 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Tensor: A Unified Abstraction for Compiling Dynamic Megakernel
Apr 14, 2026Modern GPU workloads, especially large language model (LLM) inference, suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. Recent megakernel techniques fuse multiple operators into a single persistent kernel to eliminate launch gaps and expose inter-kernel parallelism, but struggle to handle dynamic shapes and data-dependent computation in real workloads. We present Event Tensor, a unified compiler abstraction for dynamic megakernels. Event Tensor encodes dependencies between tiled tasks, and enables first-class support for both shape and data-dependent dynamism. Built atop this abstraction, our Event Tensor Compiler (ETC) applies static and dynamic scheduling transformations to generate high-performance persistent kernels. Evaluations show that ETC achieves state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
Mirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs
Dec 22, 2025We introduce Mirage Persistent Kernel (MPK), the first compiler and runtime system that automatically transforms multi-GPU model inference into a single high-performance megakernel. MPK introduces an SM-level graph representation that captures data dependencies at the granularity of individual streaming multiprocessors (SMs), enabling cross-operator software pipelining, fine-grained kernel overlap, and other previously infeasible GPU optimizations. The MPK compiler lowers tensor programs into highly optimized SM-level task graphs and generates optimized CUDA implementations for all tasks, while the MPK in-kernel parallel runtime executes these tasks within a single mega-kernel using decentralized scheduling across SMs. Together, these components provide end-to-end kernel fusion with minimal developer effort, while preserving the flexibility of existing programming models. Our evaluation shows that MPK significantly outperforms existing kernel-per-operator LLM serving systems by reducing end-to-end inference latency by up to 1.7x, pushing LLM inference performance close to hardware limits. MPK is publicly available at https://github.com/mirage-project/mirage.
A Multi-Level Superoptimizer for Tensor Programs
May 09, 2024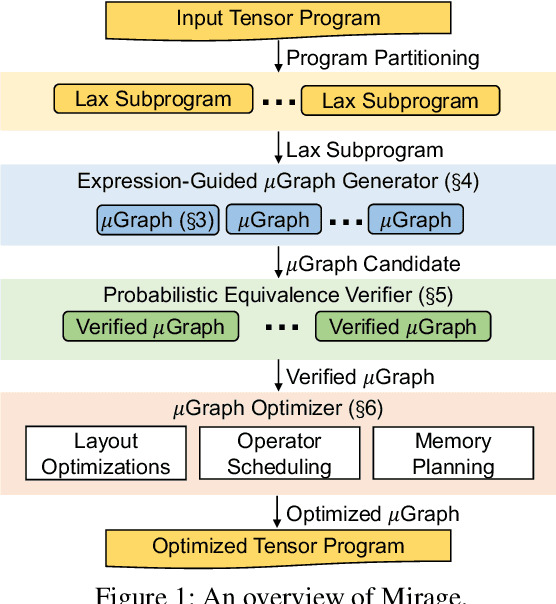


We introduce Mirage, the first multi-level superoptimizer for tensor programs. A key idea in Mirage is $\mu$Graphs, a uniform representation of tensor programs at the kernel, thread block, and thread levels of the GPU compute hierarchy. $\mu$Graphs enable Mirage to discover novel optimizations that combine algebraic transformations, schedule transformations, and generation of new custom kernels. To navigate the large search space, Mirage introduces a pruning technique based on abstraction that significantly reduces the search space and provides a certain optimality guarantee. To ensure that the optimized $\mu$Graph is equivalent to the input program, Mirage introduces a probabilistic equivalence verification procedure with strong theoretical guarantees. Our evaluation shows that Mirage outperforms existing approaches by up to 3.5$\times$ even for DNNs that are widely used and heavily optimized. Mirage is publicly available at https://github.com/mirage-project/mirage.
FlexLLM: A System for Co-Serving Large Language Model Inference and Parameter-Efficient Finetuning
Feb 29, 2024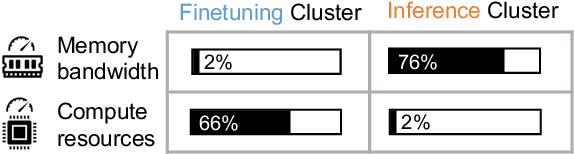
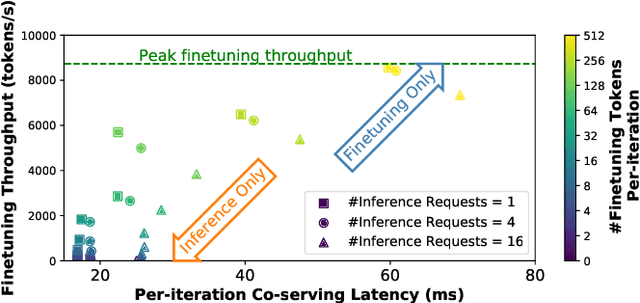

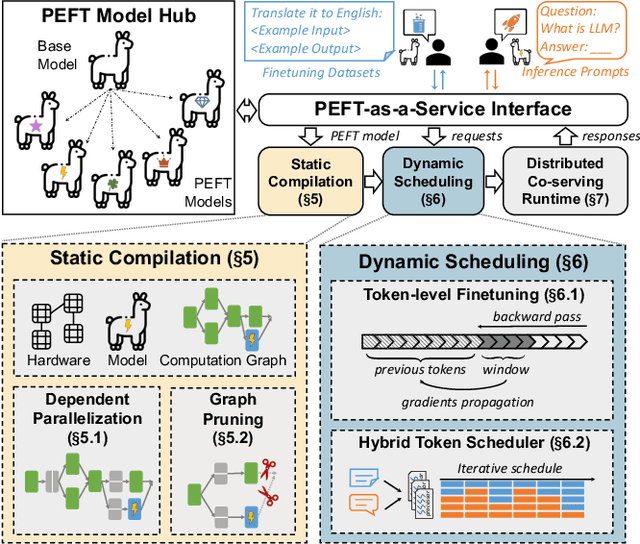
Parameter-efficient finetuning (PEFT) is a widely used technique to adapt large language models for different tasks. Service providers typically create separate systems for users to perform PEFT model finetuning and inference tasks. This is because existing systems cannot handle workloads that include a mix of inference and PEFT finetuning requests. As a result, shared GPU resources are underutilized, leading to inefficiencies. To address this problem, we present FlexLLM, the first system that can serve inference and parameter-efficient finetuning requests in the same iteration. Our system leverages the complementary nature of these two tasks and utilizes shared GPU resources to run them jointly, using a method called co-serving. To achieve this, FlexLLM introduces a novel token-level finetuning mechanism, which breaks down the finetuning computation of a sequence into smaller token-level computations and uses dependent parallelization and graph pruning, two static compilation optimizations, to minimize the memory overhead and latency for co-serving. Compared to existing systems, FlexLLM's co-serving approach reduces the activation GPU memory overhead by up to 8x, and the end-to-end GPU memory requirement of finetuning by up to 36% while maintaining a low inference latency and improving finetuning throughput. For example, under a heavy inference workload, FlexLLM can still preserve more than 80% of the peak finetuning throughput, whereas existing systems cannot make any progress with finetuning. The source code of FlexLLM is publicly available at https://github.com/flexflow/FlexFlow.
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
Dec 23, 2023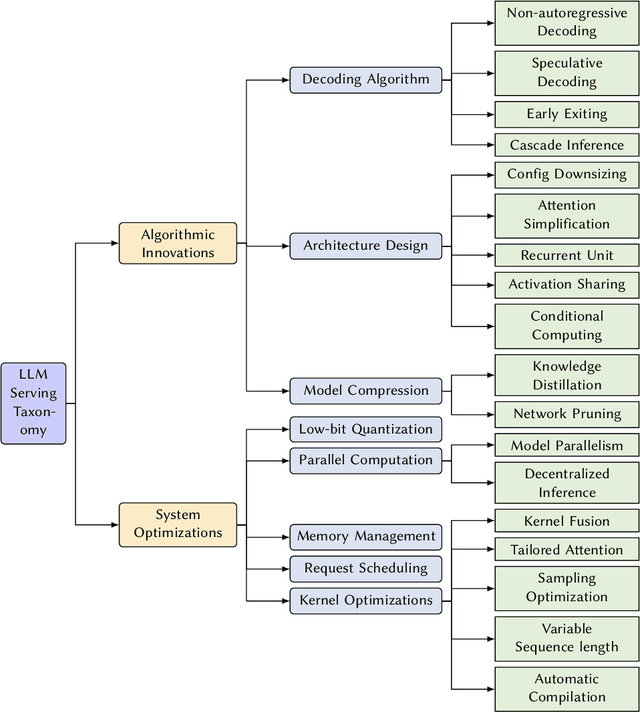
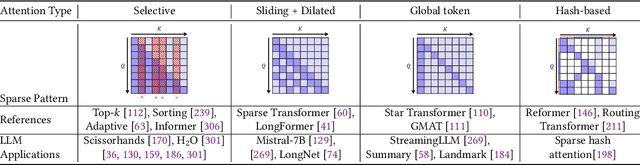
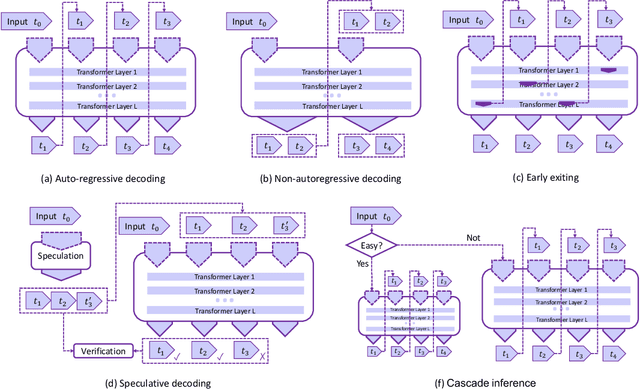

In the rapidly evolving landscape of artificial intelligence (AI), generative large language models (LLMs) stand at the forefront, revolutionizing how we interact with our data. However, the computational intensity and memory consumption of deploying these models present substantial challenges in terms of serving efficiency, particularly in scenarios demanding low latency and high throughput. This survey addresses the imperative need for efficient LLM serving methodologies from a machine learning system (MLSys) research perspective, standing at the crux of advanced AI innovations and practical system optimizations. We provide in-depth analysis, covering a spectrum of solutions, ranging from cutting-edge algorithmic modifications to groundbreaking changes in system designs. The survey aims to provide a comprehensive understanding of the current state and future directions in efficient LLM serving, offering valuable insights for researchers and practitioners in overcoming the barriers of effective LLM deployment, thereby reshaping the future of AI.
SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
May 16, 2023



The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. This paper introduces SpecInfer, an LLM serving system that accelerates generative LLM inference with speculative inference and token tree verification. A key insight behind SpecInfer is to combine various collectively boost-tuned small language models to jointly predict the LLM's outputs; the predictions are organized as a token tree, whose nodes each represent a candidate token sequence. The correctness of all candidate token sequences represented by a token tree is verified by the LLM in parallel using a novel tree-based parallel decoding mechanism. SpecInfer uses an LLM as a token tree verifier instead of an incremental decoder, which significantly reduces the end-to-end latency and computational requirement for serving generative LLMs while provably preserving model quality.