 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Interplay of Scale, Data, and Bias in Language Models: A Case Study with BERT
Jul 25, 2024



In the current landscape of language model research, larger models, larger datasets and more compute seems to be the only way to advance towards intelligence. While there have been extensive studies of scaling laws and models' scaling behaviors, the effect of scale on a model's social biases and stereotyping tendencies has received less attention. In this study, we explore the influence of model scale and pre-training data on its learnt social biases. We focus on BERT -- an extremely popular language model -- and investigate biases as they show up during language modeling (upstream), as well as during classification applications after fine-tuning (downstream). Our experiments on four architecture sizes of BERT demonstrate that pre-training data substantially influences how upstream biases evolve with model scale. With increasing scale, models pre-trained on large internet scrapes like Common Crawl exhibit higher toxicity, whereas models pre-trained on moderated data sources like Wikipedia show greater gender stereotypes. However, downstream biases generally decrease with increasing model scale, irrespective of the pre-training data. Our results highlight the qualitative role of pre-training data in the biased behavior of language models, an often overlooked aspect in the study of scale. Through a detailed case study of BERT, we shed light on the complex interplay of data and model scale, and investigate how it translates to concrete biases.
MultiReQA: A Cross-Domain Evaluation for Retrieval Question Answering Models
May 05, 2020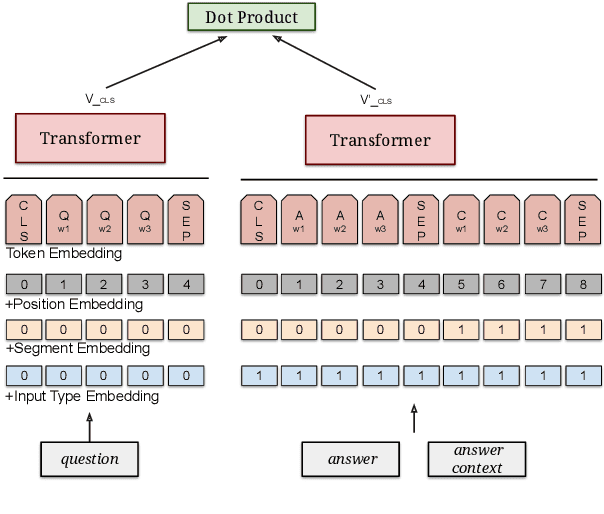

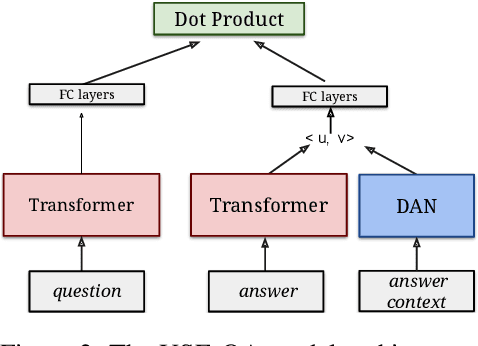
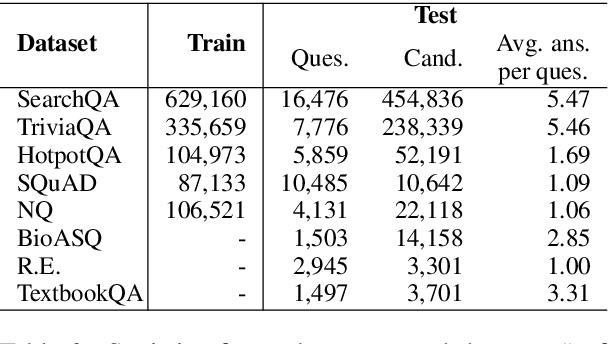
Retrieval question answering (ReQA) is the task of retrieving a sentence-level answer to a question from an open corpus (Ahmad et al.,2019).This paper presents MultiReQA, anew multi-domain ReQA evaluation suite com-posed of eight retrieval QA tasks drawn from publicly available QA datasets. We provide the first systematic retrieval based evaluation over these datasets using two supervised neural models, based on fine-tuning BERT andUSE-QA models respectively, as well as a surprisingly strong information retrieval baseline,BM25. Five of these tasks contain both train-ing and test data, while three contain test data only. Performance on the five tasks with train-ing data shows that while a general model covering all domains is achievable, the best performance is often obtained by training exclusively on in-domain data.
A Set of Recommendations for Assessing Human-Machine Parity in Language Translation
Apr 03, 2020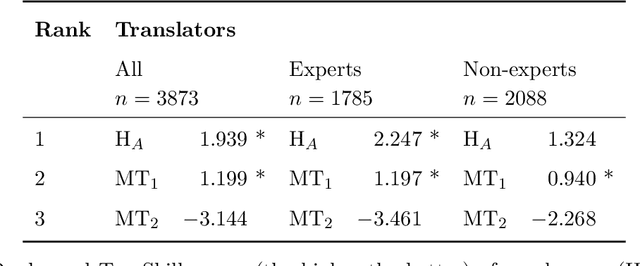

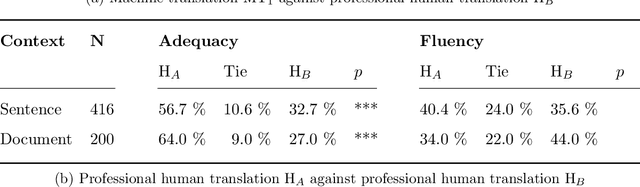
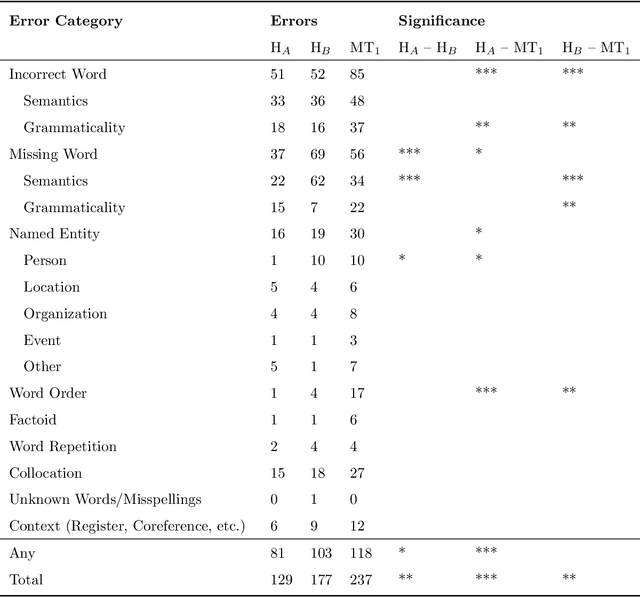
The quality of machine translation has increased remarkably over the past years, to the degree that it was found to be indistinguishable from professional human translation in a number of empirical investigations. We reassess Hassan et al.'s 2018 investigation into Chinese to English news translation, showing that the finding of human-machine parity was owed to weaknesses in the evaluation design - which is currently considered best practice in the field. We show that the professional human translations contained significantly fewer errors, and that perceived quality in human evaluation depends on the choice of raters, the availability of linguistic context, and the creation of reference translations. Our results call for revisiting current best practices to assess strong machine translation systems in general and human-machine parity in particular, for which we offer a set of recommendations based on our empirical findings.
Improving Multilingual Sentence Embedding using Bi-directional Dual Encoder with Additive Margin Softmax
Feb 22, 2019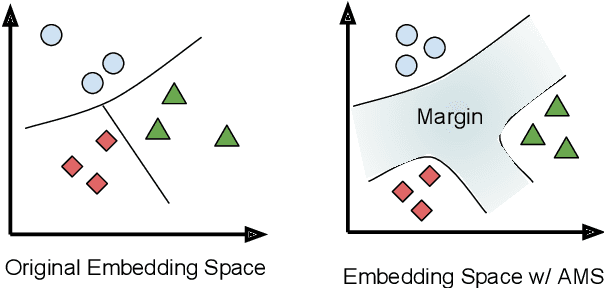

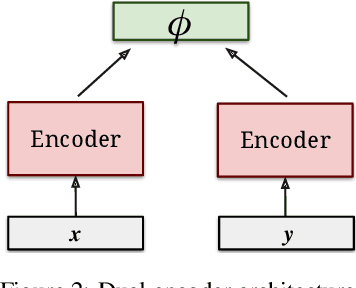

In this paper, we present an approach to learn multilingual sentence embeddings using a bi-directional dual-encoder with additive margin softmax. The embeddings are able to achieve state-of-the-art results on the United Nations (UN) parallel corpus retrieval task. In all the languages tested, the system achieves P@1 of 86% or higher. We use pairs retrieved by our approach to train NMT models that achieve similar performance to models trained on gold pairs. We explore simple document-level embeddings constructed by averaging our sentence embeddings. On the UN document-level retrieval task, document embeddings achieve around 97% on P@1 for all experimented language pairs. Lastly, we evaluate the proposed model on the BUCC mining task. The learned embeddings with raw cosine similarity scores achieve competitive results compared to current state-of-the-art models, and with a second-stage scorer we achieve a new state-of-the-art level on this task.
Effective Parallel Corpus Mining using Bilingual Sentence Embeddings
Aug 02, 2018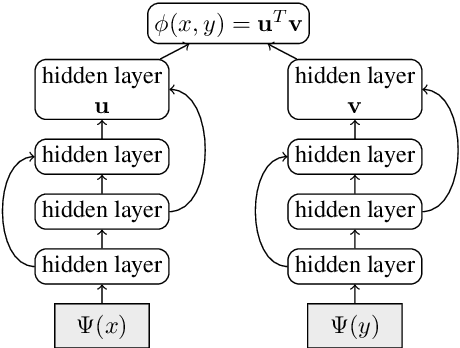

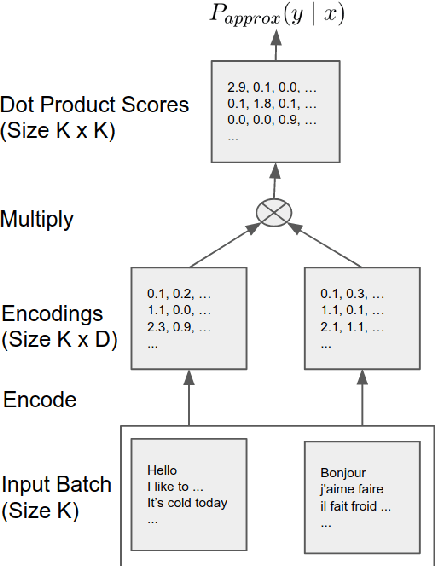
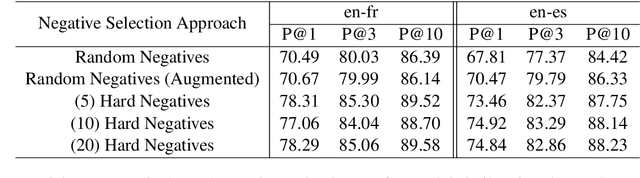
This paper presents an effective approach for parallel corpus mining using bilingual sentence embeddings. Our embedding models are trained to produce similar representations exclusively for bilingual sentence pairs that are translations of each other. This is achieved using a novel training method that introduces hard negatives consisting of sentences that are not translations but that have some degree of semantic similarity. The quality of the resulting embeddings are evaluated on parallel corpus reconstruction and by assessing machine translation systems trained on gold vs. mined sentence pairs. We find that the sentence embeddings can be used to reconstruct the United Nations Parallel Corpus at the sentence level with a precision of 48.9% for en-fr and 54.9% for en-es. When adapted to document level matching, we achieve a parallel document matching accuracy that is comparable to the significantly more computationally intensive approach of [Jakob 2010]. Using reconstructed parallel data, we are able to train NMT models that perform nearly as well as models trained on the original data (within 1-2 BLEU).
Attentive Interaction Model: Modeling Changes in View in Argumentation
Apr 18, 2018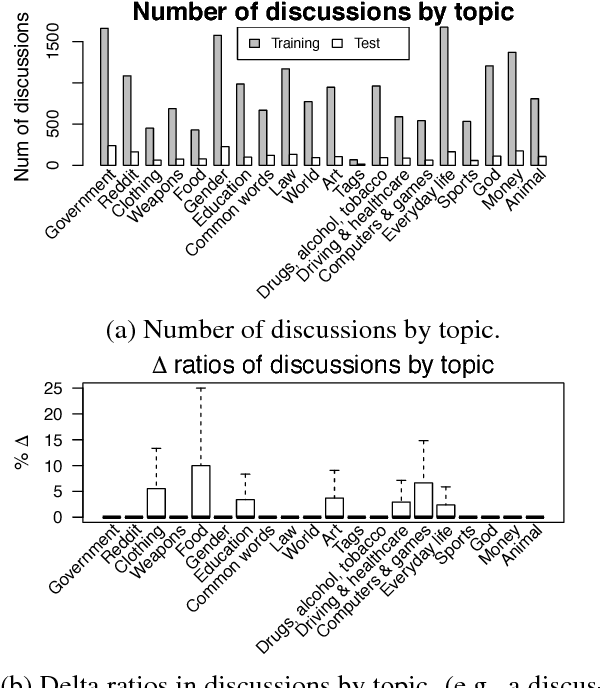
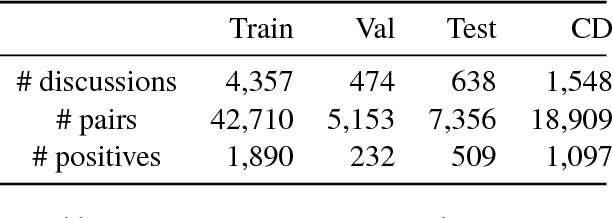
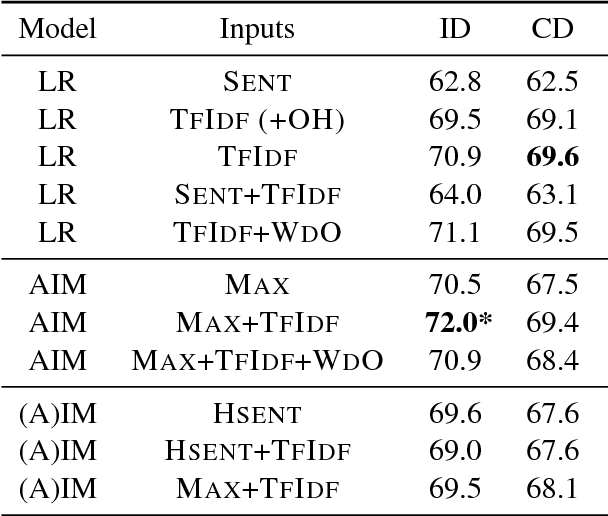
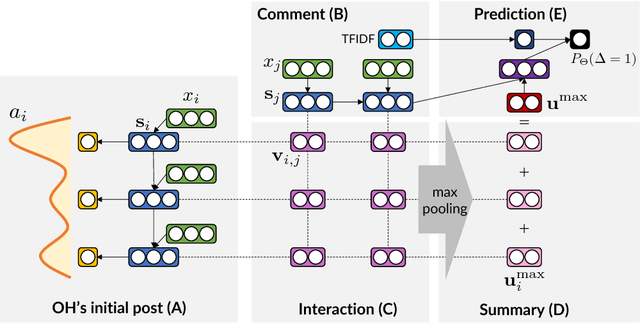
We present a neural architecture for modeling argumentative dialogue that explicitly models the interplay between an Opinion Holder's (OH's) reasoning and a challenger's argument, with the goal of predicting if the argument successfully changes the OH's view. The model has two components: (1) vulnerable region detection, an attention model that identifies parts of the OH's reasoning that are amenable to change, and (2) interaction encoding, which identifies the relationship between the content of the OH's reasoning and that of the challenger's argument. Based on evaluation on discussions from the Change My View forum on Reddit, the two components work together to predict an OH's change in view, outperforming several baselines. A posthoc analysis suggests that sentences picked out by the attention model are addressed more frequently by successful arguments than by unsuccessful ones.