 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based Motion & Appearance Fusion for 6D Object Pose Tracking
Mar 09, 2026Object pose tracking is a fundamental and essential task for robotics to perform tasks in the home and industrial settings. The most commonly used sensors to do so are RGB-D cameras, which can hit limitations in highly dynamic environments due to motion blur and frame-rate constraints. Event cameras have remarkable features such as high temporal resolution and low latency, which make them a potentially ideal vision sensors for object pose tracking at high speed. Even so, there are still only few works on 6D pose tracking with event cameras. In this work, we take advantage of the high temporal resolution and propose a method that uses both a propagation step fused with a pose correction strategy. Specifically, we use 6D object velocity obtained from event-based optical flow for pose propagation, after which, a template-based local pose correction module is utilized for pose correction. Our learning-free method has comparable performance to the state-of-the-art algorithms, and in some cases out performs them for fast-moving objects. The results indicate the potential for using event cameras in highly-dynamic scenarios where the use of deep network approaches are limited by low update rates.
6-DoF Object Tracking with Event-based Optical Flow and Frames
Aug 20, 2025Tracking the position and orientation of objects in space (i.e., in 6-DoF) in real time is a fundamental problem in robotics for environment interaction. It becomes more challenging when objects move at high-speed due to frame rate limitations in conventional cameras and motion blur. Event cameras are characterized by high temporal resolution, low latency and high dynamic range, that can potentially overcome the impacts of motion blur. Traditional RGB cameras provide rich visual information that is more suitable for the challenging task of single-shot object pose estimation. In this work, we propose using event-based optical flow combined with an RGB based global object pose estimator for 6-DoF pose tracking of objects at high-speed, exploiting the core advantages of both types of vision sensors. Specifically, we propose an event-based optical flow algorithm for object motion measurement to implement an object 6-DoF velocity tracker. By integrating the tracked object 6-DoF velocity with low frequency estimated pose from the global pose estimator, the method can track pose when objects move at high-speed. The proposed algorithm is tested and validated on both synthetic and real world data, demonstrating its effectiveness, especially in high-speed motion scenarios.
Object Concepts Emerge from Motion
May 27, 2025Object concepts play a foundational role in human visual cognition, enabling perception, memory, and interaction in the physical world. Inspired by findings in developmental neuroscience - where infants are shown to acquire object understanding through observation of motion - we propose a biologically inspired framework for learning object-centric visual representations in an unsupervised manner. Our key insight is that motion boundary serves as a strong signal for object-level grouping, which can be used to derive pseudo instance supervision from raw videos. Concretely, we generate motion-based instance masks using off-the-shelf optical flow and clustering algorithms, and use them to train visual encoders via contrastive learning. Our framework is fully label-free and does not rely on camera calibration, making it scalable to large-scale unstructured video data. We evaluate our approach on three downstream tasks spanning both low-level (monocular depth estimation) and high-level (3D object detection and occupancy prediction) vision. Our models outperform previous supervised and self-supervised baselines and demonstrate strong generalization to unseen scenes. These results suggest that motion-induced object representations offer a compelling alternative to existing vision foundation models, capturing a crucial but overlooked level of abstraction: the visual instance. The corresponding code will be released upon paper acceptance.
Driving with Context: Online Map Matching for Complex Roads Using Lane Markings and Scenario Recognition
May 08, 2025



Accurate online map matching is fundamental to vehicle navigation and the activation of intelligent driving functions. Current online map matching methods are prone to errors in complex road networks, especially in multilevel road area. To address this challenge, we propose an online Standard Definition (SD) map matching method by constructing a Hidden Markov Model (HMM) with multiple probability factors. Our proposed method can achieve accurate map matching even in complex road networks by carefully leveraging lane markings and scenario recognition in the designing of the probability factors. First, the lane markings are generated by a multi-lane tracking method and associated with the SD map using HMM to build an enriched SD map. In areas covered by the enriched SD map, the vehicle can re-localize itself by performing Iterative Closest Point (ICP) registration for the lane markings. Then, the probability factor accounting for the lane marking detection can be obtained using the association probability between adjacent lanes and roads. Second, the driving scenario recognition model is applied to generate the emission probability factor of scenario recognition, which improves the performance of map matching on elevated roads and ordinary urban roads underneath them. We validate our method through extensive road tests in Europe and China, and the experimental results show that our proposed method effectively improves the online map matching accuracy as compared to other existing methods, especially in multilevel road area. Specifically, the experiments show that our proposed method achieves $F_1$ scores of 98.04% and 94.60% on the Zenseact Open Dataset and test data of multilevel road areas in Shanghai respectively, significantly outperforming benchmark methods. The implementation is available at https://github.com/TRV-Lab/LMSR-OMM.
Lightning NeRF: Efficient Hybrid Scene Representation for Autonomous Driving
Mar 09, 2024



Recent studies have highlighted the promising application of NeRF in autonomous driving contexts. However, the complexity of outdoor environments, combined with the restricted viewpoints in driving scenarios, complicates the task of precisely reconstructing scene geometry. Such challenges often lead to diminished quality in reconstructions and extended durations for both training and rendering. To tackle these challenges, we present Lightning NeRF. It uses an efficient hybrid scene representation that effectively utilizes the geometry prior from LiDAR in autonomous driving scenarios. Lightning NeRF significantly improves the novel view synthesis performance of NeRF and reduces computational overheads. Through evaluations on real-world datasets, such as KITTI-360, Argoverse2, and our private dataset, we demonstrate that our approach not only exceeds the current state-of-the-art in novel view synthesis quality but also achieves a five-fold increase in training speed and a ten-fold improvement in rendering speed. Codes are available at https://github.com/VISION-SJTU/Lightning-NeRF .
EAST: Environment Aware Safe Tracking using Planning and Control Co-Design
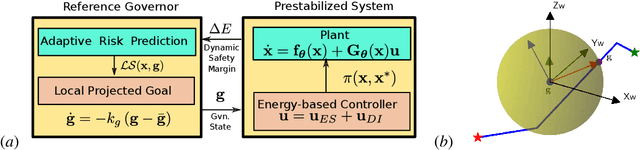
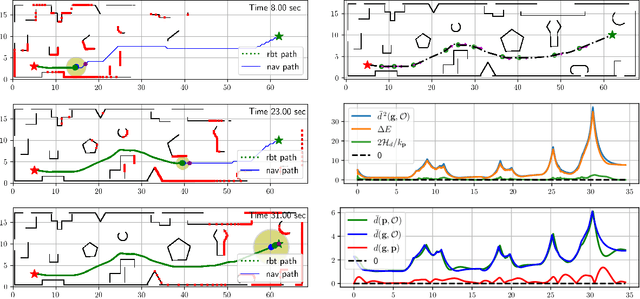
Oct 02, 2023This paper considers the problem of autonomous robot navigation in unknown environments with moving obstacles. We propose a new method that systematically puts planning, motion prediction and safety metric design together to achieve environmental adaptive and safe navigation. This algorithm balances optimality in travel distance and safety with respect to passing clearance. Robot adapts progress speed adaptively according to the sensed environment, being fast in wide open areas and slow down in narrow passages and taking necessary maneuvers to avoid dangerous incoming obstacles. In our method, directional distance measure, conic-shape motion prediction and custom costmap are integrated properly to evaluate system risk accurately with respect to local geometry of surrounding environments. Using such risk estimation, reference governor technique and control barrier function are worked together to enable adaptive and safe path tracking in dynamical environments. We validate our algorithm extensively both in simulation and challenging real-world environments.
Deep Planar Parallax for Monocular Depth Estimation
Jan 09, 2023

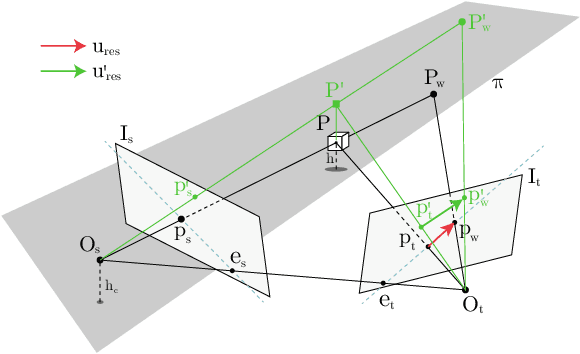

Depth estimation is a fundamental problem in the perception system of autonomous driving scenes. Although autonomous driving is challenging, much prior knowledge can still be utilized, by which the sophistication of the problem can be effectively restricted. Some previous works introduce the road plane prior to the depth estimation problem according to the Planar Parallax Geometry. However, we find that their usages are not effective, leaving the network cannot learn the geometric information. To this end, we analyze this problem in detail and reveal that explicit warping of consecutive frames and flow pre-training can effectively bring the geometric prior into learning. Furthermore, we propose Planar Position Embedding to deal with the intrinsic weakness of plane parallax geometry. Comprehensive experimental results on autonomous driving datasets like KITTI and Waymo Open Dataset (WOD) demonstrate that our Planar Parallax Network(PPNet) dramatically outperforms existing learning-based methods.
Robust and Safe Autonomous Navigation for Systems with Learned SE(3) Hamiltonian Dynamics
Jul 22, 2022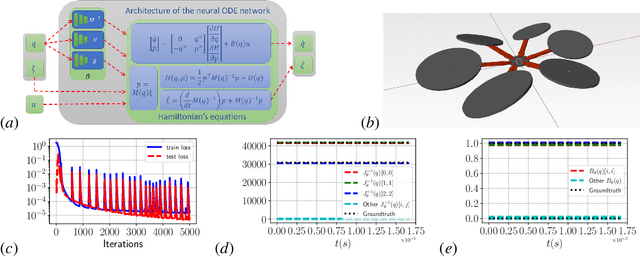
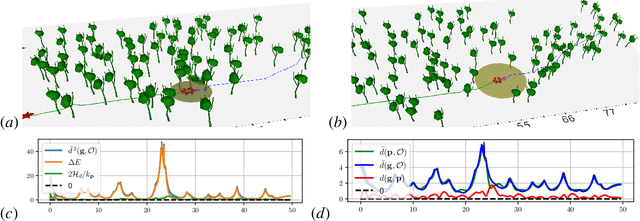
Stability and safety are critical properties for successful deployment of automatic control systems. As a motivating example, consider autonomous mobile robot navigation in a complex environment. A control design that generalizes to different operational conditions requires a model of the system dynamics, robustness to modeling errors, and satisfaction of safety \NEWZL{constraints}, such as collision avoidance. This paper develops a neural ordinary differential equation network to learn the dynamics of a Hamiltonian system from trajectory data. The learned Hamiltonian model is used to synthesize an energy-shaping passivity-based controller and analyze its \emph{robustness} to uncertainty in the learned model and its \emph{safety} with respect to constraints imposed by the environment. Given a desired reference path for the system, we extend our design using a virtual reference governor to achieve tracking control. The governor state serves as a regulation point that moves along the reference path adaptively, balancing the system energy level, model uncertainty bounds, and distance to safety violation to guarantee robustness and safety. Our Hamiltonian dynamics learning and tracking control techniques are demonstrated on \Revised{simulated hexarotor and quadrotor robots} navigating in cluttered 3D environments.
Prediction of GPU Failures Under Deep Learning Workloads
Jan 27, 2022
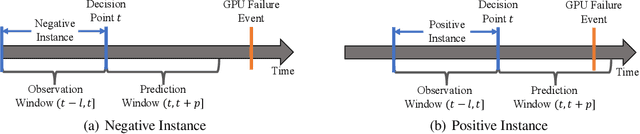
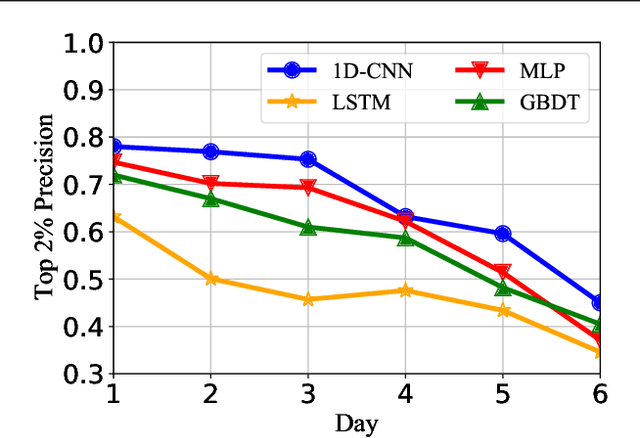

Graphics processing units (GPUs) are the de facto standard for processing deep learning (DL) tasks. Meanwhile, GPU failures, which are inevitable, cause severe consequences in DL tasks: they disrupt distributed trainings, crash inference services, and result in service level agreement violations. To mitigate the problem caused by GPU failures, we propose to predict failures by using ML models. This paper is the first to study prediction models of GPU failures under large-scale production deep learning workloads. As a starting point, we evaluate classic prediction models and observe that predictions of these models are both inaccurate and unstable. To improve the precision and stability of predictions, we propose several techniques, including parallel and cascade model-ensemble mechanisms and a sliding training method. We evaluate the performances of our various techniques on a four-month production dataset including 350 million entries. The results show that our proposed techniques improve the prediction precision from 46.3\% to 84.0\%.
Safe Autonomous Navigation for Systems with Learned SE(3) Hamiltonian Dynamics
Dec 09, 2021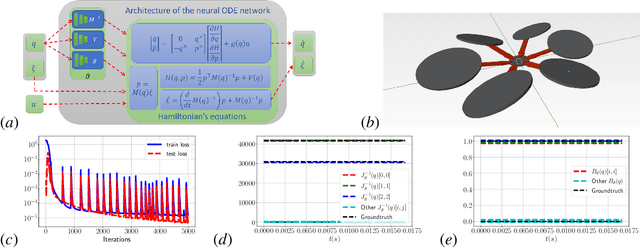
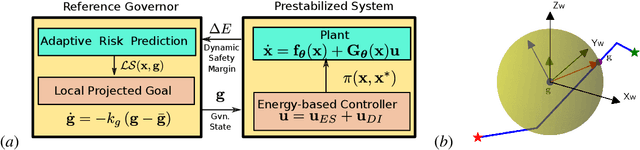
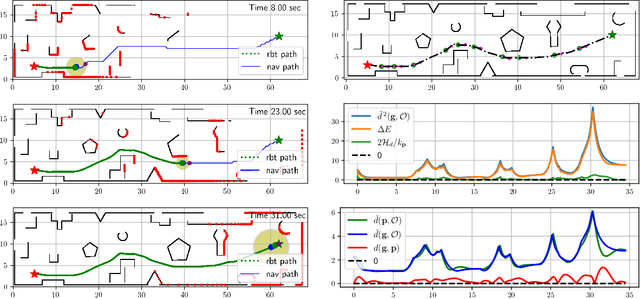
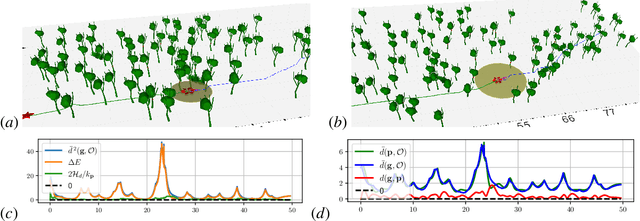
Safe autonomous navigation in unknown environments is an important problem for ground, aerial, and underwater robots. This paper proposes techniques to learn the dynamics models of a mobile robot from trajectory data and synthesize a tracking controller with safety and stability guarantees. The state of a mobile robot usually contains its position, orientation, and generalized velocity and satisfies Hamilton's equations of motion. Instead of a hand-derived dynamics model, we use a dataset of state-control trajectories to train a translation-equivariant nonlinear Hamiltonian model represented as a neural ordinary differential equation (ODE) network. The learned Hamiltonian model is used to synthesize an energy-shaping passivity-based controller and derive conditions which guarantee safe regulation to a desired reference pose. Finally, we enable adaptive tracking of a desired path, subject to safety constraints obtained from obstacle distance measurements. The trade-off between the system's energy level and the distance to safety constraint violation is used to adaptively govern the reference pose along the desired path. Our safe adaptive controller is demonstrated on a simulated hexarotor robot navigating in unknown complex environments.