 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Segment Attention: Enabling Efficient KV-Cache Management for Faster Large Language Model Serving
Jun 01, 2026Large Language Model (LLM) inference relies on key-value (KV) caches to avoid redundant attention computation. While approximate KV cache retention techniques reduce memory usage by sacrificing model accuracy, lossless approaches instead evict KV cache blocks from GPU memory and reconstruct them on demand to preserve exact outputs. Existing lossless KV cache management systems primarily base eviction decisions on access frequency or positional heuristics, without considering how different KV cache blocks affect the execution efficiency of GPU attention kernels. In this paper, we propose AsymCache, a computation-latency-aware KV cache management system for LLM inference that explicitly aligns cache residency decisions with GPU attention kernel performance, including three key components: Multi-Segment Attention (MSA) for efficient non-contiguous KV context processing, a cache eviction policy that jointly optimizes hit rate and position-aware recomputation cost, and an adaptive chunking scheduler for high hardware utilization. Experiments show that AsymCache reduces TTFT by up to 1.90-2.03x and time-per-output-token (TPOT) by 1.62-1.71x over latest baselines, confirming the effectiveness of the method in common workloads and validating its design goal of balancing computational efficiency with cache hit rate. Moreover, the low-level design of AsymCache allows seamless integration into agent serving systems such as Continuum, where it further reduces average job latency by up to 18.1%.
DARTS: Distribution-Aware Active Rollout Trajectory Shaping for Accelerating LLM Reinforcement Learning
May 29, 2026Reinforcement Learning (RL) has become pivotal for improving model capabilities yet suffers from rollout efficiency bottlenecks due to the long-tail response length distribution. While existing works mitigate the impact of long tails via prompt-level tail scheduling, we focus on the root source of inefficiency: the distribution itself. Specifically, we characterize the long-tail distribution at a finer granularity, identifying intra-prompt long tails, and revealing that they frequently consist of ineffective verbosity. To address this, we propose a novel paradigm of active distribution shaping to shape the rollout distribution towards conciseness and certainty, thereby fundamentally resolving tail-induced overheads. We achieve this through a distribution-aware trajectory sampling mechanism, which selects trajectories from a redundant exploration space for each prompt, and an adaptive redundancy allocation scheme to maximize both shaping effectiveness and system efficiency. Experiments demonstrate significant acceleration over state-of-the-art systems by up to 1.77x without compromising model performance.
AutoSci: A Memory-Centric Agentic System for the Full Scientific Research Lifecycle
May 29, 2026Scientific research has traditionally been human-intensive, requiring researchers to coordinate literature, ideas, experiments, manuscripts, and review responses across long project cycles. The rise of LLM-based scientific agents creates an opportunity to automate this process. Such a system must support the full research lifecycle, maintain structured persistent memory across projects, and improve its own research procedures over time. However, existing systems either partially satisfy or fail to satisfy these requirements, leaving a gap for a unified automated scientific research system. As a result, we present AutoSci, a memory-centric agentic system for the full scientific research lifecycle. AutoSci is organized around four modules. SciMem provides schema-governed research memory, separating Long-Term Knowledge Memory for reusable scientific knowledge from Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews. SciFlow executes a five-stage lifecycle from literature understanding to rebuttal through a harness that controls state, context, verification, feedback, and orchestration. SciDAG augments difficult skills with DAG-shaped multi-agent operators and reusable stage-specific templates. SciEvolve converts feedback signals from users, experiments, reviews, and external environments into versioned updates to SciMem organization, SciFlow skills, and SciDAG templates. Together, these modules make AutoSci a persistent research environment that can execute, remember, and evolve across research projects. The code repository is available at https://github.com/skyllwt/AutoSci.
Coral: Cost-Efficient Multi-LLM Serving over Heterogeneous Cloud GPUs
May 05, 2026The usage of large language models (LLMs) has grown increasingly fragmented, with no single model dominating. Meanwhile, cloud providers offer a wide range of mid-tier and older-generation GPUs that enjoy better availability and deliver comparable performance per dollar to top-tier hardware. To efficiently harness these heterogeneous resources for serving multiple LLMs concurrently, we introduce Coral, an adaptive heterogeneity-aware multi-LLM serving system. The key idea behind Coral is to jointly optimize resource allocation and the serving strategy of each model replica across all models. To keep pace with shifting throughput demand and resource availability, Coral applies a lossless two-stage decomposition that preserves joint optimality while cutting online solve time from hours to tens of seconds. Our evaluation across 6 models and 20 GPU configurations shows that Coral reduces serving cost by up to 2.79$\times$ over the best baseline, and delivers up to 2.39$\times$ higher goodput under scarce resource availability.
Event Tensor: A Unified Abstraction for Compiling Dynamic Megakernel
Apr 14, 2026Modern GPU workloads, especially large language model (LLM) inference, suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. Recent megakernel techniques fuse multiple operators into a single persistent kernel to eliminate launch gaps and expose inter-kernel parallelism, but struggle to handle dynamic shapes and data-dependent computation in real workloads. We present Event Tensor, a unified compiler abstraction for dynamic megakernels. Event Tensor encodes dependencies between tiled tasks, and enables first-class support for both shape and data-dependent dynamism. Built atop this abstraction, our Event Tensor Compiler (ETC) applies static and dynamic scheduling transformations to generate high-performance persistent kernels. Evaluations show that ETC achieves state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
Mirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs
Dec 22, 2025We introduce Mirage Persistent Kernel (MPK), the first compiler and runtime system that automatically transforms multi-GPU model inference into a single high-performance megakernel. MPK introduces an SM-level graph representation that captures data dependencies at the granularity of individual streaming multiprocessors (SMs), enabling cross-operator software pipelining, fine-grained kernel overlap, and other previously infeasible GPU optimizations. The MPK compiler lowers tensor programs into highly optimized SM-level task graphs and generates optimized CUDA implementations for all tasks, while the MPK in-kernel parallel runtime executes these tasks within a single mega-kernel using decentralized scheduling across SMs. Together, these components provide end-to-end kernel fusion with minimal developer effort, while preserving the flexibility of existing programming models. Our evaluation shows that MPK significantly outperforms existing kernel-per-operator LLM serving systems by reducing end-to-end inference latency by up to 1.7x, pushing LLM inference performance close to hardware limits. MPK is publicly available at https://github.com/mirage-project/mirage.
AdaServe: SLO-Customized LLM Serving with Fine-Grained Speculative Decoding
Jan 21, 2025This paper introduces AdaServe, the first LLM serving system to support SLO customization through fine-grained speculative decoding. AdaServe leverages the logits of a draft model to predict the speculative accuracy of tokens and employs a theoretically optimal algorithm to construct token trees for verification. To accommodate diverse SLO requirements without compromising throughput, AdaServe employs a speculation-and-selection scheme that first constructs candidate token trees for each request and then dynamically selects tokens to meet individual SLO constraints while optimizing throughput. Comprehensive evaluations demonstrate that AdaServe achieves up to 73% higher SLO attainment and 74% higher goodput compared to state-of-the-art systems. These results underscore AdaServe's potential to enhance the efficiency and adaptability of LLM deployments across varied application scenarios.
Efficient Multi-Task Large Model Training via Data Heterogeneity-aware Model Management
Sep 05, 2024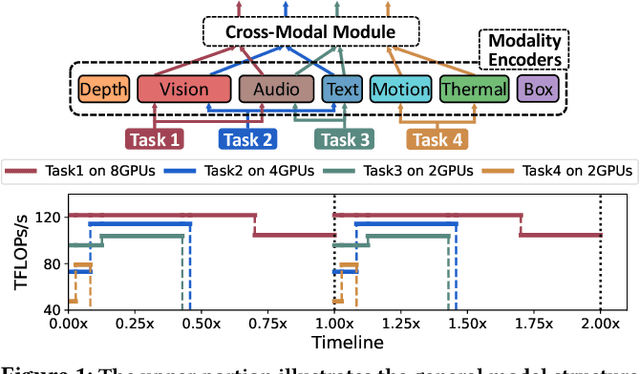

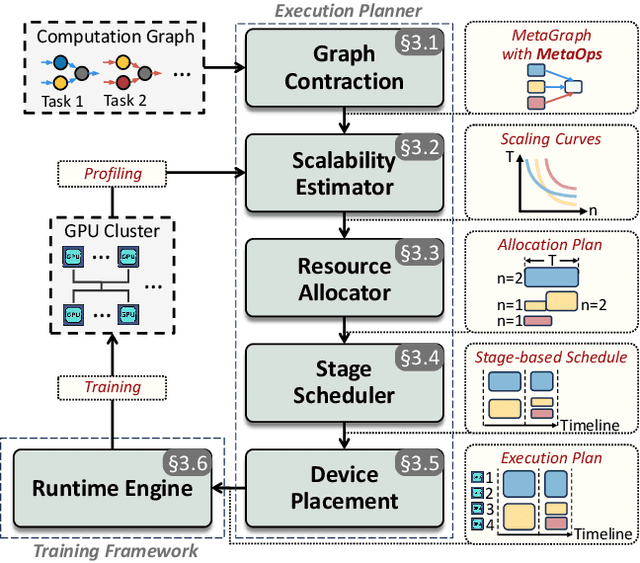
Recent foundation models are capable of handling multiple machine learning (ML) tasks and multiple data modalities with the unified base model structure and several specialized model components. However, the development of such multi-task (MT) multi-modal (MM) models poses significant model management challenges to existing training systems. Due to the sophisticated model architecture and the heterogeneous workloads of different ML tasks and data modalities, training these models usually requires massive GPU resources and suffers from sub-optimal system efficiency. In this paper, we investigate how to achieve high-performance training of large-scale MT MM models through data heterogeneity-aware model management optimization. The key idea is to decompose the model execution into stages and address the joint optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling. Based on this, we build a prototype system and evaluate it on various large MT MM models. Experiments demonstrate the superior performance and efficiency of our system, with speedup ratio up to 71% compared to state-of-the-art training systems.
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024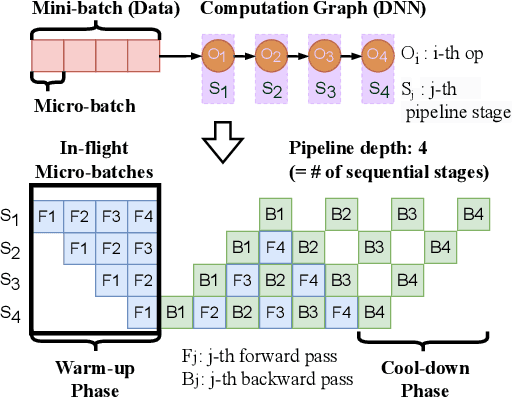

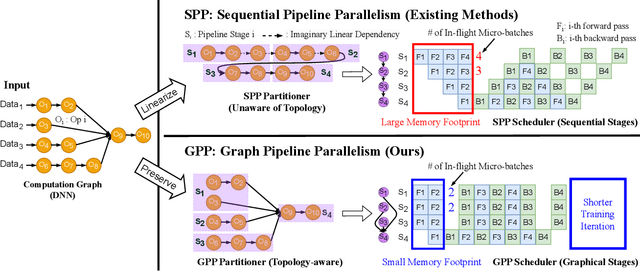
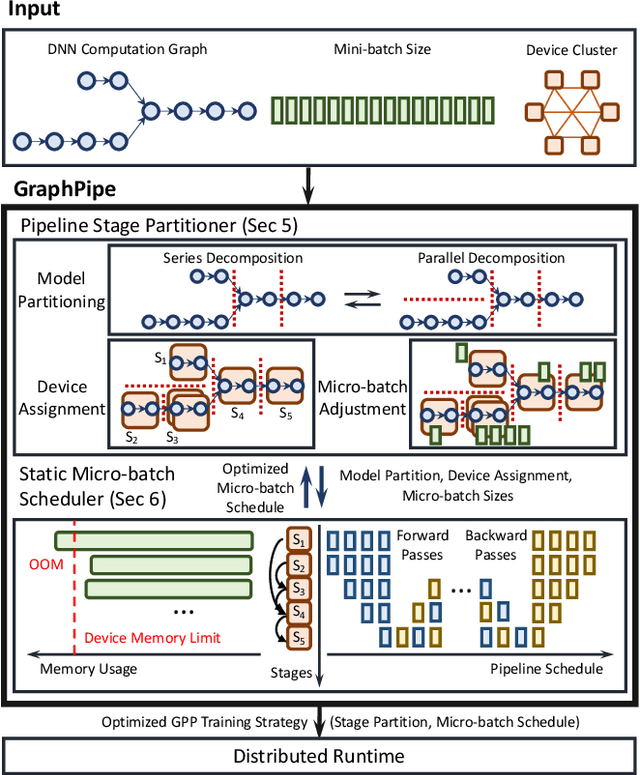
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
Optimal Kernel Orchestration for Tensor Programs with Korch
Jun 13, 2024


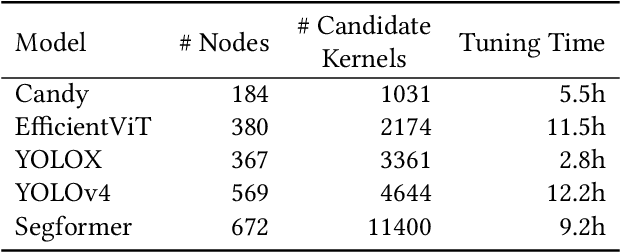
Kernel orchestration is the task of mapping the computation defined in different operators of a deep neural network (DNN) to the execution of GPU kernels on modern hardware platforms. Prior approaches optimize kernel orchestration by greedily applying operator fusion, which fuses the computation of multiple operators into a single kernel, and miss a variety of optimization opportunities in kernel orchestration. This paper presents Korch, a tensor program optimizer that discovers optimal kernel orchestration strategies for tensor programs. Instead of directly fusing operators, Korch first applies operator fission to decompose tensor operators into a small set of basic tensor algebra primitives. This decomposition enables a diversity of fine-grained, inter-operator optimizations. Next, Korch optimizes kernel orchestration by formalizing it as a constrained optimization problem, leveraging an off-the-shelf binary linear programming solver to discover an optimal orchestration strategy, and generating an executable that can be directly deployed on modern GPU platforms. Evaluation on a variety of DNNs shows that Korch outperforms existing tensor program optimizers by up to 1.7x on V100 GPUs and up to 1.6x on A100 GPUs. Korch is publicly available at https://github.com/humuyan/Korch.
* Fix some typos in the ASPLOS version