 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProGVC: Progressive-based Generative Video Compression via Auto-Regressive Context Modeling
Mar 18, 2026Perceptual video compression leverages generative priors to reconstruct realistic textures and motions at low bitrates. However, existing perceptual codecs often lack native support for variable bitrate and progressive delivery, and their generative modules are weakly coupled with entropy coding, limiting bitrate reduction. Inspired by the next-scale prediction in the Visual Auto-Regressive (VAR) models, we propose ProGVC, a Progressive-based Generative Video Compression framework that unifies progressive transmission, efficient entropy coding, and detail synthesis within a single codec. ProGVC encodes videos into hierarchical multi-scale residual token maps, enabling flexible rate adaptation by transmitting a coarse-to-fine subset of scales in a progressive manner. A Transformer-based multi-scale autoregressive context model estimates token probabilities, utilized both for efficient entropy coding of the transmitted tokens and for predicting truncated fine-scale tokens at the decoder to restore perceptual details. Extensive experiments demonstrate that as a new coding paradigm, ProGVC delivers promising perceptual compression performance at low bitrates while offering practical scalability at the same time.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
Transferable Learned Image Compression-Resistant Adversarial Perturbations
Jan 06, 2024Adversarial attacks can readily disrupt the image classification system, revealing the vulnerability of DNN-based recognition tasks. While existing adversarial perturbations are primarily applied to uncompressed images or compressed images by the traditional image compression method, i.e., JPEG, limited studies have investigated the robustness of models for image classification in the context of DNN-based image compression. With the rapid evolution of advanced image compression, DNN-based learned image compression has emerged as the promising approach for transmitting images in many security-critical applications, such as cloud-based face recognition and autonomous driving, due to its superior performance over traditional compression. Therefore, there is a pressing need to fully investigate the robustness of a classification system post-processed by learned image compression. To bridge this research gap, we explore the adversarial attack on a new pipeline that targets image classification models that utilize learned image compressors as pre-processing modules. Furthermore, to enhance the transferability of perturbations across various quality levels and architectures of learned image compression models, we introduce a saliency score-based sampling method to enable the fast generation of transferable perturbation. Extensive experiments with popular attack methods demonstrate the enhanced transferability of our proposed method when attacking images that have been post-processed with different learned image compression models.
Venn: Resource Management Across Federated Learning Jobs
Dec 13, 2023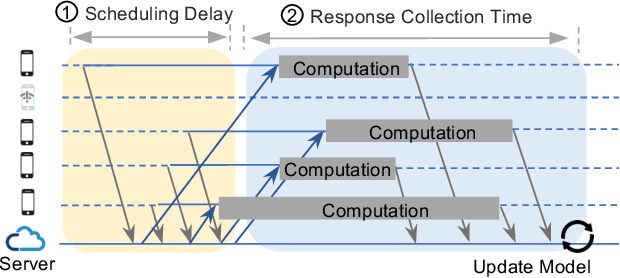
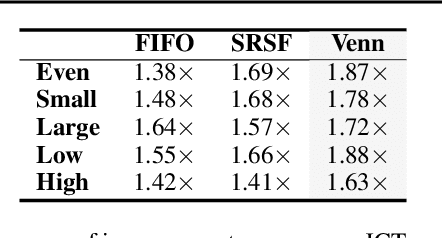
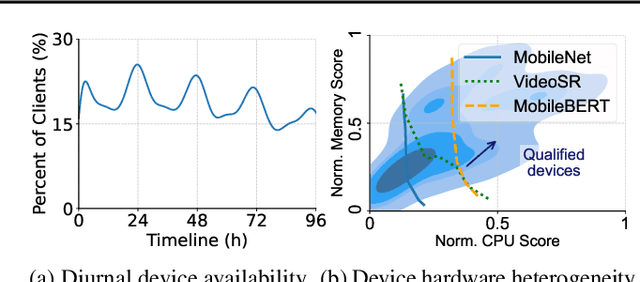
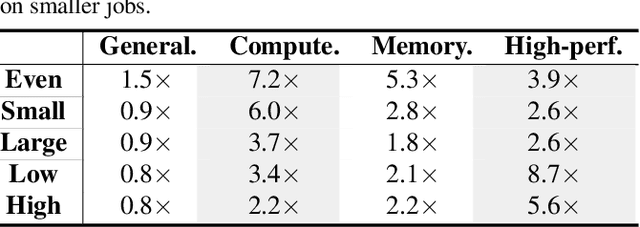
In recent years, federated learning (FL) has emerged as a promising approach for machine learning (ML) and data science across distributed edge devices. With the increasing popularity of FL, resource contention between multiple FL jobs training on the same device population is increasing as well. Scheduling edge resources among multiple FL jobs is different from GPU scheduling for cloud ML because of the ephemeral nature and planetary scale of participating devices as well as the overlapping resource requirements of diverse FL jobs. Existing resource managers for FL jobs opt for random assignment of devices to FL jobs for simplicity and scalability, which leads to poor performance. In this paper, we present Venn, an FL resource manager, that efficiently schedules ephemeral, heterogeneous devices among many FL jobs, with the goal of reducing their average job completion time (JCT). Venn formulates the Intersection Resource Scheduling (IRS) problem to identify complex resource contention among multiple FL jobs. Then, Venn proposes a contention-aware scheduling heuristic to minimize the average scheduling delay. Furthermore, it proposes a resource-aware device-to-job matching heuristic that focuses on optimizing response collection time by mitigating stragglers. Our evaluation shows that, compared to the state-of-the-art FL resource managers, Venn improves the average JCT by up to 1.88X.
Corner-to-Center Long-range Context Model for Efficient Learned Image Compression
Nov 29, 2023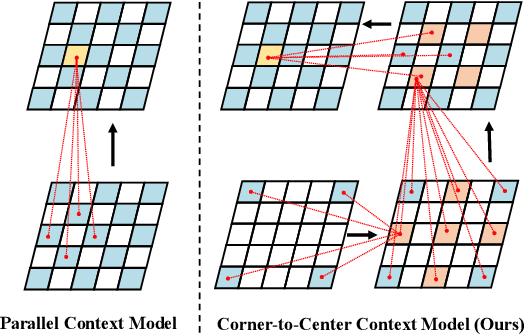
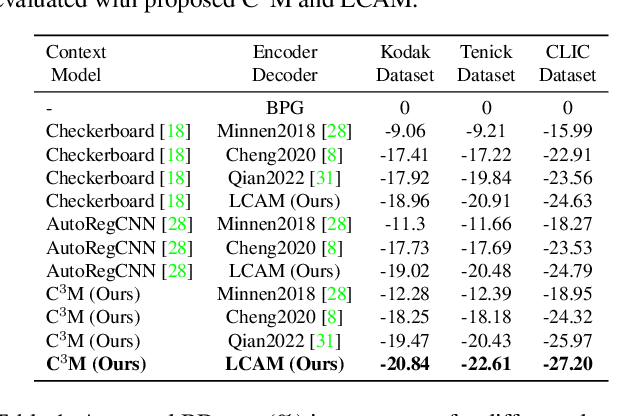
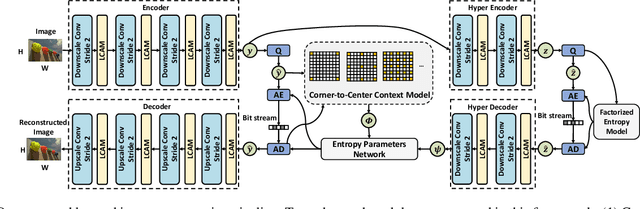

In the framework of learned image compression, the context model plays a pivotal role in capturing the dependencies among latent representations. To reduce the decoding time resulting from the serial autoregressive context model, the parallel context model has been proposed as an alternative that necessitates only two passes during the decoding phase, thus facilitating efficient image compression in real-world scenarios. However, performance degradation occurs due to its incomplete casual context. To tackle this issue, we conduct an in-depth analysis of the performance degradation observed in existing parallel context models, focusing on two aspects: the Quantity and Quality of information utilized for context prediction and decoding. Based on such analysis, we propose the \textbf{Corner-to-Center transformer-based Context Model (C$^3$M)} designed to enhance context and latent predictions and improve rate-distortion performance. Specifically, we leverage the logarithmic-based prediction order to predict more context features from corner to center progressively. In addition, to enlarge the receptive field in the analysis and synthesis transformation, we use the Long-range Crossing Attention Module (LCAM) in the encoder/decoder to capture the long-range semantic information by assigning the different window shapes in different channels. Extensive experimental evaluations show that the proposed method is effective and outperforms the state-of-the-art parallel methods. Finally, according to the subjective analysis, we suggest that improving the detailed representation in transformer-based image compression is a promising direction to be explored.
Reconstruction Distortion of Learned Image Compression with Imperceptible Perturbations
Jun 01, 2023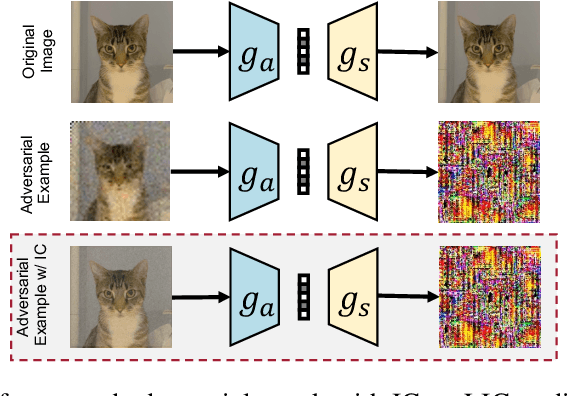
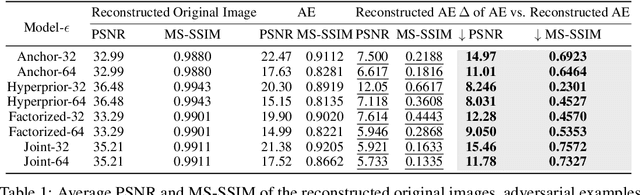

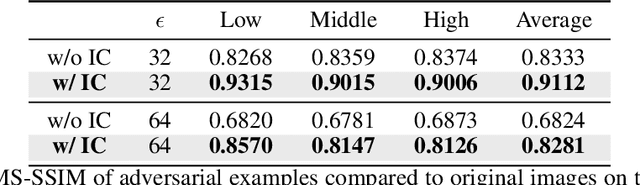
Learned Image Compression (LIC) has recently become the trending technique for image transmission due to its notable performance. Despite its popularity, the robustness of LIC with respect to the quality of image reconstruction remains under-explored. In this paper, we introduce an imperceptible attack approach designed to effectively degrade the reconstruction quality of LIC, resulting in the reconstructed image being severely disrupted by noise where any object in the reconstructed images is virtually impossible. More specifically, we generate adversarial examples by introducing a Frobenius norm-based loss function to maximize the discrepancy between original images and reconstructed adversarial examples. Further, leveraging the insensitivity of high-frequency components to human vision, we introduce Imperceptibility Constraint (IC) to ensure that the perturbations remain inconspicuous. Experiments conducted on the Kodak dataset using various LIC models demonstrate effectiveness. In addition, we provide several findings and suggestions for designing future defenses.
BigDL 2.0: Seamless Scaling of AI Pipelines from Laptops to Distributed Cluster
Apr 03, 2022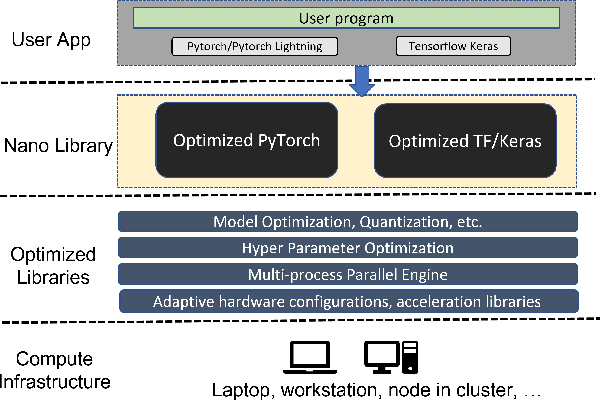



Most AI projects start with a Python notebook running on a single laptop; however, one usually needs to go through a mountain of pains to scale it to handle larger dataset (for both experimentation and production deployment). These usually entail many manual and error-prone steps for the data scientists to fully take advantage of the available hardware resources (e.g., SIMD instructions, multi-processing, quantization, memory allocation optimization, data partitioning, distributed computing, etc.). To address this challenge, we have open sourced BigDL 2.0 at https://github.com/intel-analytics/BigDL/ under Apache 2.0 license (combining the original BigDL and Analytics Zoo projects); using BigDL 2.0, users can simply build conventional Python notebooks on their laptops (with possible AutoML support), which can then be transparently accelerated on a single node (with up-to 9.6x speedup in our experiments), and seamlessly scaled out to a large cluster (across several hundreds servers in real-world use cases). BigDL 2.0 has already been adopted by many real-world users (such as Mastercard, Burger King, Inspur, etc.) in production.
A Graph Attention Based Approach for Trajectory Prediction in Multi-agent Sports Games
Dec 18, 2020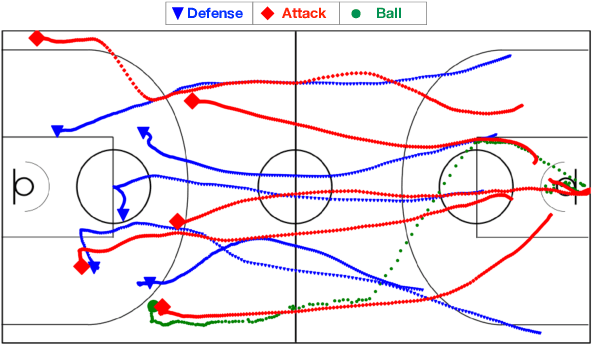
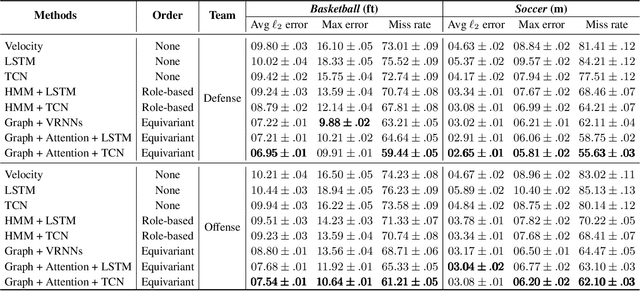

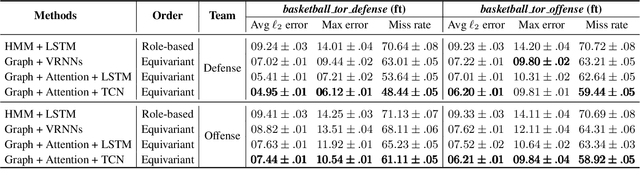
This work investigates the problem of multi-agents trajectory prediction. Prior approaches lack of capability of capturing fine-grained dependencies among coordinated agents. In this paper, we propose a spatial-temporal trajectory prediction approach that is able to learn the strategy of a team with multiple coordinated agents. In particular, we use graph-based attention model to learn the dependency of the agents. In addition, instead of utilizing the recurrent networks (e.g., VRNN, LSTM), our method uses a Temporal Convolutional Network (TCN) as the sequential model to support long effective history and provide important features such as parallelism and stable gradients. We demonstrate the validation and effectiveness of our approach on two different sports game datasets: basketball and soccer datasets. The result shows that compared to related approaches, our model that infers the dependency of players yields substantially improved performance. Code is available at https://github.com/iHeartGraph/predict
BigDL: A Distributed Deep Learning Framework for Big Data
Jun 25, 2018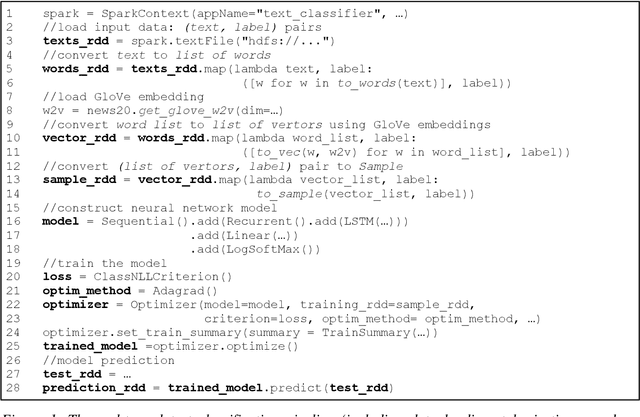
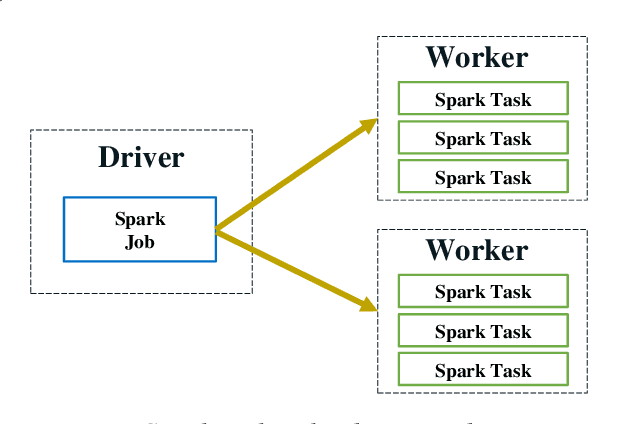

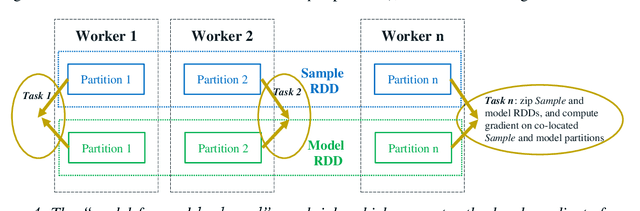
In this paper, we present BigDL, a distributed deep learning framework for Big Data platforms and workflows. It is implemented on top of Apache Spark, and allows users to write their deep learning applications as standard Spark programs (running directly on large-scale big data clusters in a distributed fashion). It provides an expressive, "data-analytics integrated" deep learning programming model, so that users can easily build the end-to-end analytics + AI pipelines under a unified programming paradigm; by implementing an AllReduce like operation using existing primitives in Spark (e.g., shuffle, broadcast, and in-memory data persistence), it also provides a highly efficient "parameter server" style architecture, so as to achieve highly scalable, data-parallel distributed training. Since its initial open source release, BigDL users have built many analytics and deep learning applications (e.g., object detection, sequence-to-sequence generation, visual similarity, neural recommendations, fraud detection, etc.) on Spark.