaluated on SJTU-TMQA. The results report the highest correlation of around 0.6, indicating the need for more effective objective metrics. The SJTU-TMQA is available at https://ccccby.github.io