 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the Chaos: Coordinated Autoscaling for Heterogeneous and Disaggregated LLM Inference
Aug 27, 2025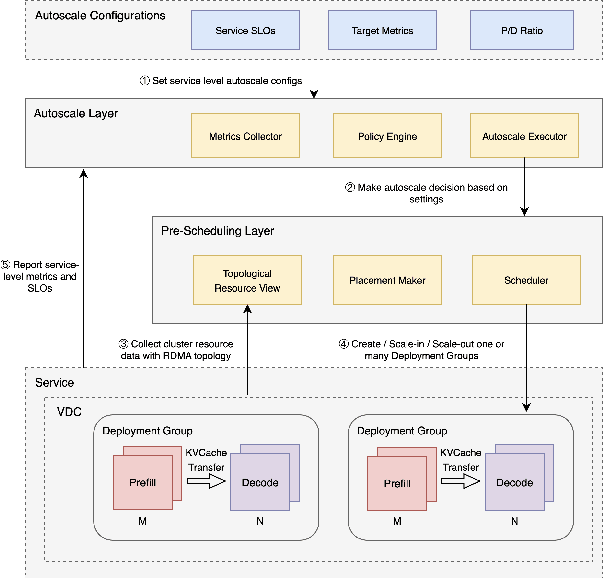

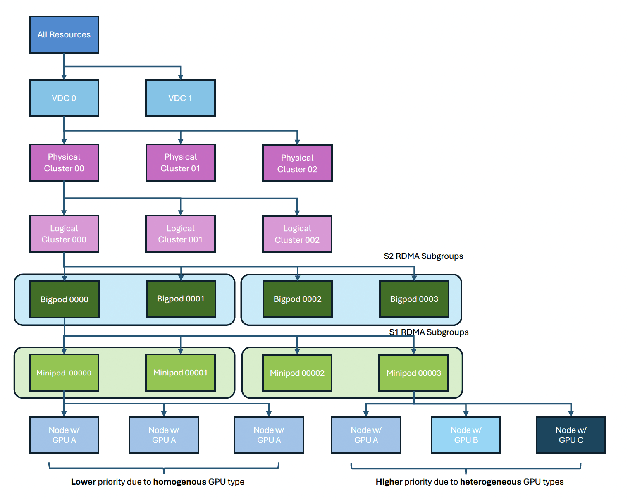
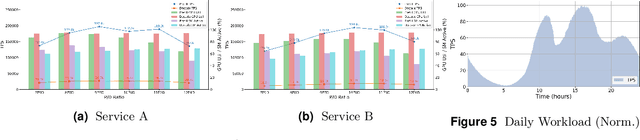
Serving Large Language Models (LLMs) is a GPU-intensive task where traditional autoscalers fall short, particularly for modern Prefill-Decode (P/D) disaggregated architectures. This architectural shift, while powerful, introduces significant operational challenges, including inefficient use of heterogeneous hardware, network bottlenecks, and critical imbalances between prefill and decode stages. We introduce HeteroScale, a coordinated autoscaling framework that addresses the core challenges of P/D disaggregated serving. HeteroScale combines a topology-aware scheduler that adapts to heterogeneous hardware and network constraints with a novel metric-driven policy derived from the first large-scale empirical study of autoscaling signals in production. By leveraging a single, robust metric to jointly scale prefill and decode pools, HeteroScale maintains architectural balance while ensuring efficient, adaptive resource management. Deployed in a massive production environment on tens of thousands of GPUs, HeteroScale has proven its effectiveness, increasing average GPU utilization by a significant 26.6 percentage points and saving hundreds of thousands of GPU-hours daily, all while upholding stringent service level objectives.
Understanding Stragglers in Large Model Training Using What-if Analysis
May 09, 2025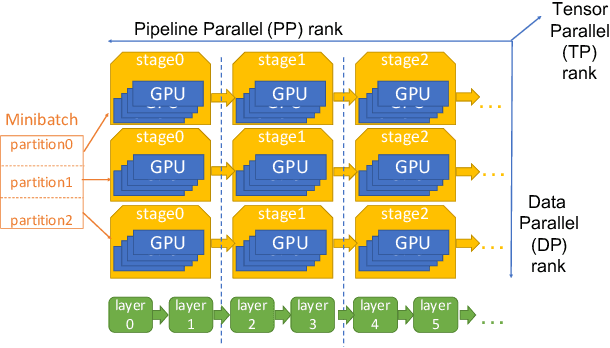

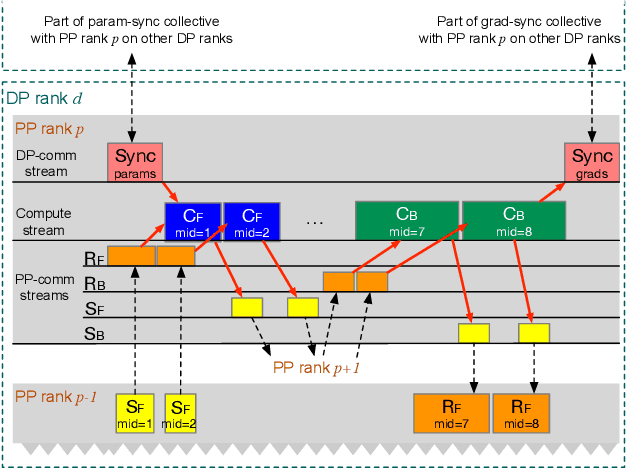
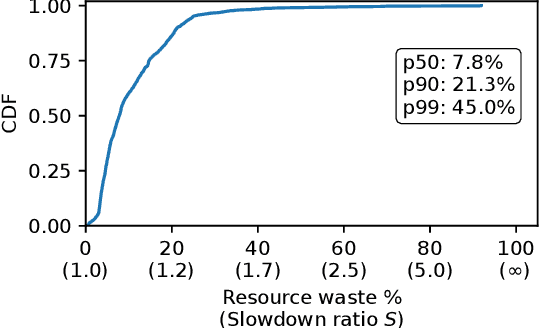
Large language model (LLM) training is one of the most demanding distributed computations today, often requiring thousands of GPUs with frequent synchronization across machines. Such a workload pattern makes it susceptible to stragglers, where the training can be stalled by few slow workers. At ByteDance we find stragglers are not trivially always caused by hardware failures, but can arise from multiple complex factors. This work aims to present a comprehensive study on the straggler issues in LLM training, using a five-month trace collected from our ByteDance LLM training cluster. The core methodology is what-if analysis that simulates the scenario without any stragglers and contrasts with the actual case. We use this method to study the following questions: (1) how often do stragglers affect training jobs, and what effect do they have on job performance; (2) do stragglers exhibit temporal or spatial patterns; and (3) what are the potential root causes for stragglers?
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Feb 23, 2024



We present the design, implementation and engineering experience in building and deploying MegaScale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs. Training LLMs at this scale brings unprecedented challenges to training efficiency and stability. We take a full-stack approach that co-designs the algorithmic and system components across model block and optimizer design, computation and communication overlapping, operator optimization, data pipeline, and network performance tuning. Maintaining high efficiency throughout the training process (i.e., stability) is an important consideration in production given the long extent of LLM training jobs. Many hard stability issues only emerge at large scale, and in-depth observability is the key to address them. We develop a set of diagnosis tools to monitor system components and events deep in the stack, identify root causes, and derive effective techniques to achieve fault tolerance and mitigate stragglers. MegaScale achieves 55.2% Model FLOPs Utilization (MFU) when training a 175B LLM model on 12,288 GPUs, improving the MFU by 1.34x compared to Megatron-LM. We share our operational experience in identifying and fixing failures and stragglers. We hope by articulating the problems and sharing our experience from a systems perspective, this work can inspire future LLM systems research.
Aryl: An Elastic Cluster Scheduler for Deep Learning
Feb 16, 2022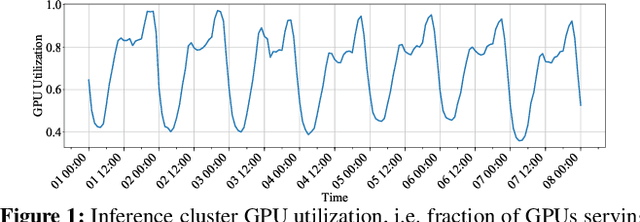
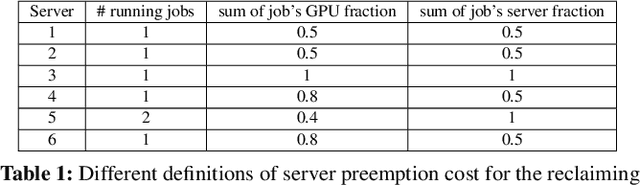
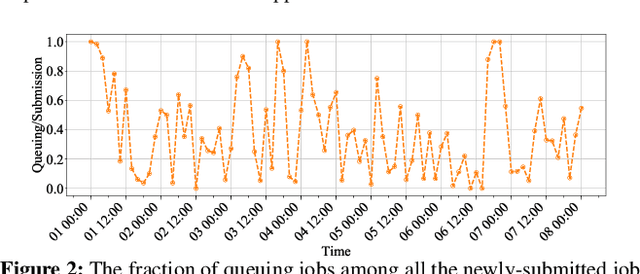
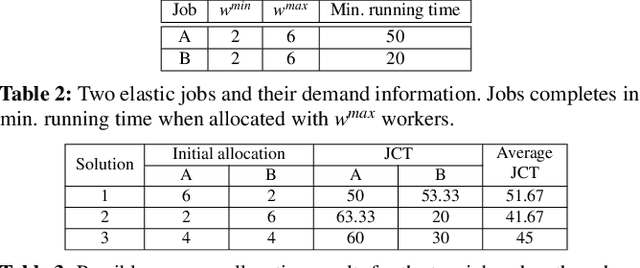
Companies build separate training and inference GPU clusters for deep learning, and use separate schedulers to manage them. This leads to problems for both training and inference: inference clusters have low GPU utilization when the traffic load is low; training jobs often experience long queueing time due to lack of resources. We introduce Aryl, a new cluster scheduler to address these problems. Aryl introduces capacity loaning to loan idle inference GPU servers for training jobs. It further exploits elastic scaling that scales a training job's GPU allocation to better utilize loaned resources. Capacity loaning and elastic scaling create new challenges to cluster management. When the loaned servers need to be returned, we need to minimize the number of job preemptions; when more GPUs become available, we need to allocate them to elastic jobs and minimize the job completion time (JCT). Aryl addresses these combinatorial problems using principled heuristics. It introduces the notion of server preemption cost which it greedily reduces during server reclaiming. It further relies on the JCT reduction value defined for each additional worker for an elastic job to solve the scheduling problem as a multiple-choice knapsack problem. Prototype implementation on a 64-GPU testbed and large-scale simulation with 15-day traces of over 50,000 production jobs show that Aryl brings 1.53x and 1.50x reductions in average queuing time and JCT, and improves cluster usage by up to 26.9% over the cluster scheduler without capacity loaning or elastic scaling.
Prediction of GPU Failures Under Deep Learning Workloads
Jan 27, 2022
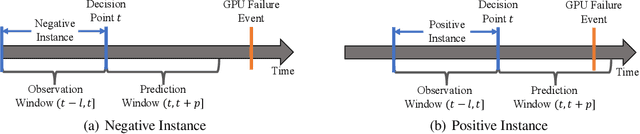
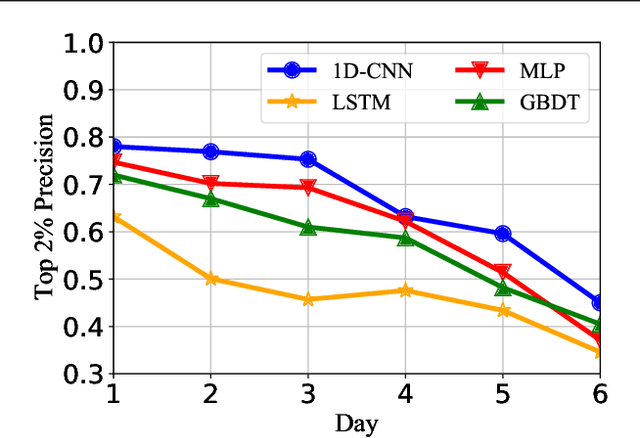

Graphics processing units (GPUs) are the de facto standard for processing deep learning (DL) tasks. Meanwhile, GPU failures, which are inevitable, cause severe consequences in DL tasks: they disrupt distributed trainings, crash inference services, and result in service level agreement violations. To mitigate the problem caused by GPU failures, we propose to predict failures by using ML models. This paper is the first to study prediction models of GPU failures under large-scale production deep learning workloads. As a starting point, we evaluate classic prediction models and observe that predictions of these models are both inaccurate and unstable. To improve the precision and stability of predictions, we propose several techniques, including parallel and cascade model-ensemble mechanisms and a sliding training method. We evaluate the performances of our various techniques on a four-month production dataset including 350 million entries. The results show that our proposed techniques improve the prediction precision from 46.3\% to 84.0\%.
Serving DNN Models with Multi-Instance GPUs: A Case of the Reconfigurable Machine Scheduling Problem
Sep 18, 2021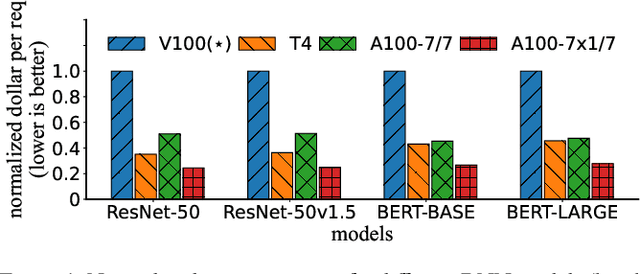
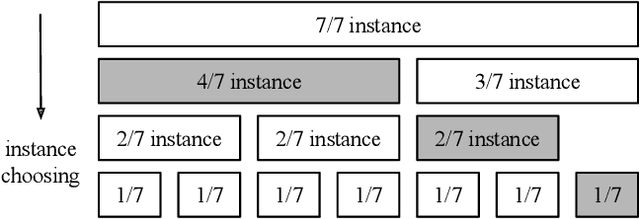
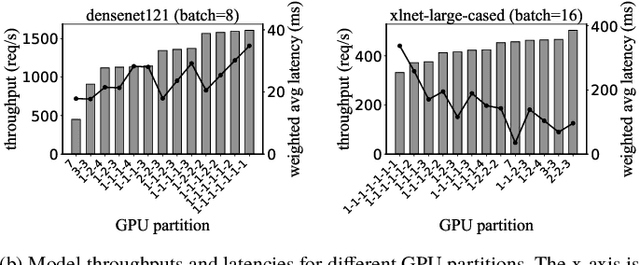
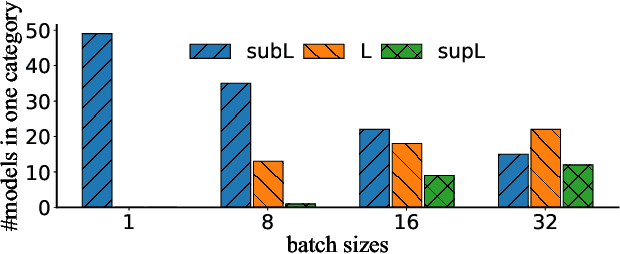
Multi-Instance GPU (MIG) is a new feature introduced by NVIDIA A100 GPUs that partitions one physical GPU into multiple GPU instances. With MIG, A100 can be the most cost-efficient GPU ever for serving Deep Neural Networks (DNNs). However, discovering the most efficient GPU partitions is challenging. The underlying problem is NP-hard; moreover, it is a new abstract problem, which we define as the Reconfigurable Machine Scheduling Problem (RMS). This paper studies serving DNNs with MIG, a new case of RMS. We further propose a solution, MIG-serving. MIG- serving is an algorithm pipeline that blends a variety of newly designed algorithms and customized classic algorithms, including a heuristic greedy algorithm, Genetic Algorithm (GA), and Monte Carlo Tree Search algorithm (MCTS). We implement MIG-serving on Kubernetes. Our experiments show that compared to using A100 as-is, MIG-serving can save up to 40% of GPUs while providing the same throughput.