 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cross-Architecture Knowledge Transfer for Large-Scale Online User Response Prediction
Feb 02, 2026Deploying new architectures in large-scale user response prediction systems incurs high model switching costs due to expensive retraining on massive historical data and performance degradation under data retention constraints. Existing knowledge distillation methods struggle with architectural heterogeneity and the prohibitive cost of transferring large embedding tables. We propose CrossAdapt, a two-stage framework for efficient cross-architecture knowledge transfer. The offline stage enables rapid embedding transfer via dimension-adaptive projections without iterative training, combined with progressive network distillation and strategic sampling to reduce computational cost. The online stage introduces asymmetric co-distillation, where students update frequently while teachers update infrequently, together with a distribution-aware adaptation mechanism that dynamically balances historical knowledge preservation and fast adaptation to evolving data. Experiments on three public datasets show that CrossAdapt achieves 0.27-0.43% AUC improvements while reducing training time by 43-71%. Large-scale deployment on Tencent WeChat Channels (~10M daily samples) further demonstrates its effectiveness, significantly mitigating AUC degradation, LogLoss increase, and prediction bias compared to standard distillation baselines.
LAC: Graph Contrastive Learning with Learnable Augmentation in Continuous Space
Oct 20, 2024Graph Contrastive Learning frameworks have demonstrated success in generating high-quality node representations. The existing research on efficient data augmentation methods and ideal pretext tasks for graph contrastive learning remains limited, resulting in suboptimal node representation in the unsupervised setting. In this paper, we introduce LAC, a graph contrastive learning framework with learnable data augmentation in an orthogonal continuous space. To capture the representative information in the graph data during augmentation, we introduce a continuous view augmenter, that applies both a masked topology augmentation module and a cross-channel feature augmentation module to adaptively augment the topological information and the feature information within an orthogonal continuous space, respectively. The orthogonal nature of continuous space ensures that the augmentation process avoids dimension collapse. To enhance the effectiveness of pretext tasks, we propose an information-theoretic principle named InfoBal and introduce corresponding pretext tasks. These tasks enable the continuous view augmenter to maintain consistency in the representative information across views while maximizing diversity between views, and allow the encoder to fully utilize the representative information in the unsupervised setting. Our experimental results show that LAC significantly outperforms the state-of-the-art frameworks.
SpanGNN: Towards Memory-Efficient Graph Neural Networks via Spanning Subgraph Training
Jun 07, 2024



Graph Neural Networks (GNNs) have superior capability in learning graph data. Full-graph GNN training generally has high accuracy, however, it suffers from large peak memory usage and encounters the Out-of-Memory problem when handling large graphs. To address this memory problem, a popular solution is mini-batch GNN training. However, mini-batch GNN training increases the training variance and sacrifices the model accuracy. In this paper, we propose a new memory-efficient GNN training method using spanning subgraph, called SpanGNN. SpanGNN trains GNN models over a sequence of spanning subgraphs, which are constructed from empty structure. To overcome the excessive peak memory consumption problem, SpanGNN selects a set of edges from the original graph to incrementally update the spanning subgraph between every epoch. To ensure the model accuracy, we introduce two types of edge sampling strategies (i.e., variance-reduced and noise-reduced), and help SpanGNN select high-quality edges for the GNN learning. We conduct experiments with SpanGNN on widely used datasets, demonstrating SpanGNN's advantages in the model performance and low peak memory usage.
RAAMove: A Corpus for Analyzing Moves in Research Article Abstracts
Mar 23, 2024Move structures have been studied in English for Specific Purposes (ESP) and English for Academic Purposes (EAP) for decades. However, there are few move annotation corpora for Research Article (RA) abstracts. In this paper, we introduce RAAMove, a comprehensive multi-domain corpus dedicated to the annotation of move structures in RA abstracts. The primary objective of RAAMove is to facilitate move analysis and automatic move identification. This paper provides a thorough discussion of the corpus construction process, including the scheme, data collection, annotation guidelines, and annotation procedures. The corpus is constructed through two stages: initially, expert annotators manually annotate high-quality data; subsequently, based on the human-annotated data, a BERT-based model is employed for automatic annotation with the help of experts' modification. The result is a large-scale and high-quality corpus comprising 33,988 annotated instances. We also conduct preliminary move identification experiments using the BERT-based model to verify the effectiveness of the proposed corpus and model. The annotated corpus is available for academic research purposes and can serve as essential resources for move analysis, English language teaching and writing, as well as move/discourse-related tasks in Natural Language Processing (NLP).
Distributed Graph Neural Network Training: A Survey
Nov 01, 2022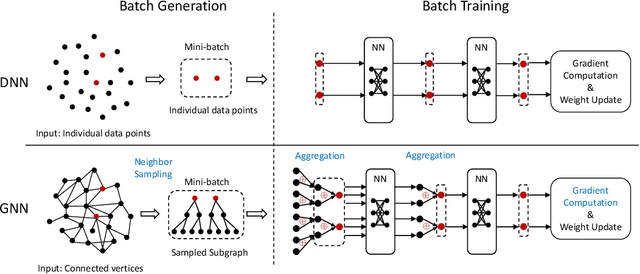

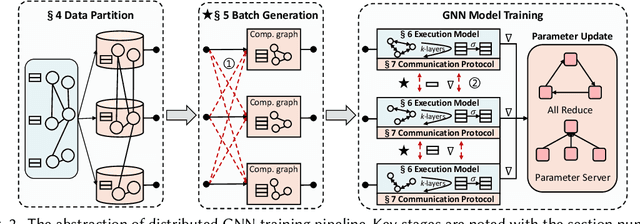
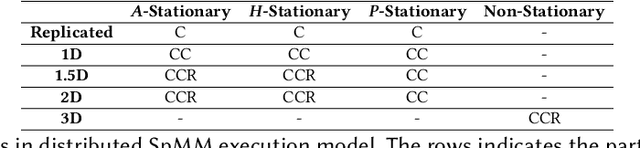
Graph neural networks (GNNs) are a type of deep learning models that learning over graphs, and have been successfully applied in many domains. Despite the effectiveness of GNNs, it is still challenging for GNNs to efficiently scale to large graphs. As a remedy, distributed computing becomes a promising solution of training large-scale GNNs, since it is able to provide abundant computing resources. However, the dependency of graph structure increases the difficulty of achieving high-efficiency distributed GNN training, which suffers from the massive communication and workload imbalance. In recent years, many efforts have been made on distributed GNN training, and an array of training algorithms and systems have been proposed. Yet, there is a lack of systematic review on the optimization techniques from graph processing to distributed execution. In this survey, we analyze three major challenges in distributed GNN training that are massive feature communication, the loss of model accuracy and workload imbalance. Then we introduce a new taxonomy for the optimization techniques in distributed GNN training that address the above challenges. The new taxonomy classifies existing techniques into four categories that are GNN data partition, GNN batch generation, GNN execution model, and GNN communication protocol.We carefully discuss the techniques in each category. In the end, we summarize existing distributed GNN systems for multi-GPUs, GPU-clusters and CPU-clusters, respectively, and give a discussion about the future direction on scalable GNNs.
Evaluating Low-Resource Machine Translation between Chinese and Vietnamese with Back-Translation
Mar 06, 2020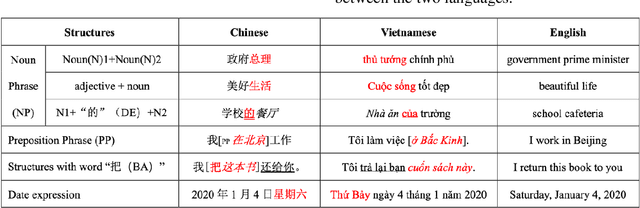
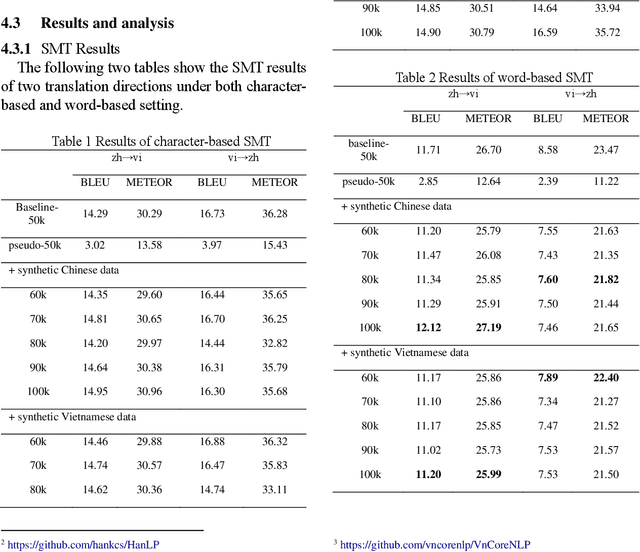
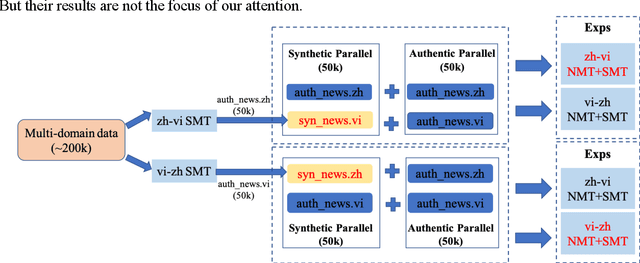

Back translation (BT) has been widely used and become one of standard techniques for data augmentation in Neural Machine Translation (NMT), BT has proven to be helpful for improving the performance of translation effectively, especially for low-resource scenarios. While most works related to BT mainly focus on European languages, few of them study languages in other areas around the world. In this paper, we investigate the impacts of BT on Asia language translations between the extremely low-resource Chinese and Vietnamese language pair. We evaluate and compare the effects of different sizes of synthetic data on both NMT and Statistical Machine Translation (SMT) models for Chinese to Vietnamese and Vietnamese to Chinese, with character-based and word-based settings. Some conclusions from previous works are partially confirmed and we also draw some other interesting findings and conclusions, which are beneficial to understand BT further.