 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedPRO: A Generic Profiling and Optimization System for Expediting Distributed DNN Training
May 18, 2022



Distributed training using multiple devices (e.g., GPUs) has been widely adopted for learning DNN models over large datasets. However, the performance of large-scale distributed training tends to be far from linear speed-up in practice. Given the complexity of distributed systems, it is challenging to identify the root cause(s) of inefficiency and exercise effective performance optimizations when unexpected low training speed occurs. To date, there exists no software tool which diagnoses performance issues and helps expedite distributed DNN training, while the training can be run using different deep learning frameworks. This paper proposes dPRO, a toolkit that includes: (1) an efficient profiler that collects runtime traces of distributed DNN training across multiple frameworks, especially fine-grained communication traces, and constructs global data flow graphs including detailed communication operations for accurate replay; (2) an optimizer that effectively identifies performance bottlenecks and explores optimization strategies (from computation, communication, and memory aspects) for training acceleration. We implement dPRO on multiple deep learning frameworks (TensorFlow, MXNet) and representative communication schemes (AllReduce and Parameter Server). Extensive experiments show that dPRO predicts the performance of distributed training in various settings with < 5% errors in most cases and finds optimization strategies with up to 3.48x speed-up over the baselines.
Aryl: An Elastic Cluster Scheduler for Deep Learning
Feb 16, 2022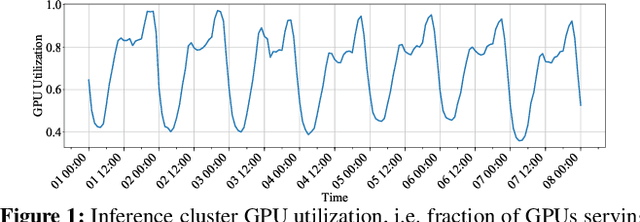
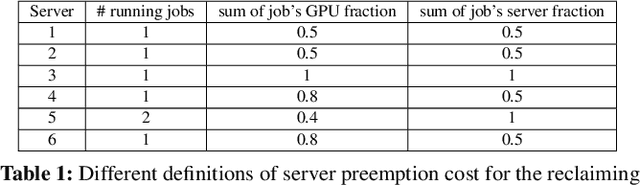
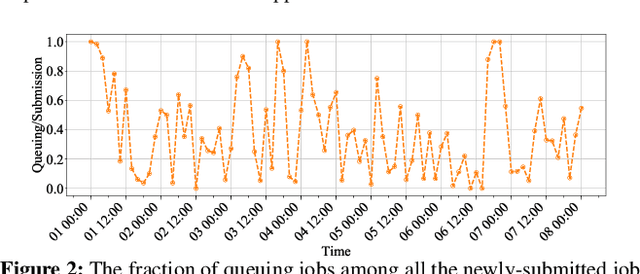
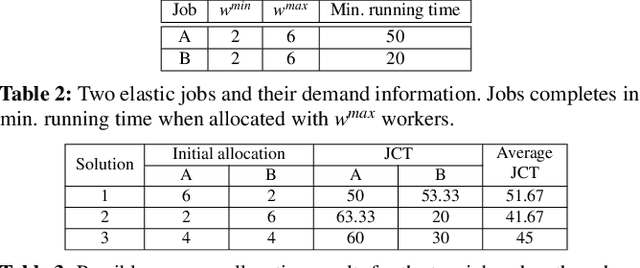
Companies build separate training and inference GPU clusters for deep learning, and use separate schedulers to manage them. This leads to problems for both training and inference: inference clusters have low GPU utilization when the traffic load is low; training jobs often experience long queueing time due to lack of resources. We introduce Aryl, a new cluster scheduler to address these problems. Aryl introduces capacity loaning to loan idle inference GPU servers for training jobs. It further exploits elastic scaling that scales a training job's GPU allocation to better utilize loaned resources. Capacity loaning and elastic scaling create new challenges to cluster management. When the loaned servers need to be returned, we need to minimize the number of job preemptions; when more GPUs become available, we need to allocate them to elastic jobs and minimize the job completion time (JCT). Aryl addresses these combinatorial problems using principled heuristics. It introduces the notion of server preemption cost which it greedily reduces during server reclaiming. It further relies on the JCT reduction value defined for each additional worker for an elastic job to solve the scheduling problem as a multiple-choice knapsack problem. Prototype implementation on a 64-GPU testbed and large-scale simulation with 15-day traces of over 50,000 production jobs show that Aryl brings 1.53x and 1.50x reductions in average queuing time and JCT, and improves cluster usage by up to 26.9% over the cluster scheduler without capacity loaning or elastic scaling.
Prediction of GPU Failures Under Deep Learning Workloads
Jan 27, 2022
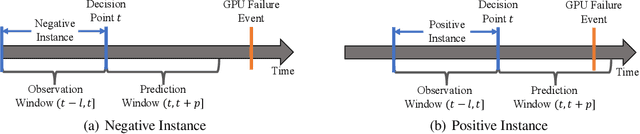
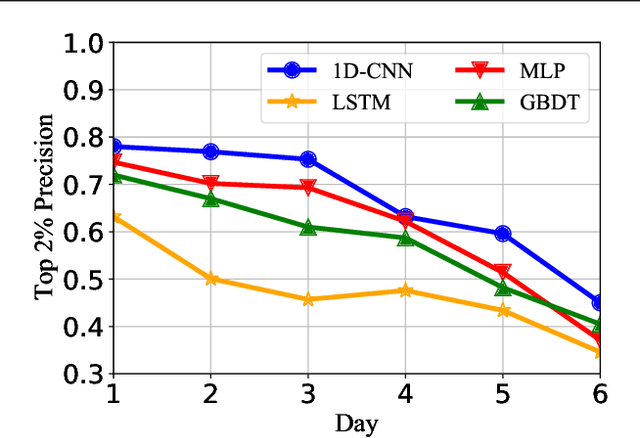

Graphics processing units (GPUs) are the de facto standard for processing deep learning (DL) tasks. Meanwhile, GPU failures, which are inevitable, cause severe consequences in DL tasks: they disrupt distributed trainings, crash inference services, and result in service level agreement violations. To mitigate the problem caused by GPU failures, we propose to predict failures by using ML models. This paper is the first to study prediction models of GPU failures under large-scale production deep learning workloads. As a starting point, we evaluate classic prediction models and observe that predictions of these models are both inaccurate and unstable. To improve the precision and stability of predictions, we propose several techniques, including parallel and cascade model-ensemble mechanisms and a sliding training method. We evaluate the performances of our various techniques on a four-month production dataset including 350 million entries. The results show that our proposed techniques improve the prediction precision from 46.3\% to 84.0\%.
BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
Dec 16, 2021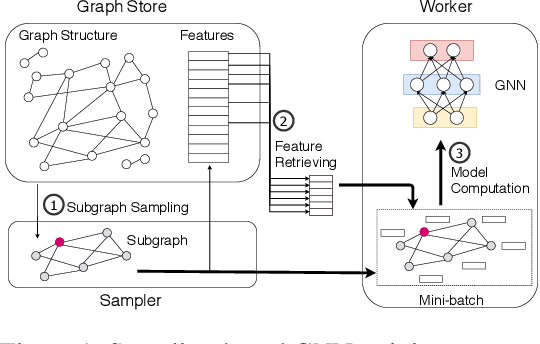
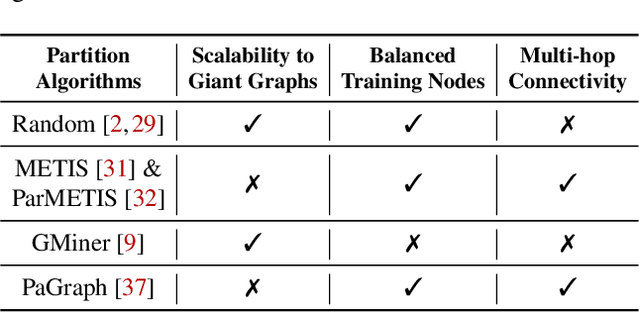
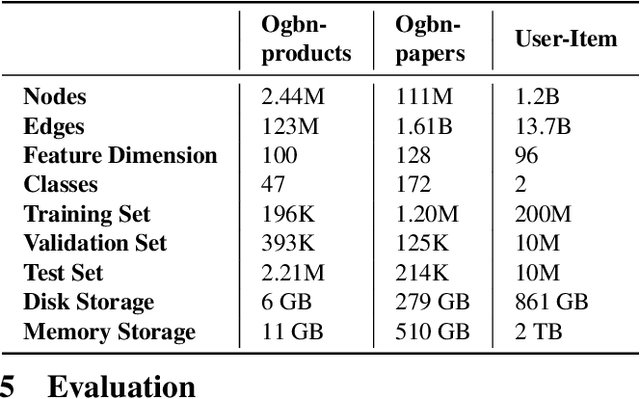
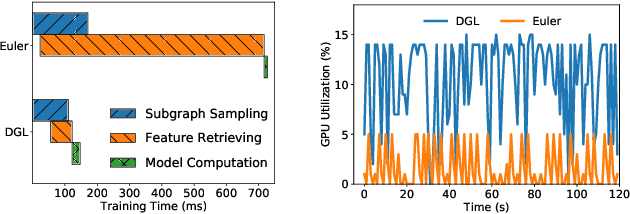
Graph neural networks (GNNs) have extended the success of deep neural networks (DNNs) to non-Euclidean graph data, achieving ground-breaking performance on various tasks such as node classification and graph property prediction. Nonetheless, existing systems are inefficient to train large graphs with billions of nodes and edges with GPUs. The main bottlenecks are the process of preparing data for GPUs - subgraph sampling and feature retrieving. This paper proposes BGL, a distributed GNN training system designed to address the bottlenecks with a few key ideas. First, we propose a dynamic cache engine to minimize feature retrieving traffic. By a co-design of caching policy and the order of sampling, we find a sweet spot of low overhead and high cache hit ratio. Second, we improve the graph partition algorithm to reduce cross-partition communication during subgraph sampling. Finally, careful resource isolation reduces contention between different data preprocessing stages. Extensive experiments on various GNN models and large graph datasets show that BGL significantly outperforms existing GNN training systems by 20.68x on average.
Serving DNN Models with Multi-Instance GPUs: A Case of the Reconfigurable Machine Scheduling Problem
Sep 18, 2021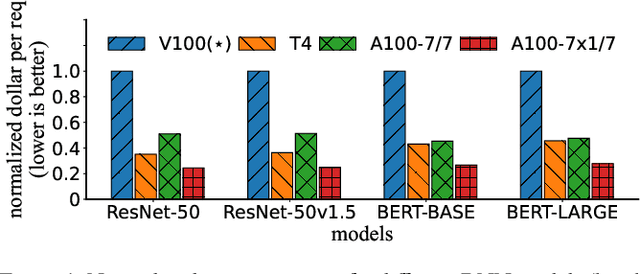
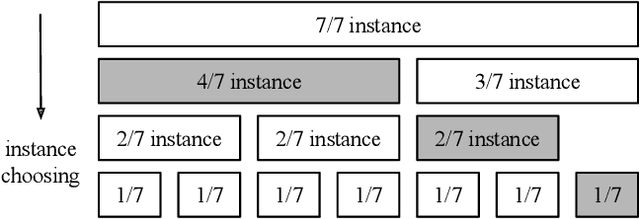
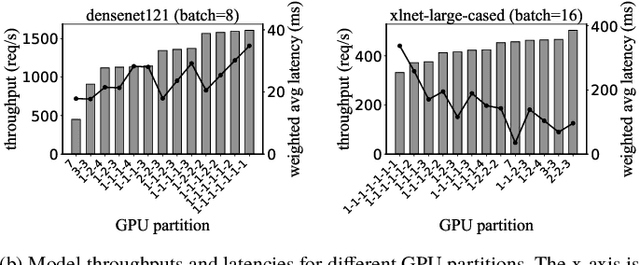
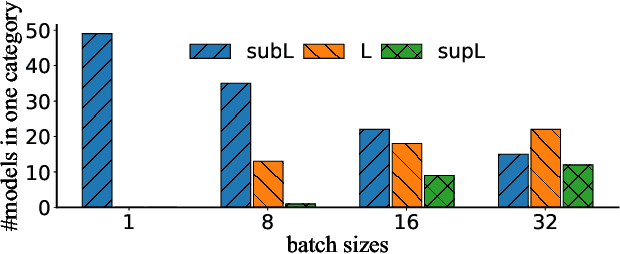
Multi-Instance GPU (MIG) is a new feature introduced by NVIDIA A100 GPUs that partitions one physical GPU into multiple GPU instances. With MIG, A100 can be the most cost-efficient GPU ever for serving Deep Neural Networks (DNNs). However, discovering the most efficient GPU partitions is challenging. The underlying problem is NP-hard; moreover, it is a new abstract problem, which we define as the Reconfigurable Machine Scheduling Problem (RMS). This paper studies serving DNNs with MIG, a new case of RMS. We further propose a solution, MIG-serving. MIG- serving is an algorithm pipeline that blends a variety of newly designed algorithms and customized classic algorithms, including a heuristic greedy algorithm, Genetic Algorithm (GA), and Monte Carlo Tree Search algorithm (MCTS). We implement MIG-serving on Kubernetes. Our experiments show that compared to using A100 as-is, MIG-serving can save up to 40% of GPUs while providing the same throughput.
AutoLRS: Automatic Learning-Rate Schedule by Bayesian Optimization on the Fly
May 22, 2021
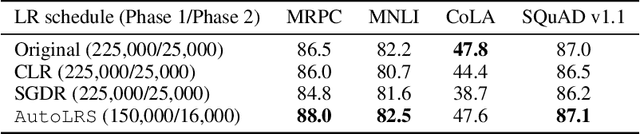
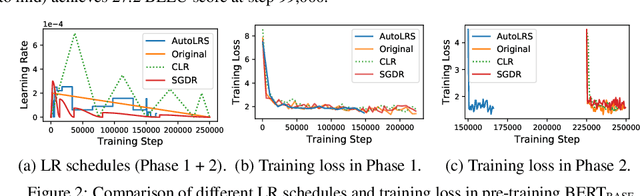

The learning rate (LR) schedule is one of the most important hyper-parameters needing careful tuning in training DNNs. However, it is also one of the least automated parts of machine learning systems and usually costs significant manual effort and computing. Though there are pre-defined LR schedules and optimizers with adaptive LR, they introduce new hyperparameters that need to be tuned separately for different tasks/datasets. In this paper, we consider the question: Can we automatically tune the LR over the course of training without human involvement? We propose an efficient method, AutoLRS, which automatically optimizes the LR for each training stage by modeling training dynamics. AutoLRS aims to find an LR applied to every $\tau$ steps that minimizes the resulted validation loss. We solve this black-box optimization on the fly by Bayesian optimization (BO). However, collecting training instances for BO requires a system to evaluate each LR queried by BO's acquisition function for $\tau$ steps, which is prohibitively expensive in practice. Instead, we apply each candidate LR for only $\tau'\ll\tau$ steps and train an exponential model to predict the validation loss after $\tau$ steps. This mutual-training process between BO and the loss-prediction model allows us to limit the training steps invested in the BO search. We demonstrate the advantages and the generality of AutoLRS through extensive experiments of training DNNs for tasks from diverse domains using different optimizers. The LR schedules auto-generated by AutoLRS lead to a speedup of $1.22\times$, $1.43\times$, and $1.5\times$ when training ResNet-50, Transformer, and BERT, respectively, compared to the LR schedules in their original papers, and an average speedup of $1.31\times$ over state-of-the-art heavily-tuned LR schedules.