 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEAM: A Multimodal Imaging Dataset and HAMM for Glaucoma Classification
Mar 13, 2026We propose glaucoma lesion evaluation and analysis with multimodal imaging (GLEAM), the first publicly available tri-modal glaucoma dataset comprising scanning laser ophthalmoscopy fundus images, circumpapillary OCT images, and visual field pattern deviation maps, annotated with four disease stages, enabling effective exploitation of multimodal complementary information and facilitating accurate diagnosis and treatment across disease stages. To effectively integrate cross-modal information, we propose hierarchical attentive masked modeling (HAMM) for multimodal glaucoma classification. Our framework employs hierarchical attentive encoders and light decoders to focus cross-modal representation learning on the encoder.
FNBT: Full Negation Belief Transformation for Open-World Information Fusion Based on Dempster-Shafer Theory of Evidence
Aug 11, 2025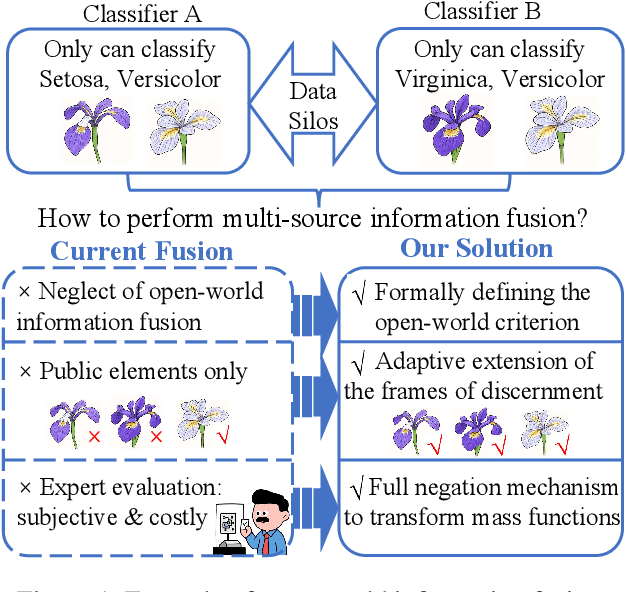



The Dempster-Shafer theory of evidence has been widely applied in the field of information fusion under uncertainty. Most existing research focuses on combining evidence within the same frame of discernment. However, in real-world scenarios, trained algorithms or data often originate from different regions or organizations, where data silos are prevalent. As a result, using different data sources or models to generate basic probability assignments may lead to heterogeneous frames, for which traditional fusion methods often yield unsatisfactory results. To address this challenge, this study proposes an open-world information fusion method, termed Full Negation Belief Transformation (FNBT), based on the Dempster-Shafer theory. More specially, a criterion is introduced to determine whether a given fusion task belongs to the open-world setting. Then, by extending the frames, the method can accommodate elements from heterogeneous frames. Finally, a full negation mechanism is employed to transform the mass functions, so that existing combination rules can be applied to the transformed mass functions for such information fusion. Theoretically, the proposed method satisfies three desirable properties, which are formally proven: mass function invariance, heritability, and essential conflict elimination. Empirically, FNBT demonstrates superior performance in pattern classification tasks on real-world datasets and successfully resolves Zadeh's counterexample, thereby validating its practical effectiveness.
Visual-Geometric Collaborative Guidance for Affordance Learning
Oct 15, 2024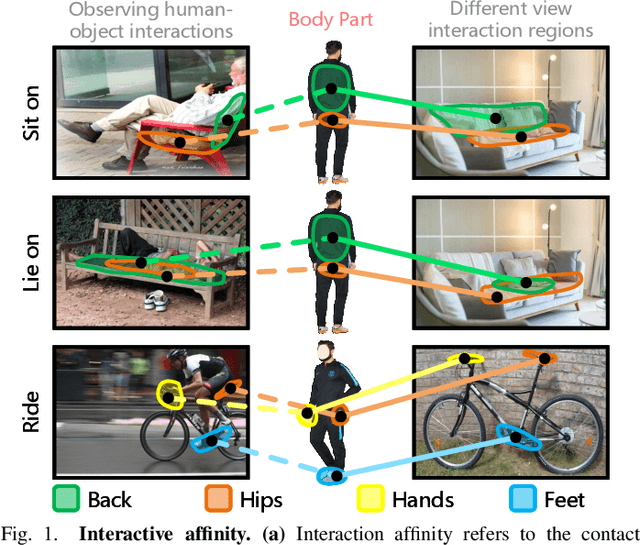


Perceiving potential ``action possibilities'' (\ie, affordance) regions of images and learning interactive functionalities of objects from human demonstration is a challenging task due to the diversity of human-object interactions. Prevailing affordance learning algorithms often adopt the label assignment paradigm and presume that there is a unique relationship between functional region and affordance label, yielding poor performance when adapting to unseen environments with large appearance variations. In this paper, we propose to leverage interactive affinity for affordance learning, \ie extracting interactive affinity from human-object interaction and transferring it to non-interactive objects. Interactive affinity, which represents the contacts between different parts of the human body and local regions of the target object, can provide inherent cues of interconnectivity between humans and objects, thereby reducing the ambiguity of the perceived action possibilities. To this end, we propose a visual-geometric collaborative guided affordance learning network that incorporates visual and geometric cues to excavate interactive affinity from human-object interactions jointly. Besides, a contact-driven affordance learning (CAL) dataset is constructed by collecting and labeling over 55,047 images. Experimental results demonstrate that our method outperforms the representative models regarding objective metrics and visual quality. Project: \href{https://github.com/lhc1224/VCR-Net}{github.com/lhc1224/VCR-Net}.
BigDL 2.0: Seamless Scaling of AI Pipelines from Laptops to Distributed Cluster
Apr 03, 2022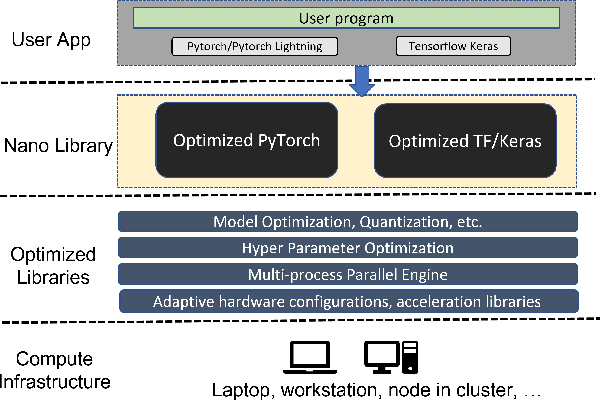



Most AI projects start with a Python notebook running on a single laptop; however, one usually needs to go through a mountain of pains to scale it to handle larger dataset (for both experimentation and production deployment). These usually entail many manual and error-prone steps for the data scientists to fully take advantage of the available hardware resources (e.g., SIMD instructions, multi-processing, quantization, memory allocation optimization, data partitioning, distributed computing, etc.). To address this challenge, we have open sourced BigDL 2.0 at https://github.com/intel-analytics/BigDL/ under Apache 2.0 license (combining the original BigDL and Analytics Zoo projects); using BigDL 2.0, users can simply build conventional Python notebooks on their laptops (with possible AutoML support), which can then be transparently accelerated on a single node (with up-to 9.6x speedup in our experiments), and seamlessly scaled out to a large cluster (across several hundreds servers in real-world use cases). BigDL 2.0 has already been adopted by many real-world users (such as Mastercard, Burger King, Inspur, etc.) in production.
Context-Aware Drive-thru Recommendation Service at Fast Food Restaurants
Oct 13, 2020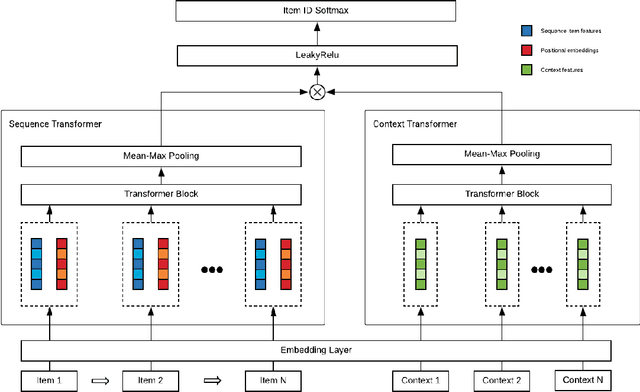

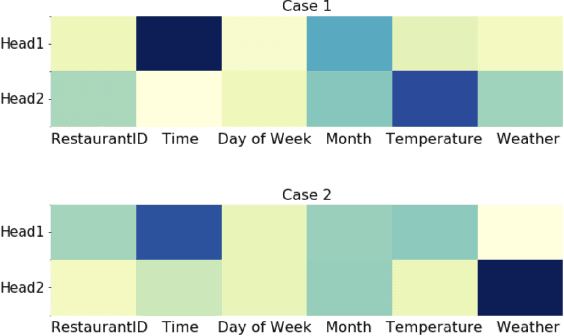
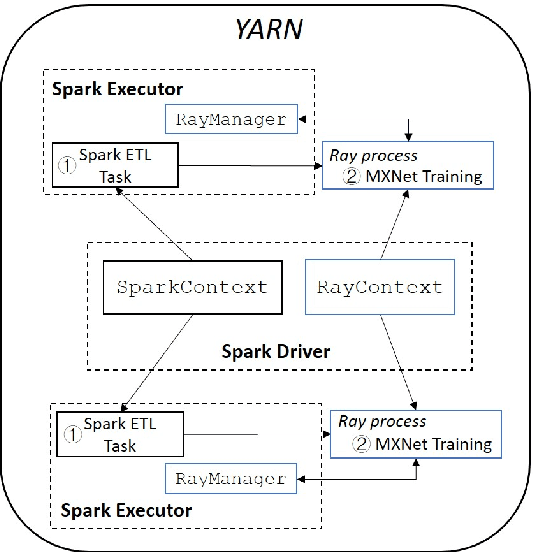
Drive-thru is a popular sales channel in the fast food industry where consumers can make food purchases without leaving their cars. Drive-thru recommendation systems allow restaurants to display food recommendations on the digital menu board as guests are making their orders. Popular recommendation models in eCommerce scenarios rely on user attributes (such as user profiles or purchase history) to generate recommendations, while such information is hard to obtain in the drive-thru use case. Thus, in this paper, we propose a new recommendation model Transformer Cross Transformer (TxT), which exploits the guest order behavior and contextual features (such as location, time, and weather) using Transformer encoders for drive-thru recommendations. Empirical results show that our TxT model achieves superior results in Burger King's drive-thru production environment compared with existing recommendation solutions. In addition, we implement a unified system to run end-to-end big data analytics and deep learning workloads on the same cluster. We find that in practice, maintaining a single big data cluster for the entire pipeline is more efficient and cost-saving. Our recommendation system is not only beneficial for drive-thru scenarios, and it can also be generalized to other customer interaction channels.
BigDL: A Distributed Deep Learning Framework for Big Data
Jun 25, 2018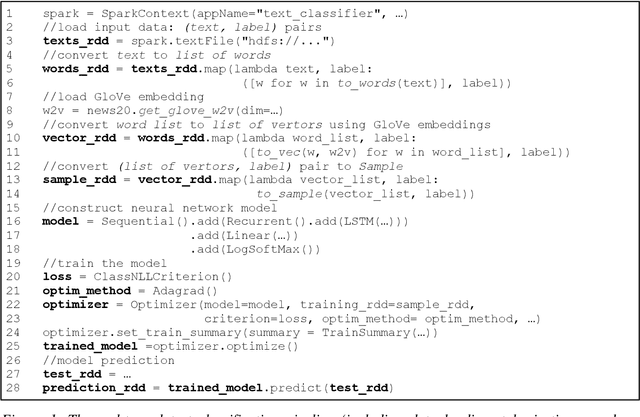
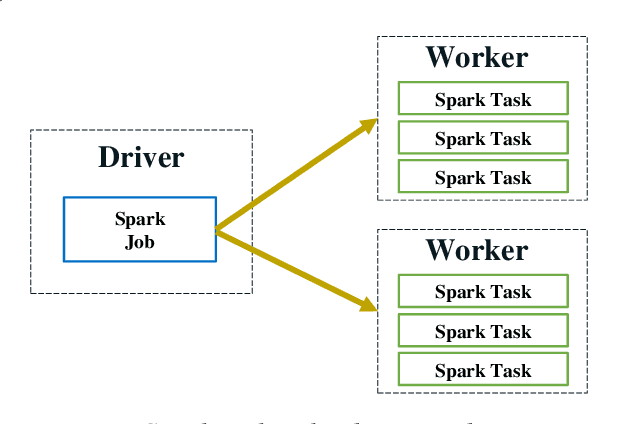

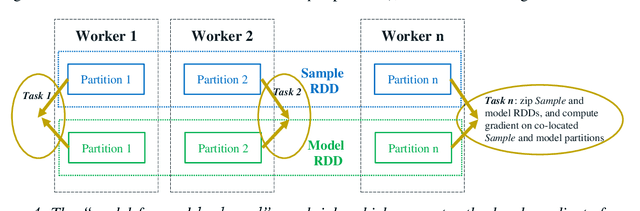
In this paper, we present BigDL, a distributed deep learning framework for Big Data platforms and workflows. It is implemented on top of Apache Spark, and allows users to write their deep learning applications as standard Spark programs (running directly on large-scale big data clusters in a distributed fashion). It provides an expressive, "data-analytics integrated" deep learning programming model, so that users can easily build the end-to-end analytics + AI pipelines under a unified programming paradigm; by implementing an AllReduce like operation using existing primitives in Spark (e.g., shuffle, broadcast, and in-memory data persistence), it also provides a highly efficient "parameter server" style architecture, so as to achieve highly scalable, data-parallel distributed training. Since its initial open source release, BigDL users have built many analytics and deep learning applications (e.g., object detection, sequence-to-sequence generation, visual similarity, neural recommendations, fraud detection, etc.) on Spark.