 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Stragglers in Large Model Training Using What-if Analysis
May 09, 2025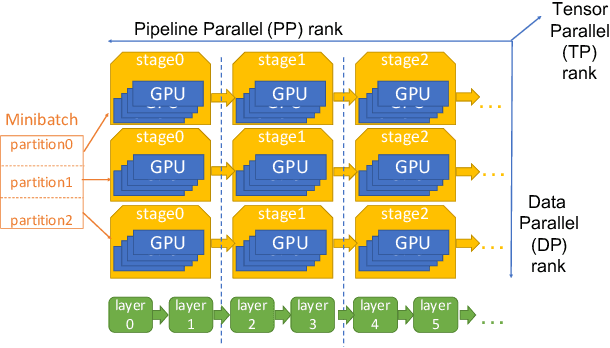

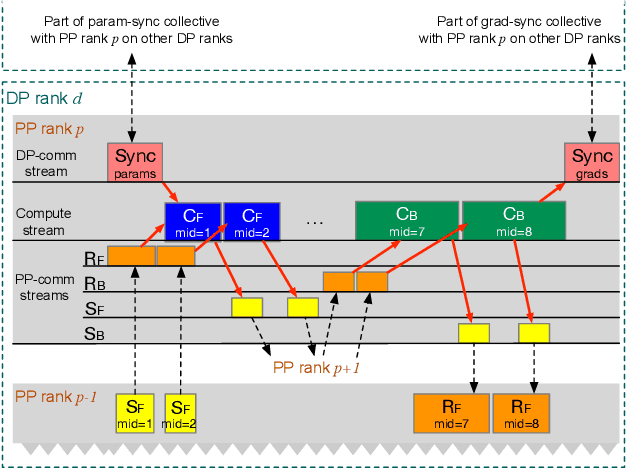
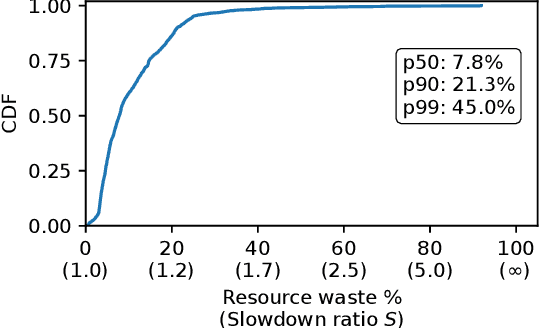
Large language model (LLM) training is one of the most demanding distributed computations today, often requiring thousands of GPUs with frequent synchronization across machines. Such a workload pattern makes it susceptible to stragglers, where the training can be stalled by few slow workers. At ByteDance we find stragglers are not trivially always caused by hardware failures, but can arise from multiple complex factors. This work aims to present a comprehensive study on the straggler issues in LLM training, using a five-month trace collected from our ByteDance LLM training cluster. The core methodology is what-if analysis that simulates the scenario without any stragglers and contrasts with the actual case. We use this method to study the following questions: (1) how often do stragglers affect training jobs, and what effect do they have on job performance; (2) do stragglers exhibit temporal or spatial patterns; and (3) what are the potential root causes for stragglers?
RAAMove: A Corpus for Analyzing Moves in Research Article Abstracts
Mar 23, 2024Move structures have been studied in English for Specific Purposes (ESP) and English for Academic Purposes (EAP) for decades. However, there are few move annotation corpora for Research Article (RA) abstracts. In this paper, we introduce RAAMove, a comprehensive multi-domain corpus dedicated to the annotation of move structures in RA abstracts. The primary objective of RAAMove is to facilitate move analysis and automatic move identification. This paper provides a thorough discussion of the corpus construction process, including the scheme, data collection, annotation guidelines, and annotation procedures. The corpus is constructed through two stages: initially, expert annotators manually annotate high-quality data; subsequently, based on the human-annotated data, a BERT-based model is employed for automatic annotation with the help of experts' modification. The result is a large-scale and high-quality corpus comprising 33,988 annotated instances. We also conduct preliminary move identification experiments using the BERT-based model to verify the effectiveness of the proposed corpus and model. The annotated corpus is available for academic research purposes and can serve as essential resources for move analysis, English language teaching and writing, as well as move/discourse-related tasks in Natural Language Processing (NLP).
Local Search for Integer Linear Programming
May 07, 2023

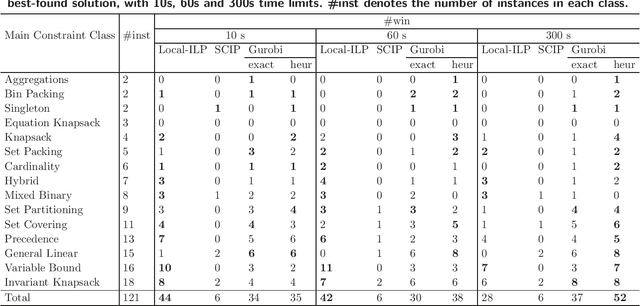
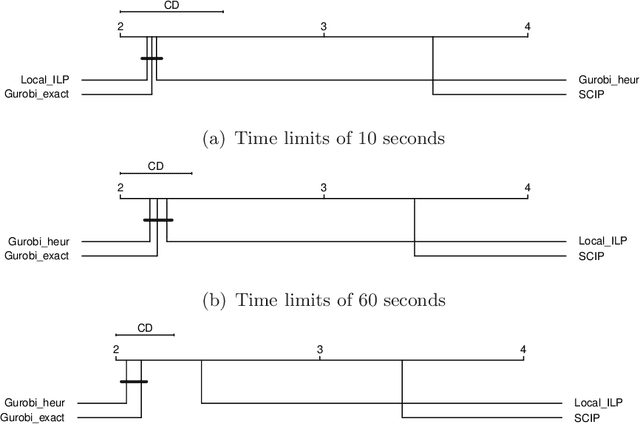
Integer linear programming models a wide range of practical combinatorial optimization problems and has significant impacts in industry and management sectors. This work develops the first standalone local search solver for general integer linear programming validated on a large heterogeneous problem dataset. We propose a local search framework that switches in three modes, namely Search, Improve, and Restore modes, and design tailored operators adapted to different modes, thus improve the quality of the current solution according to different situations. For the Search and Restore modes, we propose an operator named tight move, which adaptively modifies variables' values trying to make some constraint tight. For the Improve mode, an efficient operator lift move is proposed to improve the quality of the objective function while maintaining feasibility. Putting these together, we develop a local search solver for integer linear programming called Local-ILP. Experiments conducted on the MIPLIB dataset show the effectiveness of our solver in solving large-scale hard integer linear programming problems within a reasonably short time. Local-ILP is competitive and complementary to the state-of-the-art commercial solver Gurobi and significantly outperforms the state-of-the-art non-commercial solver SCIP. Moreover, our solver establishes new records for 6 MIPLIB open instances.
Finding Deep-Learning Compilation Bugs with NNSmith
Jul 26, 2022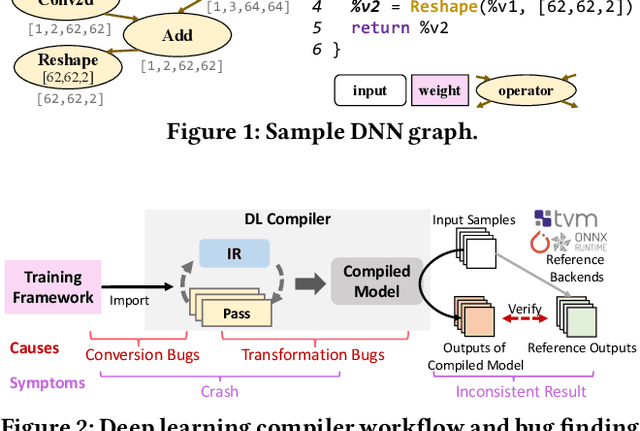


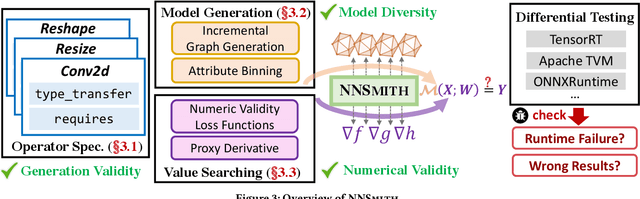
Deep-learning (DL) compilers such as TVM and TensorRT are increasingly used to optimize deep neural network (DNN) models to meet performance, resource utilization and other requirements. Bugs in these compilers can produce optimized models whose semantics differ from the original models, and produce incorrect results impacting the correctness of down stream applications. However, finding bugs in these compilers is challenging due to their complexity. In this work, we propose a new fuzz testing approach for finding bugs in deep-learning compilers. Our core approach uses (i) light-weight operator specifications to generate diverse yet valid DNN models allowing us to exercise a large part of the compiler's transformation logic; (ii) a gradient-based search process for finding model inputs that avoid any floating-point exceptional values during model execution, reducing the chance of missed bugs or false alarms; and (iii) differential testing to identify bugs. We implemented this approach in NNSmith which has found 65 new bugs in the last seven months for TVM, TensorRT, ONNXRuntime, and PyTorch. Of these 52 have been confirmed and 44 have been fixed by project maintainers.
Measuring the Effect of Training Data on Deep Learning Predictions via Randomized Experiments
Jun 20, 2022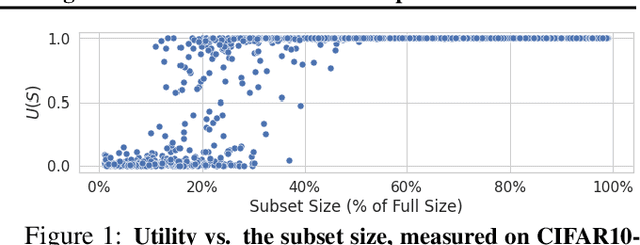
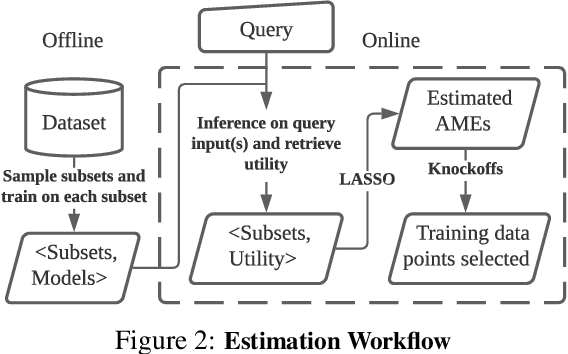

We develop a new, principled algorithm for estimating the contribution of training data points to the behavior of a deep learning model, such as a specific prediction it makes. Our algorithm estimates the AME, a quantity that measures the expected (average) marginal effect of adding a data point to a subset of the training data, sampled from a given distribution. When subsets are sampled from the uniform distribution, the AME reduces to the well-known Shapley value. Our approach is inspired by causal inference and randomized experiments: we sample different subsets of the training data to train multiple submodels, and evaluate each submodel's behavior. We then use a LASSO regression to jointly estimate the AME of each data point, based on the subset compositions. Under sparsity assumptions ($k \ll N$ datapoints have large AME), our estimator requires only $O(k\log N)$ randomized submodel trainings, improving upon the best prior Shapley value estimators.
Hop: Heterogeneity-Aware Decentralized Training
Feb 07, 2019
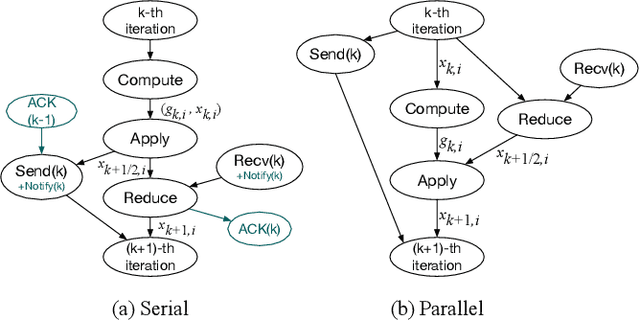
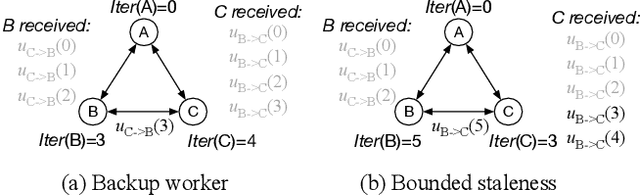

Recent work has shown that decentralized algorithms can deliver superior performance over centralized ones in the context of machine learning. The two approaches, with the main difference residing in their distinct communication patterns, are both susceptible to performance degradation in heterogeneous environments. Although vigorous efforts have been devoted to supporting centralized algorithms against heterogeneity, little has been explored in decentralized algorithms regarding this problem. This paper proposes Hop, the first heterogeneity-aware decentralized training protocol. Based on a unique characteristic of decentralized training that we have identified, the iteration gap, we propose a queue-based synchronization mechanism that can efficiently implement backup workers and bounded staleness in the decentralized setting. To cope with deterministic slowdown, we propose skipping iterations so that the effect of slower workers is further mitigated. We build a prototype implementation of Hop on TensorFlow. The experiment results on CNN and SVM show significant speedup over standard decentralized training in heterogeneous settings.