 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024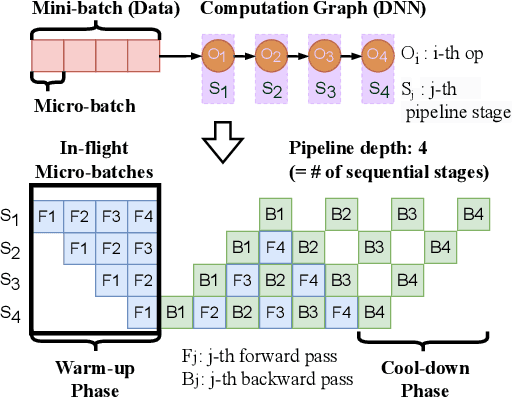

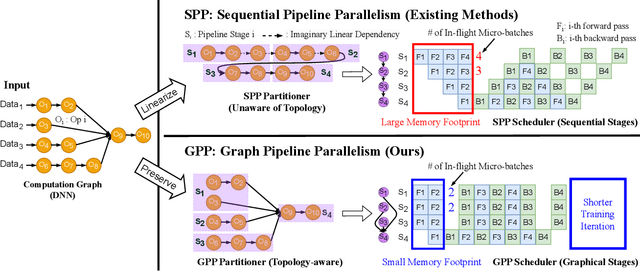
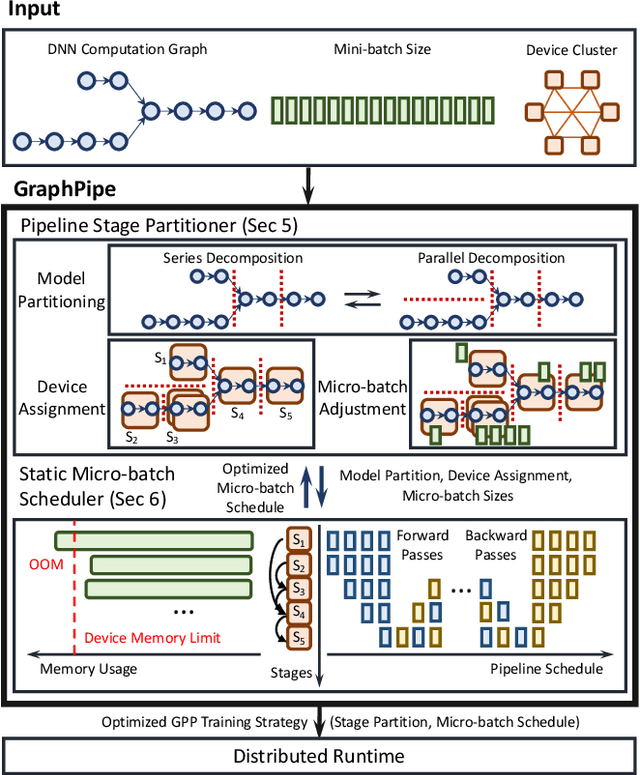
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
Collage: Automated Integration of Deep Learning Backends
Nov 01, 2021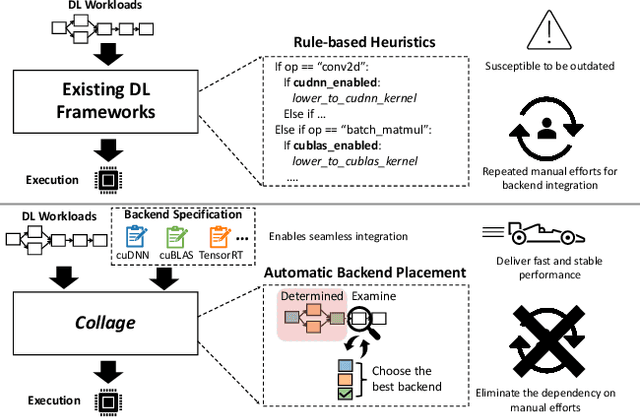
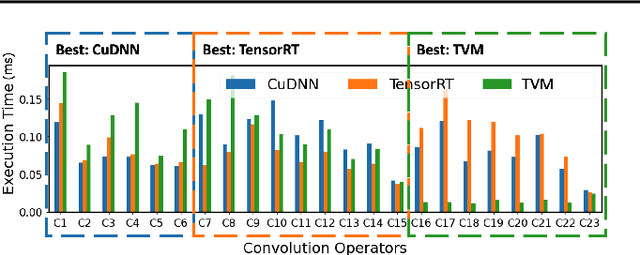
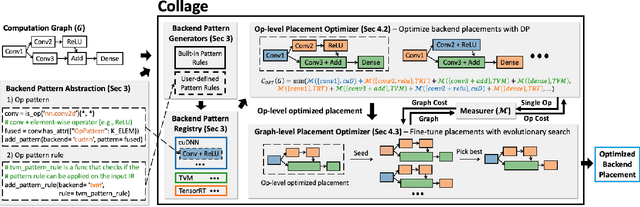
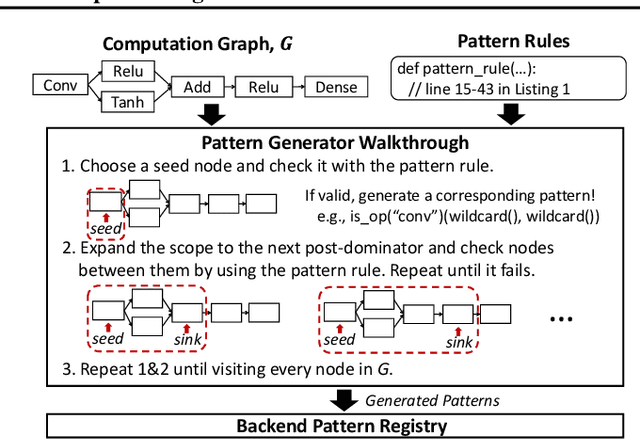
Strong demands for efficient deployment of Deep Learning (DL) applications prompt the rapid development of a rich DL ecosystem. To keep up with its fast advancement, it is crucial for DL frameworks to efficiently integrate a variety of optimized libraries and runtimes as their backends and generate the fastest possible executable by using them properly. However, current DL frameworks require significant manual effort to integrate diverse backends and often fail to deliver high performance. In this paper, we propose Collage, an automatic framework for integrating DL backends. Collage provides a backend registration interface that allows users to precisely specify the capability of various backends. By leveraging the specifications of available backends, Collage searches for an optimized backend placement for a given workload and execution environment. Our evaluation shows that Collage automatically integrates multiple backends together without manual intervention, and outperforms existing frameworks by 1.21x, 1.39x, 1.40x on two different NVIDIA GPUs and an Intel CPU respectively.
Dropout Prediction over Weeks in MOOCs by Learning Representations of Clicks and Videos
Feb 05, 2020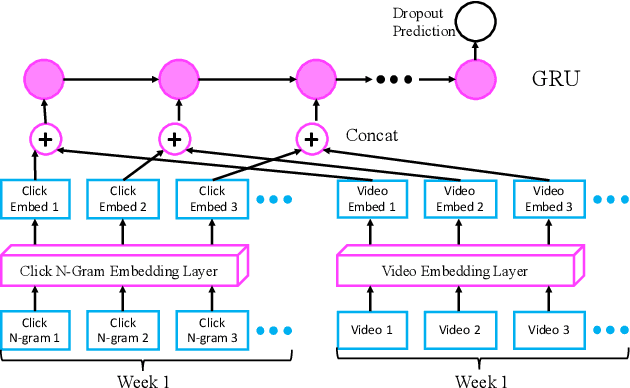

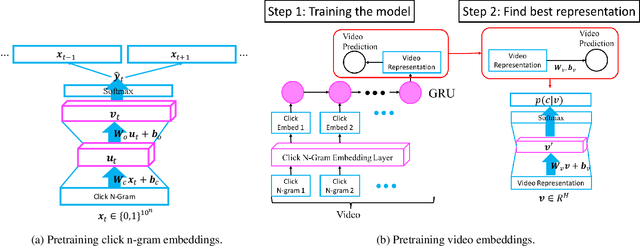
This paper addresses a key challenge in MOOC dropout prediction, namely to build meaningful representations from clickstream data. While a variety of feature extraction techniques have been explored extensively for such purposes, to our knowledge, no prior works have explored modeling of educational content (e.g. video) and their correlation with the learner's behavior (e.g. clickstream) in this context. We bridge this gap by devising a method to learn representation for videos and the correlation between videos and clicks. The results indicate that modeling videos and their correlation with clicks bring statistically significant improvements in predicting dropout.
Dropout Prediction over Weeks in MOOCs via Interpretable Multi-Layer Representation Learning
Feb 05, 2020
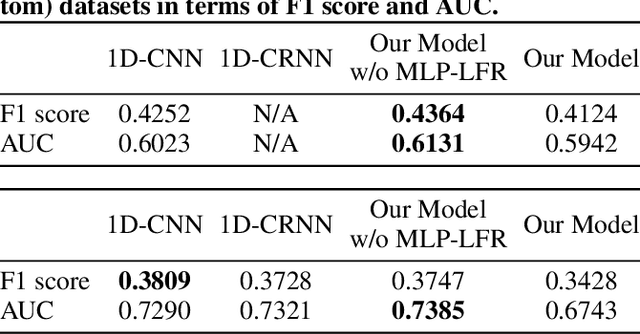
Massive Open Online Courses (MOOCs) have become popular platforms for online learning. While MOOCs enable students to study at their own pace, this flexibility makes it easy for students to drop out of class. In this paper, our goal is to predict if a learner is going to drop out within the next week, given clickstream data for the current week. To this end, we present a multi-layer representation learning solution based on branch and bound (BB) algorithm, which learns from low-level clickstreams in an unsupervised manner, produces interpretable results, and avoids manual feature engineering. In experiments on Coursera data, we show that our model learns a representation that allows a simple model to perform similarly well to more complex, task-specific models, and how the BB algorithm enables interpretable results. In our analysis of the observed limitations, we discuss promising future directions.
Time-series Insights into the Process of Passing or Failing Online University Courses using Neural-Induced Interpretable Student States
May 01, 2019



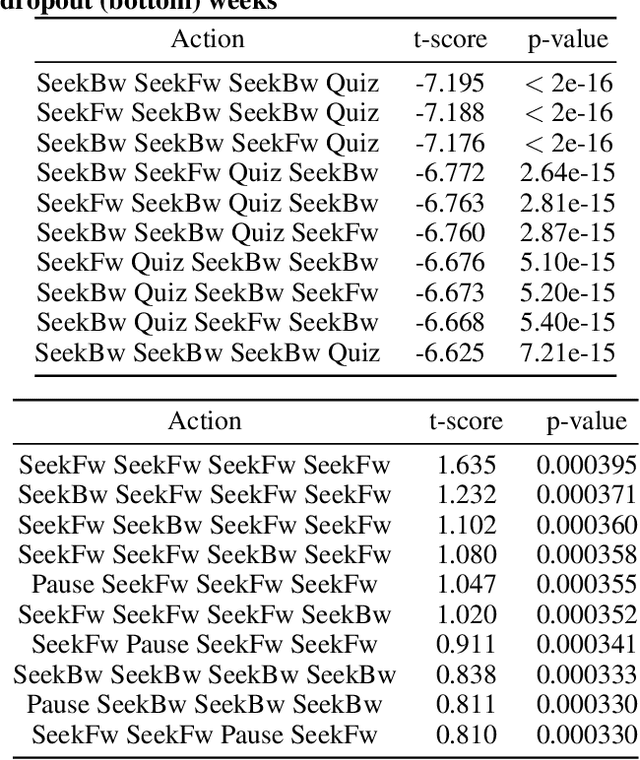
This paper addresses a key challenge in Educational Data Mining, namely to model student behavioral trajectories in order to provide a means for identifying students most at-risk, with the goal of providing supportive interventions. While many forms of data including clickstream data or data from sensors have been used extensively in time series models for such purposes, in this paper we explore the use of textual data, which is sometimes available in the records of students at large, online universities. We propose a time series model that constructs an evolving student state representation using both clickstream data and a signal extracted from the textual notes recorded by human mentors assigned to each student. We explore how the addition of this textual data improves both the predictive power of student states for the purpose of identifying students at risk for course failure as well as for providing interpretable insights about student course engagement processes.
Attentive Interaction Model: Modeling Changes in View in Argumentation
Apr 18, 2018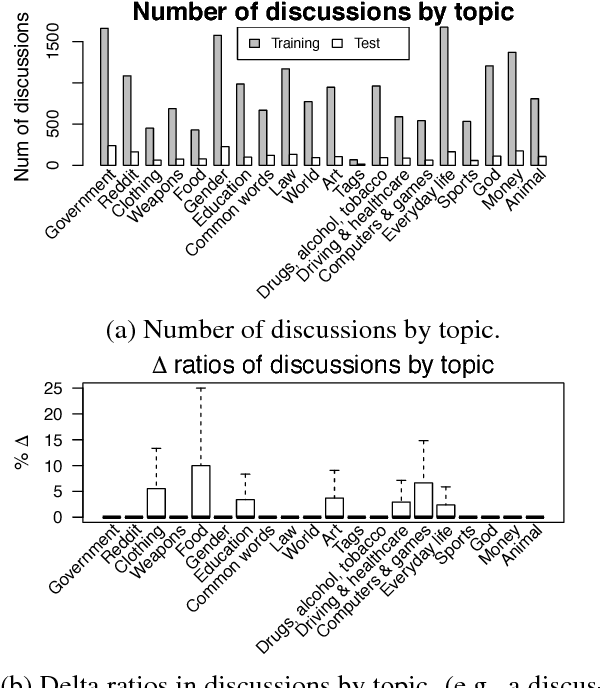
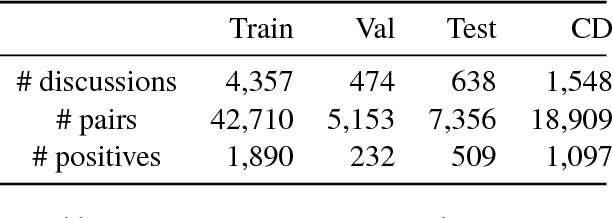
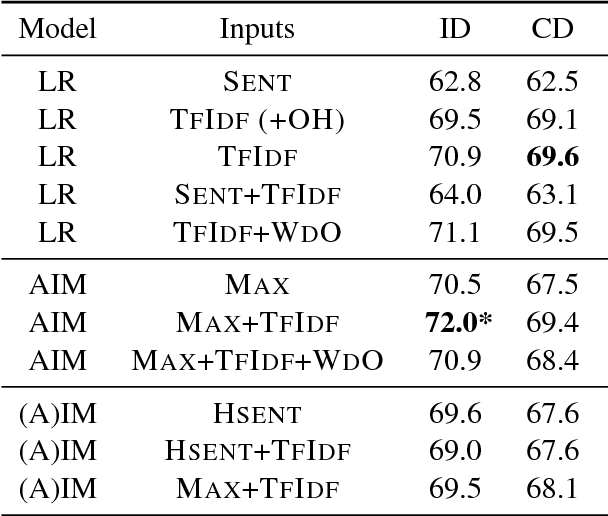
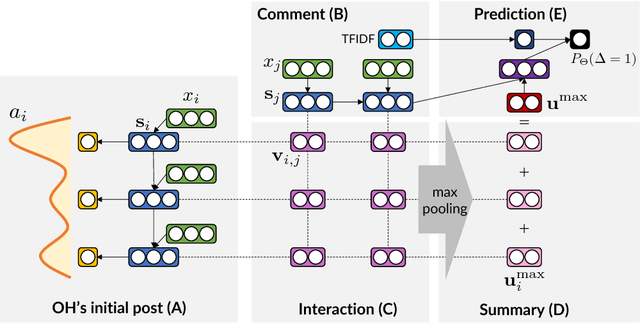
We present a neural architecture for modeling argumentative dialogue that explicitly models the interplay between an Opinion Holder's (OH's) reasoning and a challenger's argument, with the goal of predicting if the argument successfully changes the OH's view. The model has two components: (1) vulnerable region detection, an attention model that identifies parts of the OH's reasoning that are amenable to change, and (2) interaction encoding, which identifies the relationship between the content of the OH's reasoning and that of the challenger's argument. Based on evaluation on discussions from the Change My View forum on Reddit, the two components work together to predict an OH's change in view, outperforming several baselines. A posthoc analysis suggests that sentences picked out by the attention model are addressed more frequently by successful arguments than by unsuccessful ones.