 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastKernels: Benchmarking GPU Kernel Generation in Production
May 22, 2026LLM-based agents for GPU kernel generation are advancing rapidly, yet their progress is fundamentally constrained by the benchmarks they optimize against. Existing benchmarks are poorly aligned with production inference frameworks: they evaluate kernels on a single GPU with synthetic inputs, ignore the surrounding compilation stack, and reward replicating known optimizations rather than discovering new ones. The resulting reward signals are misleading: agents learn to generate kernels that score well in sandboxes but introduce interface incompatibilities, compilation-stack conflicts, and silent correctness degradation when integrated into real systems. We introduce FastKernels, a kernel benchmark built around a minimal set of 46 representative architectures spanning 8 categories, whose kernels collectively subsume those of 96.2% (409/425) of HuggingFace Transformers architectures. FastKernels doubles as a minimalistic, production-grade inference framework that runs at parity with hardened systems such as vLLM and SGLang on mainstream LLM serving and substantially exceeds upstream references on under-served architectures; each task's interface mirrors the corresponding module in the state-of-the-art library for its architecture family, enabling direct deployment of optimized kernels into production codebases. Evaluating state-of-the-art kernel agents on FastKernels, we find that even the strongest agent achieves only 0.94$\times$ aggregate speedup over production baselines, with weaker agents at $0.78\times$ and $0.53\times$ -- confirming that benchmark-production misalignment is a critical bottleneck for the field. We release FastKernels as a stepping stone toward kernel agents whose benchmark gains translate directly into production throughput improvements. Code is available at https://github.com/Snowflake-AI-Research/fastkernels
Event Tensor: A Unified Abstraction for Compiling Dynamic Megakernel
Apr 14, 2026Modern GPU workloads, especially large language model (LLM) inference, suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. Recent megakernel techniques fuse multiple operators into a single persistent kernel to eliminate launch gaps and expose inter-kernel parallelism, but struggle to handle dynamic shapes and data-dependent computation in real workloads. We present Event Tensor, a unified compiler abstraction for dynamic megakernels. Event Tensor encodes dependencies between tiled tasks, and enables first-class support for both shape and data-dependent dynamism. Built atop this abstraction, our Event Tensor Compiler (ETC) applies static and dynamic scheduling transformations to generate high-performance persistent kernels. Evaluations show that ETC achieves state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
SpecReason: Fast and Accurate Inference-Time Compute via Speculative Reasoning
Apr 10, 2025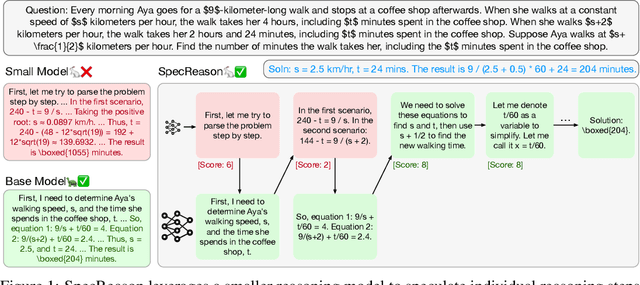

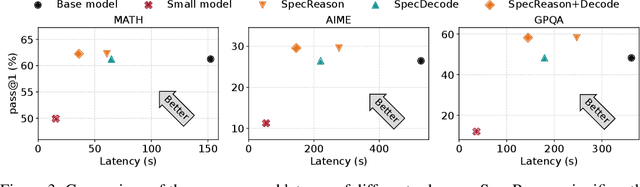
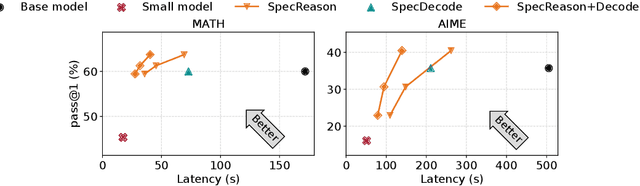
Recent advances in inference-time compute have significantly improved performance on complex tasks by generating long chains of thought (CoTs) using Large Reasoning Models (LRMs). However, this improved accuracy comes at the cost of high inference latency due to the length of generated reasoning sequences and the autoregressive nature of decoding. Our key insight in tackling these overheads is that LRM inference, and the reasoning that it embeds, is highly tolerant of approximations: complex tasks are typically broken down into simpler steps, each of which brings utility based on the semantic insight it provides for downstream steps rather than the exact tokens it generates. Accordingly, we introduce SpecReason, a system that automatically accelerates LRM inference by using a lightweight model to (speculatively) carry out simpler intermediate reasoning steps and reserving the costly base model only to assess (and potentially correct) the speculated outputs. Importantly, SpecReason's focus on exploiting the semantic flexibility of thinking tokens in preserving final-answer accuracy is complementary to prior speculation techniques, most notably speculative decoding, which demands token-level equivalence at each step. Across a variety of reasoning benchmarks, SpecReason achieves 1.5-2.5$\times$ speedup over vanilla LRM inference while improving accuracy by 1.0-9.9\%. Compared to speculative decoding without SpecReason, their combination yields an additional 19.4-44.2\% latency reduction. We open-source SpecReason at https://github.com/ruipeterpan/specreason.
AdaServe: SLO-Customized LLM Serving with Fine-Grained Speculative Decoding
Jan 21, 2025This paper introduces AdaServe, the first LLM serving system to support SLO customization through fine-grained speculative decoding. AdaServe leverages the logits of a draft model to predict the speculative accuracy of tokens and employs a theoretically optimal algorithm to construct token trees for verification. To accommodate diverse SLO requirements without compromising throughput, AdaServe employs a speculation-and-selection scheme that first constructs candidate token trees for each request and then dynamically selects tokens to meet individual SLO constraints while optimizing throughput. Comprehensive evaluations demonstrate that AdaServe achieves up to 73% higher SLO attainment and 74% higher goodput compared to state-of-the-art systems. These results underscore AdaServe's potential to enhance the efficiency and adaptability of LLM deployments across varied application scenarios.
SuffixDecoding: A Model-Free Approach to Speeding Up Large Language Model Inference
Nov 07, 2024
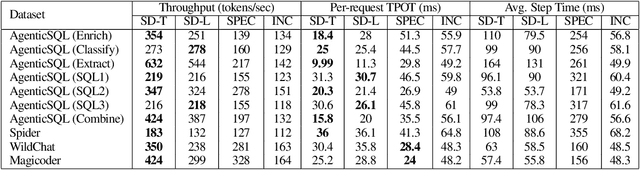


We present SuffixDecoding, a novel model-free approach to accelerating large language model (LLM) inference through speculative decoding. Unlike existing methods that rely on draft models or specialized decoding heads, SuffixDecoding leverages suffix trees built from previously generated outputs to efficiently predict candidate token sequences. Our approach enables flexible tree-structured speculation without the overhead of maintaining and orchestrating additional models. SuffixDecoding builds and dynamically updates suffix trees to capture patterns in the generated text, using them to construct speculation trees through a principled scoring mechanism based on empirical token frequencies. SuffixDecoding requires only CPU memory which is plentiful and underutilized on typical LLM serving nodes. We demonstrate that SuffixDecoding achieves competitive speedups compared to model-based approaches across diverse workloads including open-domain chat, code generation, and text-to-SQL tasks. For open-ended chat and code generation tasks, SuffixDecoding achieves up to $1.4\times$ higher output throughput than SpecInfer and up to $1.1\times$ lower time-per-token (TPOT) latency. For a proprietary multi-LLM text-to-SQL application, SuffixDecoding achieves up to $2.9\times$ higher output throughput and $3\times$ lower latency than speculative decoding. Our evaluation shows that SuffixDecoding maintains high acceptance rates even with small reference corpora of 256 examples, while continuing to improve performance as more historical outputs are incorporated.
Optimal Kernel Orchestration for Tensor Programs with Korch
Jun 13, 2024


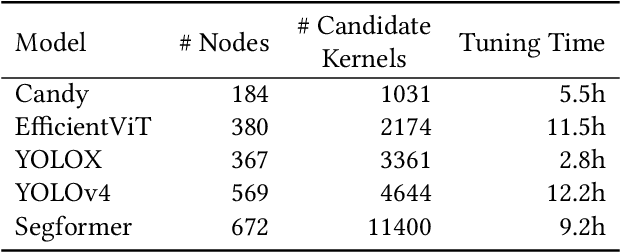
Kernel orchestration is the task of mapping the computation defined in different operators of a deep neural network (DNN) to the execution of GPU kernels on modern hardware platforms. Prior approaches optimize kernel orchestration by greedily applying operator fusion, which fuses the computation of multiple operators into a single kernel, and miss a variety of optimization opportunities in kernel orchestration. This paper presents Korch, a tensor program optimizer that discovers optimal kernel orchestration strategies for tensor programs. Instead of directly fusing operators, Korch first applies operator fission to decompose tensor operators into a small set of basic tensor algebra primitives. This decomposition enables a diversity of fine-grained, inter-operator optimizations. Next, Korch optimizes kernel orchestration by formalizing it as a constrained optimization problem, leveraging an off-the-shelf binary linear programming solver to discover an optimal orchestration strategy, and generating an executable that can be directly deployed on modern GPU platforms. Evaluation on a variety of DNNs shows that Korch outperforms existing tensor program optimizers by up to 1.7x on V100 GPUs and up to 1.6x on A100 GPUs. Korch is publicly available at https://github.com/humuyan/Korch.
* Fix some typos in the ASPLOS version
FlexLLM: A System for Co-Serving Large Language Model Inference and Parameter-Efficient Finetuning
Feb 29, 2024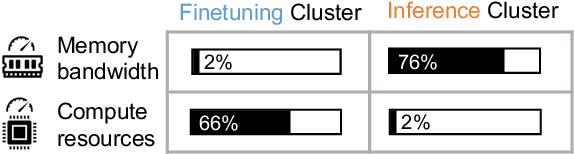
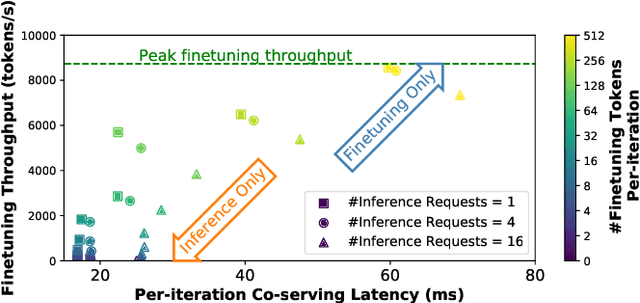

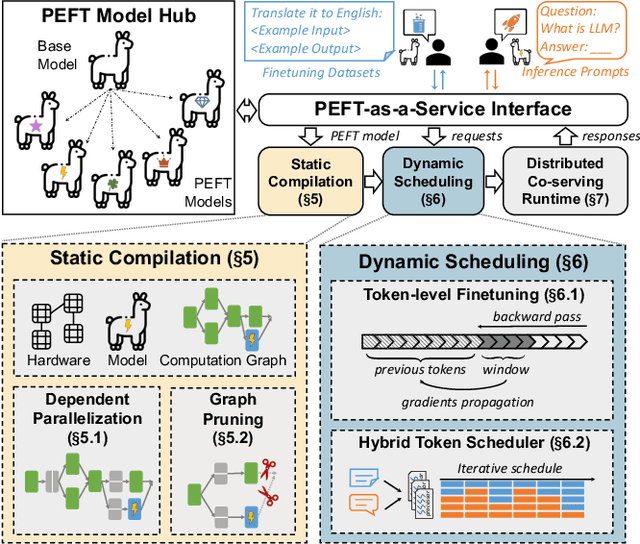
Parameter-efficient finetuning (PEFT) is a widely used technique to adapt large language models for different tasks. Service providers typically create separate systems for users to perform PEFT model finetuning and inference tasks. This is because existing systems cannot handle workloads that include a mix of inference and PEFT finetuning requests. As a result, shared GPU resources are underutilized, leading to inefficiencies. To address this problem, we present FlexLLM, the first system that can serve inference and parameter-efficient finetuning requests in the same iteration. Our system leverages the complementary nature of these two tasks and utilizes shared GPU resources to run them jointly, using a method called co-serving. To achieve this, FlexLLM introduces a novel token-level finetuning mechanism, which breaks down the finetuning computation of a sequence into smaller token-level computations and uses dependent parallelization and graph pruning, two static compilation optimizations, to minimize the memory overhead and latency for co-serving. Compared to existing systems, FlexLLM's co-serving approach reduces the activation GPU memory overhead by up to 8x, and the end-to-end GPU memory requirement of finetuning by up to 36% while maintaining a low inference latency and improving finetuning throughput. For example, under a heavy inference workload, FlexLLM can still preserve more than 80% of the peak finetuning throughput, whereas existing systems cannot make any progress with finetuning. The source code of FlexLLM is publicly available at https://github.com/flexflow/FlexFlow.
Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models
Jan 13, 2024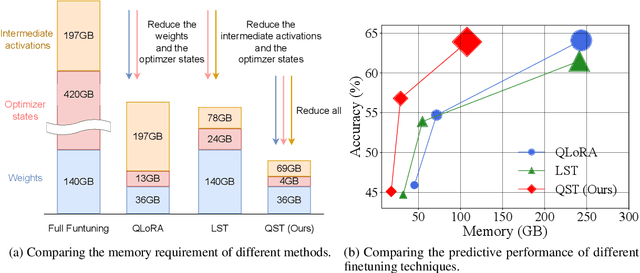
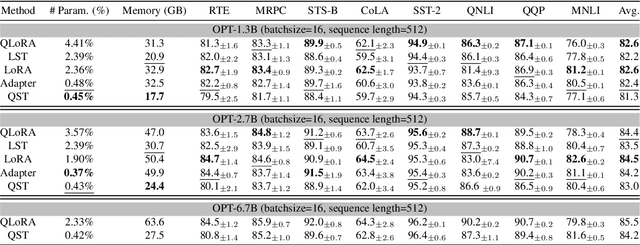
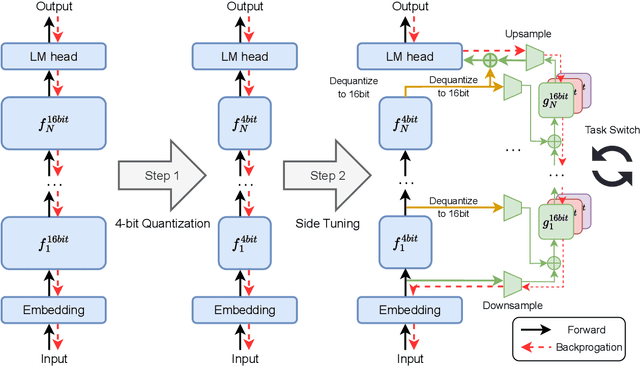

Finetuning large language models (LLMs) has been empirically effective on a variety of downstream tasks. Existing approaches to finetuning an LLM either focus on parameter-efficient finetuning, which only updates a small number of trainable parameters, or attempt to reduce the memory footprint during the training phase of the finetuning. Typically, the memory footprint during finetuning stems from three contributors: model weights, optimizer states, and intermediate activations. However, existing works still require considerable memory and none can simultaneously mitigate memory footprint for all three sources. In this paper, we present Quantized Side Tuing (QST), which enables memory-efficient and fast finetuning of LLMs by operating through a dual-stage process. First, QST quantizes an LLM's model weights into 4-bit to reduce the memory footprint of the LLM's original weights; QST also introduces a side network separated from the LLM, which utilizes the hidden states of the LLM to make task-specific predictions. Using a separate side network avoids performing backpropagation through the LLM, thus reducing the memory requirement of the intermediate activations. Furthermore, QST leverages several low-rank adaptors and gradient-free downsample modules to significantly reduce the trainable parameters, so as to save the memory footprint of the optimizer states. Experiments show that QST can reduce the total memory footprint by up to 2.3 $\times$ and speed up the finetuning process by up to 3 $\times$ while achieving competent performance compared with the state-of-the-art. When it comes to full finetuning, QST can reduce the total memory footprint up to 7 $\times$.
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems
Dec 23, 2023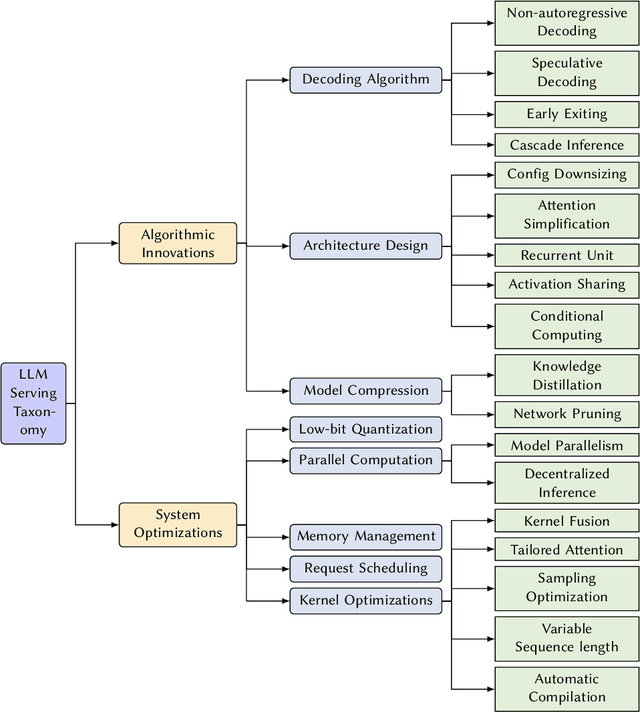
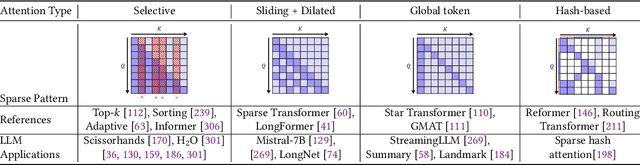
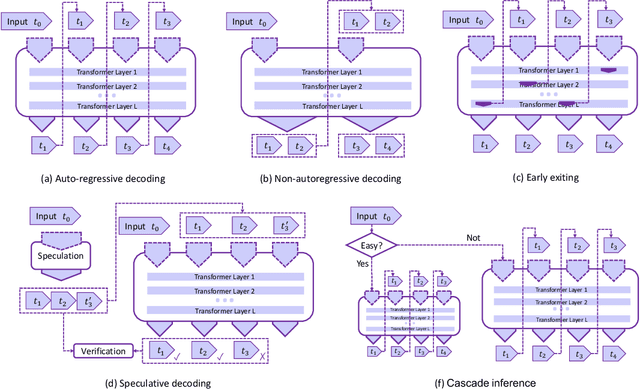

In the rapidly evolving landscape of artificial intelligence (AI), generative large language models (LLMs) stand at the forefront, revolutionizing how we interact with our data. However, the computational intensity and memory consumption of deploying these models present substantial challenges in terms of serving efficiency, particularly in scenarios demanding low latency and high throughput. This survey addresses the imperative need for efficient LLM serving methodologies from a machine learning system (MLSys) research perspective, standing at the crux of advanced AI innovations and practical system optimizations. We provide in-depth analysis, covering a spectrum of solutions, ranging from cutting-edge algorithmic modifications to groundbreaking changes in system designs. The survey aims to provide a comprehensive understanding of the current state and future directions in efficient LLM serving, offering valuable insights for researchers and practitioners in overcoming the barriers of effective LLM deployment, thereby reshaping the future of AI.
SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
May 16, 2023



The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. This paper introduces SpecInfer, an LLM serving system that accelerates generative LLM inference with speculative inference and token tree verification. A key insight behind SpecInfer is to combine various collectively boost-tuned small language models to jointly predict the LLM's outputs; the predictions are organized as a token tree, whose nodes each represent a candidate token sequence. The correctness of all candidate token sequences represented by a token tree is verified by the LLM in parallel using a novel tree-based parallel decoding mechanism. SpecInfer uses an LLM as a token tree verifier instead of an incremental decoder, which significantly reduces the end-to-end latency and computational requirement for serving generative LLMs while provably preserving model quality.