 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveRX: A Vision-Language Reasoning Model for Cross-Task Autonomous Driving
May 27, 2025Autonomous driving requires real-time, robust reasoning across perception, prediction, planning, and behavior. However, conventional end-to-end models fail to generalize in complex scenarios due to the lack of structured reasoning. Recent vision-language models (VLMs) have been applied to driving tasks, but they typically rely on isolated modules and static supervision, limiting their ability to support multi-stage decision-making. We present AutoDriveRL, a unified training framework that formulates autonomous driving as a structured reasoning process over four core tasks. Each task is independently modeled as a vision-language question-answering problem and optimized using task-specific reward models, enabling fine-grained reinforcement signals at different reasoning stages. Within this framework, we train DriveRX, a cross-task reasoning VLM designed for real-time decision-making. DriveRX achieves strong performance on a public benchmark, outperforming GPT-4o in behavior reasoning and demonstrating robustness under complex or corrupted driving conditions. Our analysis further highlights the impact of vision encoder design and reward-guided reasoning compression. We will release the AutoDriveRL framework and the DriveRX model to support future research.
A Split-Window Transformer for Multi-Model Sequence Spammer Detection using Multi-Model Variational Autoencoder
Feb 23, 2025



This paper introduces a new Transformer, called MS$^2$Dformer, that can be used as a generalized backbone for multi-modal sequence spammer detection. Spammer detection is a complex multi-modal task, thus the challenges of applying Transformer are two-fold. Firstly, complex multi-modal noisy information about users can interfere with feature mining. Secondly, the long sequence of users' historical behaviors also puts a huge GPU memory pressure on the attention computation. To solve these problems, we first design a user behavior Tokenization algorithm based on the multi-modal variational autoencoder (MVAE). Subsequently, a hierarchical split-window multi-head attention (SW/W-MHA) mechanism is proposed. The split-window strategy transforms the ultra-long sequences hierarchically into a combination of intra-window short-term and inter-window overall attention. Pre-trained on the public datasets, MS$^2$Dformer's performance far exceeds the previous state of the art. The experiments demonstrate MS$^2$Dformer's ability to act as a backbone.
Distributed Graph Neural Network Training: A Survey
Nov 01, 2022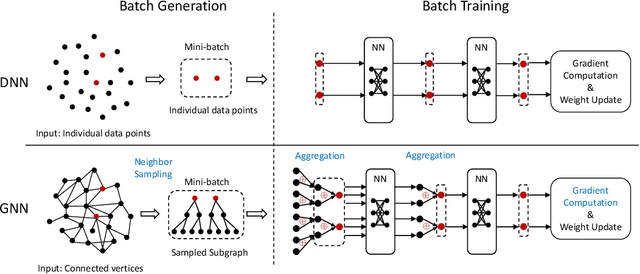

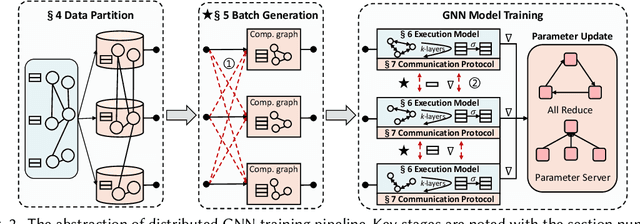
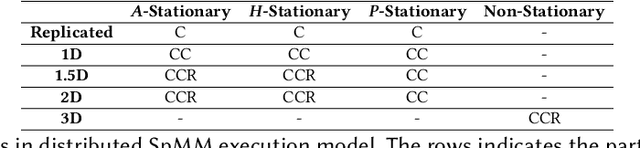
Graph neural networks (GNNs) are a type of deep learning models that learning over graphs, and have been successfully applied in many domains. Despite the effectiveness of GNNs, it is still challenging for GNNs to efficiently scale to large graphs. As a remedy, distributed computing becomes a promising solution of training large-scale GNNs, since it is able to provide abundant computing resources. However, the dependency of graph structure increases the difficulty of achieving high-efficiency distributed GNN training, which suffers from the massive communication and workload imbalance. In recent years, many efforts have been made on distributed GNN training, and an array of training algorithms and systems have been proposed. Yet, there is a lack of systematic review on the optimization techniques from graph processing to distributed execution. In this survey, we analyze three major challenges in distributed GNN training that are massive feature communication, the loss of model accuracy and workload imbalance. Then we introduce a new taxonomy for the optimization techniques in distributed GNN training that address the above challenges. The new taxonomy classifies existing techniques into four categories that are GNN data partition, GNN batch generation, GNN execution model, and GNN communication protocol.We carefully discuss the techniques in each category. In the end, we summarize existing distributed GNN systems for multi-GPUs, GPU-clusters and CPU-clusters, respectively, and give a discussion about the future direction on scalable GNNs.