 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoral: Cost-Efficient Multi-LLM Serving over Heterogeneous Cloud GPUs
May 05, 2026The usage of large language models (LLMs) has grown increasingly fragmented, with no single model dominating. Meanwhile, cloud providers offer a wide range of mid-tier and older-generation GPUs that enjoy better availability and deliver comparable performance per dollar to top-tier hardware. To efficiently harness these heterogeneous resources for serving multiple LLMs concurrently, we introduce Coral, an adaptive heterogeneity-aware multi-LLM serving system. The key idea behind Coral is to jointly optimize resource allocation and the serving strategy of each model replica across all models. To keep pace with shifting throughput demand and resource availability, Coral applies a lossless two-stage decomposition that preserves joint optimality while cutting online solve time from hours to tens of seconds. Our evaluation across 6 models and 20 GPU configurations shows that Coral reduces serving cost by up to 2.79$\times$ over the best baseline, and delivers up to 2.39$\times$ higher goodput under scarce resource availability.
Prism: Symbolic Superoptimization of Tensor Programs
Apr 16, 2026This paper presents Prism, the first symbolic superoptimizer for tensor programs. The key idea is sGraph, a symbolic, hierarchical representation that compactly encodes large classes of tensor programs by symbolically representing some execution parameters. Prism organizes optimization as a two-level search: it constructs symbolic graphs that represent families of programs, and then instantiates them into concrete implementations. This formulation enables structured pruning of provably suboptimal regions of the search space using symbolic reasoning over operator semantics, algebraic identities, and hardware constraints. We develop techniques for efficient symbolic graph generation, equivalence verification via e-graph rewriting, and parameter instantiation through auto-tuning. Together, these components allow Prism to bridge the rigor of exhaustive search with the scalability required for modern ML workloads. Evaluation on five commonly used LLM workloads shows that Prism achieves up to $2.2\times$ speedup over best superoptimizers and $4.9\times$ over best compiler-based approaches, while reducing end-to-end optimization time by up to $3.4\times$.
Mirage Persistent Kernel: A Compiler and Runtime for Mega-Kernelizing Tensor Programs
Dec 22, 2025We introduce Mirage Persistent Kernel (MPK), the first compiler and runtime system that automatically transforms multi-GPU model inference into a single high-performance megakernel. MPK introduces an SM-level graph representation that captures data dependencies at the granularity of individual streaming multiprocessors (SMs), enabling cross-operator software pipelining, fine-grained kernel overlap, and other previously infeasible GPU optimizations. The MPK compiler lowers tensor programs into highly optimized SM-level task graphs and generates optimized CUDA implementations for all tasks, while the MPK in-kernel parallel runtime executes these tasks within a single mega-kernel using decentralized scheduling across SMs. Together, these components provide end-to-end kernel fusion with minimal developer effort, while preserving the flexibility of existing programming models. Our evaluation shows that MPK significantly outperforms existing kernel-per-operator LLM serving systems by reducing end-to-end inference latency by up to 1.7x, pushing LLM inference performance close to hardware limits. MPK is publicly available at https://github.com/mirage-project/mirage.
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024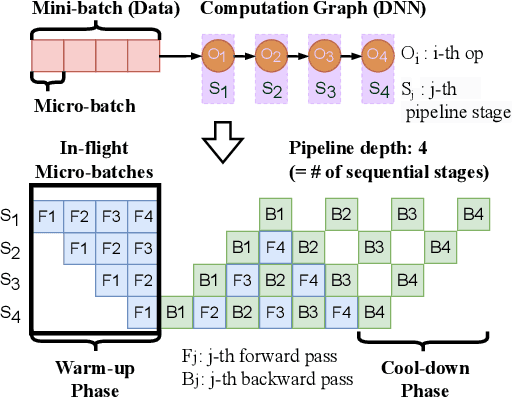

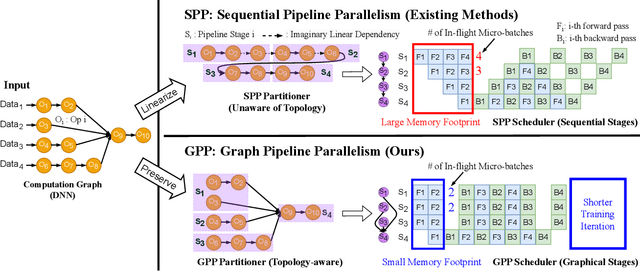
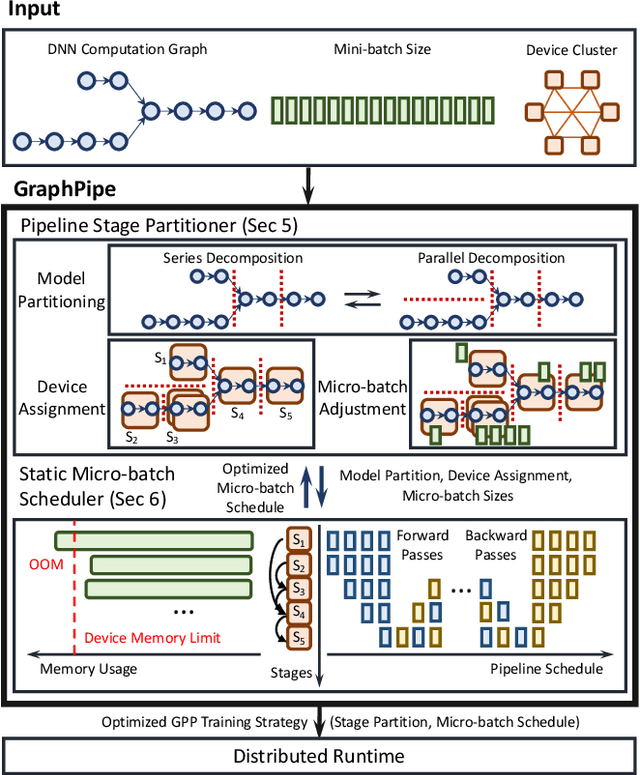
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
A Multi-Level Superoptimizer for Tensor Programs
May 09, 2024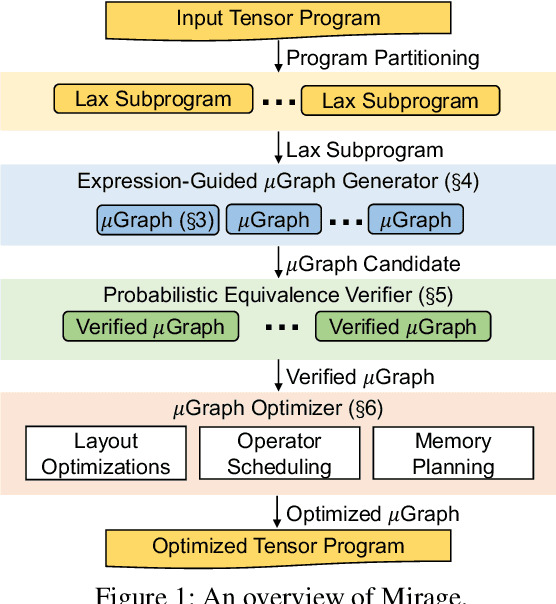

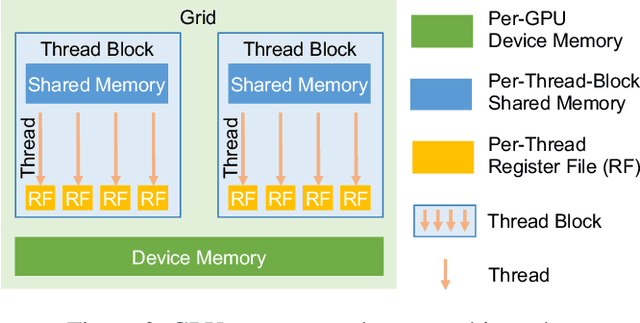

We introduce Mirage, the first multi-level superoptimizer for tensor programs. A key idea in Mirage is $\mu$Graphs, a uniform representation of tensor programs at the kernel, thread block, and thread levels of the GPU compute hierarchy. $\mu$Graphs enable Mirage to discover novel optimizations that combine algebraic transformations, schedule transformations, and generation of new custom kernels. To navigate the large search space, Mirage introduces a pruning technique based on abstraction that significantly reduces the search space and provides a certain optimality guarantee. To ensure that the optimized $\mu$Graph is equivalent to the input program, Mirage introduces a probabilistic equivalence verification procedure with strong theoretical guarantees. Our evaluation shows that Mirage outperforms existing approaches by up to 3.5$\times$ even for DNNs that are widely used and heavily optimized. Mirage is publicly available at https://github.com/mirage-project/mirage.
FlexLLM: A System for Co-Serving Large Language Model Inference and Parameter-Efficient Finetuning
Feb 29, 2024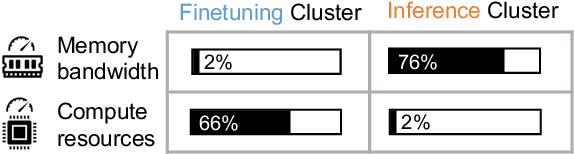
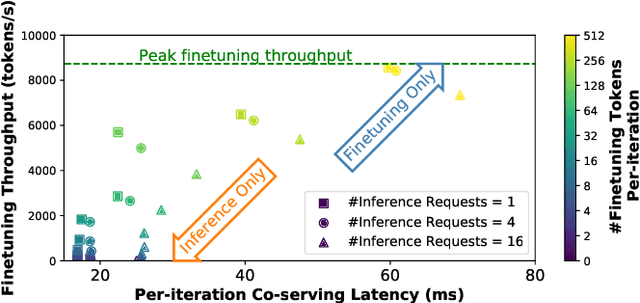

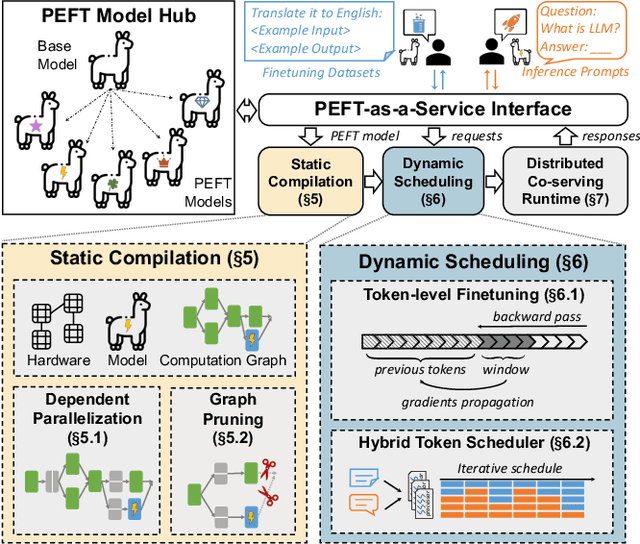
Parameter-efficient finetuning (PEFT) is a widely used technique to adapt large language models for different tasks. Service providers typically create separate systems for users to perform PEFT model finetuning and inference tasks. This is because existing systems cannot handle workloads that include a mix of inference and PEFT finetuning requests. As a result, shared GPU resources are underutilized, leading to inefficiencies. To address this problem, we present FlexLLM, the first system that can serve inference and parameter-efficient finetuning requests in the same iteration. Our system leverages the complementary nature of these two tasks and utilizes shared GPU resources to run them jointly, using a method called co-serving. To achieve this, FlexLLM introduces a novel token-level finetuning mechanism, which breaks down the finetuning computation of a sequence into smaller token-level computations and uses dependent parallelization and graph pruning, two static compilation optimizations, to minimize the memory overhead and latency for co-serving. Compared to existing systems, FlexLLM's co-serving approach reduces the activation GPU memory overhead by up to 8x, and the end-to-end GPU memory requirement of finetuning by up to 36% while maintaining a low inference latency and improving finetuning throughput. For example, under a heavy inference workload, FlexLLM can still preserve more than 80% of the peak finetuning throughput, whereas existing systems cannot make any progress with finetuning. The source code of FlexLLM is publicly available at https://github.com/flexflow/FlexFlow.
Finding the Task-Optimal Low-Bit Sub-Distribution in Deep Neural Networks
Jan 13, 2022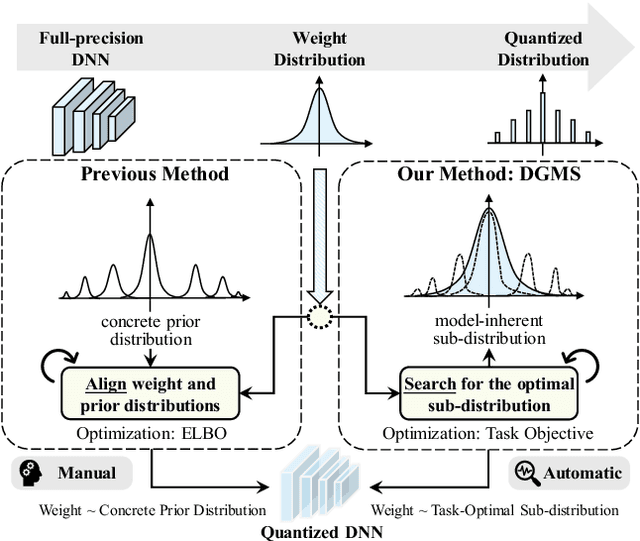
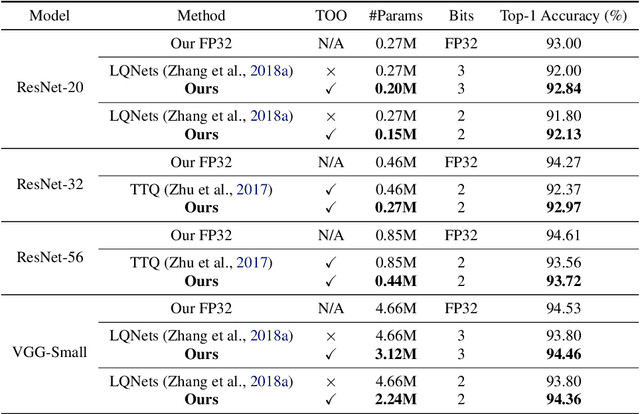
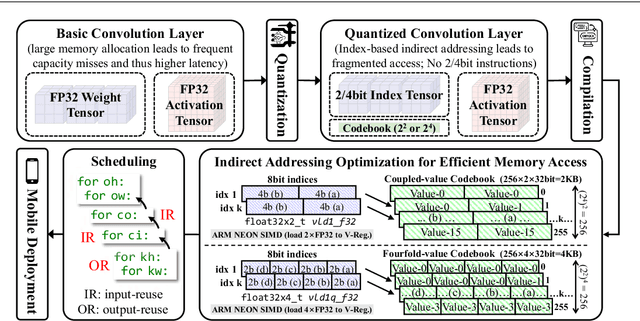
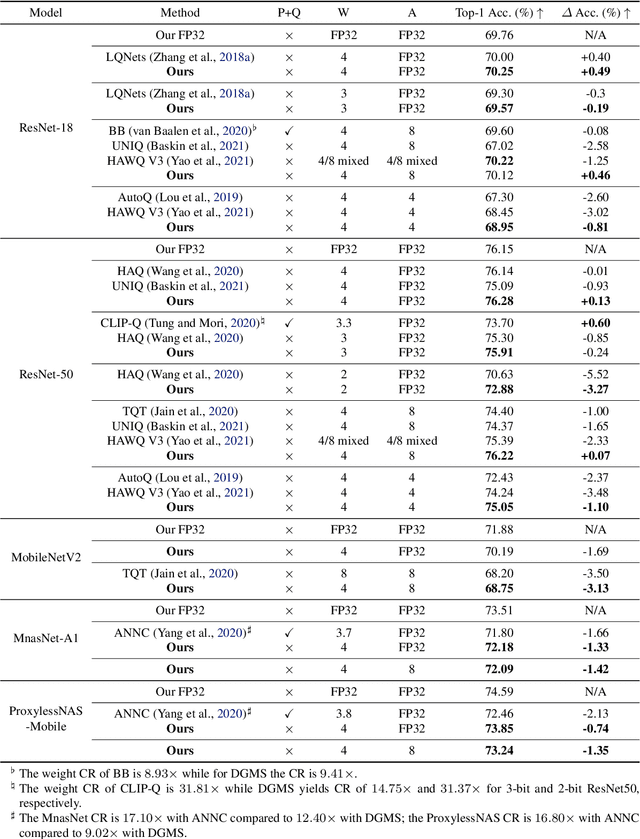
Quantized neural networks typically require smaller memory footprints and lower computation complexity, which is crucial for efficient deployment. However, quantization inevitably leads to a distribution divergence from the original network, which generally degrades the performance. To tackle this issue, massive efforts have been made, but most existing approaches lack statistical considerations and depend on several manual configurations. In this paper, we present an adaptive-mapping quantization method to learn an optimal latent sub-distribution that is inherent within models and smoothly approximated with a concrete Gaussian Mixture (GM). In particular, the network weights are projected in compliance with the GM-approximated sub-distribution. This sub-distribution evolves along with the weight update in a co-tuning schema guided by the direct task-objective optimization. Sufficient experiments on image classification and object detection over various modern architectures demonstrate the effectiveness, generalization property, and transferability of the proposed method. Besides, an efficient deployment flow for the mobile CPU is developed, achieving up to 7.46$\times$ inference acceleration on an octa-core ARM CPU. Codes have been publicly released on Github (https://github.com/RunpeiDong/DGMS).