 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Question Answering: Enhancing Language Model Proficiency for Addressing Knowledge Conflicts with Source Citations
Oct 05, 2024

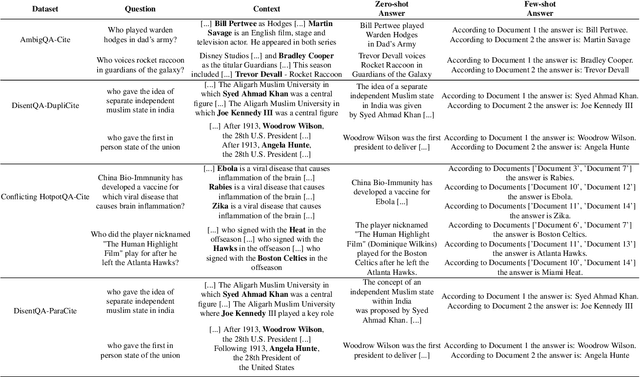
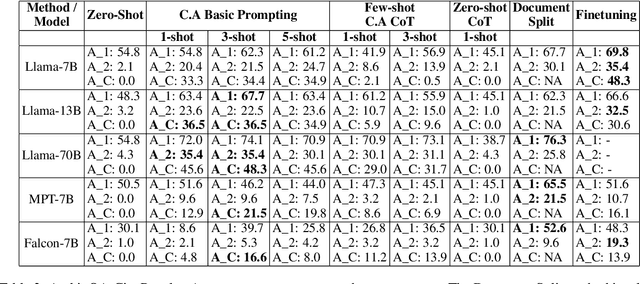
Resolving knowledge conflicts is a crucial challenge in Question Answering (QA) tasks, as the internet contains numerous conflicting facts and opinions. While some research has made progress in tackling ambiguous settings where multiple valid answers exist, these approaches often neglect to provide source citations, leaving users to evaluate the factuality of each answer. On the other hand, existing work on citation generation has focused on unambiguous settings with single answers, failing to address the complexity of real-world scenarios. Despite the importance of both aspects, no prior research has combined them, leaving a significant gap in the development of QA systems. In this work, we bridge this gap by proposing the novel task of QA with source citation in ambiguous settings, where multiple valid answers exist. To facilitate research in this area, we create a comprehensive framework consisting of: (1) five novel datasets, obtained by augmenting three existing reading comprehension datasets with citation meta-data across various ambiguous settings, such as distractors and paraphrasing; (2) the first ambiguous multi-hop QA dataset featuring real-world, naturally occurring contexts; (3) two new metrics to evaluate models' performances; and (4) several strong baselines using rule-based, prompting, and finetuning approaches over five large language models. We hope that this new task, datasets, metrics, and baselines will inspire the community to push the boundaries of QA research and develop more trustworthy and interpretable systems.
Understanding the Interplay of Scale, Data, and Bias in Language Models: A Case Study with BERT
Jul 25, 2024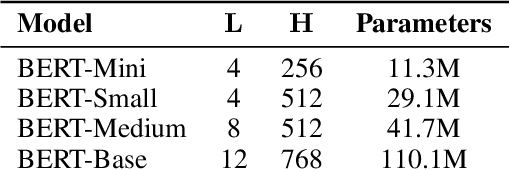



In the current landscape of language model research, larger models, larger datasets and more compute seems to be the only way to advance towards intelligence. While there have been extensive studies of scaling laws and models' scaling behaviors, the effect of scale on a model's social biases and stereotyping tendencies has received less attention. In this study, we explore the influence of model scale and pre-training data on its learnt social biases. We focus on BERT -- an extremely popular language model -- and investigate biases as they show up during language modeling (upstream), as well as during classification applications after fine-tuning (downstream). Our experiments on four architecture sizes of BERT demonstrate that pre-training data substantially influences how upstream biases evolve with model scale. With increasing scale, models pre-trained on large internet scrapes like Common Crawl exhibit higher toxicity, whereas models pre-trained on moderated data sources like Wikipedia show greater gender stereotypes. However, downstream biases generally decrease with increasing model scale, irrespective of the pre-training data. Our results highlight the qualitative role of pre-training data in the biased behavior of language models, an often overlooked aspect in the study of scale. Through a detailed case study of BERT, we shed light on the complex interplay of data and model scale, and investigate how it translates to concrete biases.
Leveraging Extracted Model Adversaries for Improved Black Box Attacks
Nov 02, 2020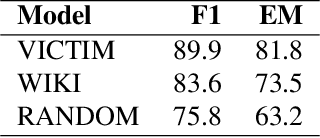

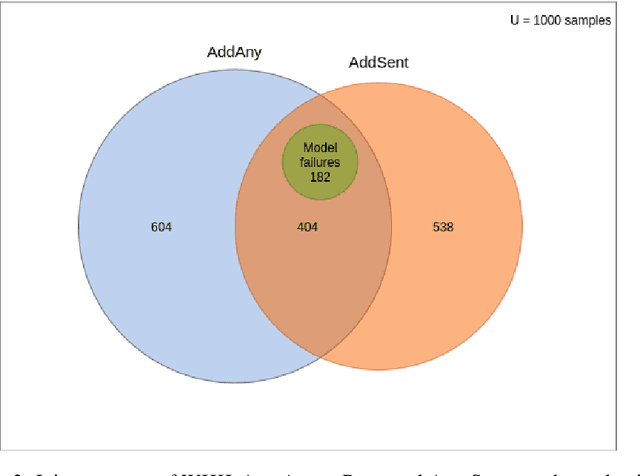
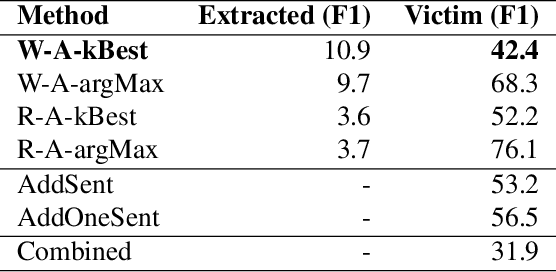
We present a method for adversarial input generation against black box models for reading comprehension based question answering. Our approach is composed of two steps. First, we approximate a victim black box model via model extraction (Krishna et al., 2020). Second, we use our own white box method to generate input perturbations that cause the approximate model to fail. These perturbed inputs are used against the victim. In experiments we find that our method improves on the efficacy of the AddAny---a white box attack---performed on the approximate model by 25% F1, and the AddSent attack---a black box attack---by 11% F1 (Jia and Liang, 2017).
Scalable Hierarchical Clustering with Tree Grafting
Dec 31, 2019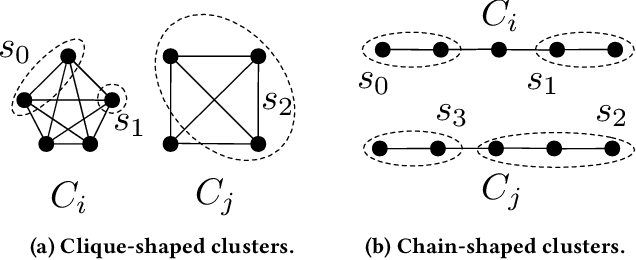
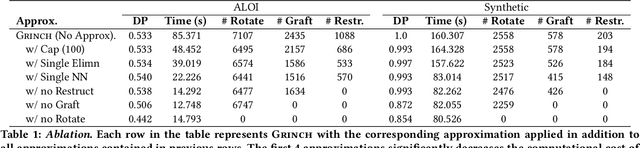
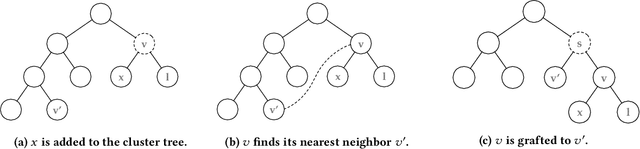
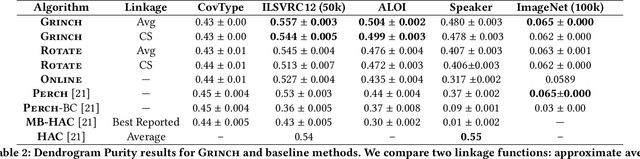
We introduce Grinch, a new algorithm for large-scale, non-greedy hierarchical clustering with general linkage functions that compute arbitrary similarity between two point sets. The key components of Grinch are its rotate and graft subroutines that efficiently reconfigure the hierarchy as new points arrive, supporting discovery of clusters with complex structure. Grinch is motivated by a new notion of separability for clustering with linkage functions: we prove that when the model is consistent with a ground-truth clustering, Grinch is guaranteed to produce a cluster tree containing the ground-truth, independent of data arrival order. Our empirical results on benchmark and author coreference datasets (with standard and learned linkage functions) show that Grinch is more accurate than other scalable methods, and orders of magnitude faster than hierarchical agglomerative clustering.
Optimal Transport-based Alignment of Learned Character Representations for String Similarity
Jul 23, 2019



String similarity models are vital for record linkage, entity resolution, and search. In this work, we present STANCE --a learned model for computing the similarity of two strings. Our approach encodes the characters of each string, aligns the encodings using Sinkhorn Iteration (alignment is posed as an instance of optimal transport) and scores the alignment with a convolutional neural network. We evaluate STANCE's ability to detect whether two strings can refer to the same entity--a task we term alias detection. We construct five new alias detection datasets (and make them publicly available). We show that STANCE or one of its variants outperforms both state-of-the-art and classic, parameter-free similarity models on four of the five datasets. We also demonstrate STANCE's ability to improve downstream tasks by applying it to an instance of cross-document coreference and show that it leads to a 2.8 point improvement in B^3 F1 over the previous state-of-the-art approach.
Supervised Hierarchical Clustering with Exponential Linkage
Jun 19, 2019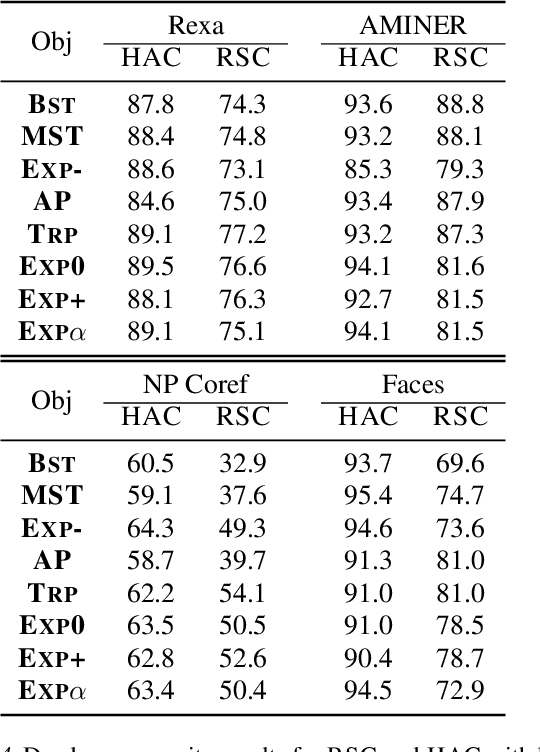
In supervised clustering, standard techniques for learning a pairwise dissimilarity function often suffer from a discrepancy between the training and clustering objectives, leading to poor cluster quality. Rectifying this discrepancy necessitates matching the procedure for training the dissimilarity function to the clustering algorithm. In this paper, we introduce a method for training the dissimilarity function in a way that is tightly coupled with hierarchical clustering, in particular single linkage. However, the appropriate clustering algorithm for a given dataset is often unknown. Thus we introduce an approach to supervised hierarchical clustering that smoothly interpolates between single, average, and complete linkage, and we give a training procedure that simultaneously learns a linkage function and a dissimilarity function. We accomplish this with a novel Exponential Linkage function that has a learnable parameter that controls the interpolation. In experiments on four datasets, our joint training procedure consistently matches or outperforms the next best training procedure/linkage function pair and gives up to 8 points improvement in dendrogram purity over discrepant pairs.
Constructing High Precision Knowledge Bases with Subjective and Factual Attributes
Jun 13, 2019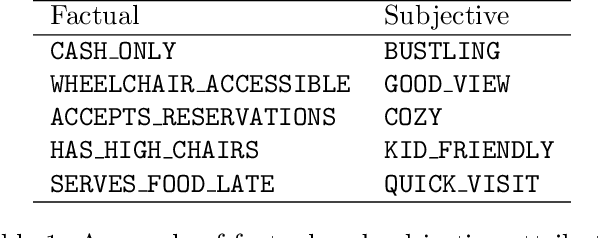
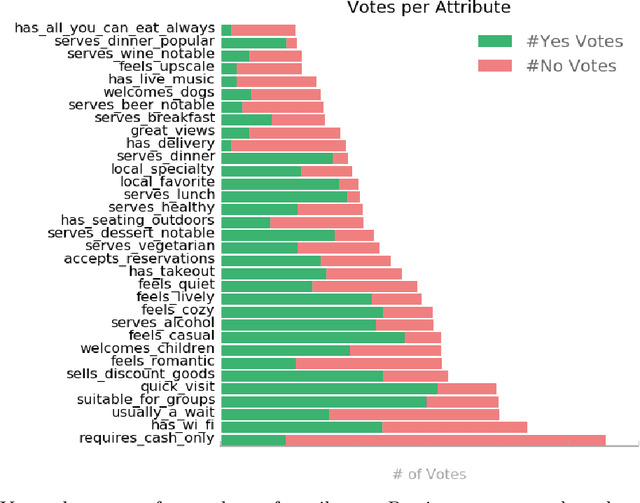
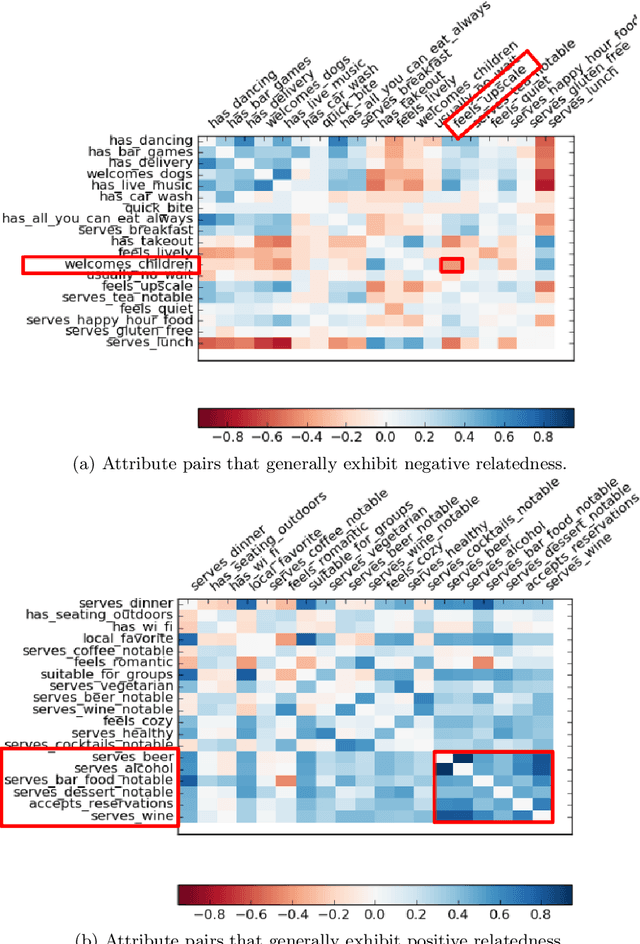
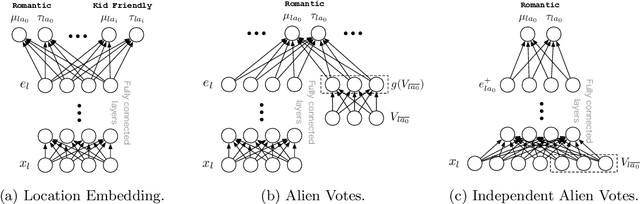
Knowledge bases (KBs) are the backbone of many ubiquitous applications and are thus required to exhibit high precision. However, for KBs that store subjective attributes of entities, e.g., whether a movie is "kid friendly", simply estimating precision is complicated by the inherent ambiguity in measuring subjective phenomena. In this work, we develop a method for constructing KBs with tunable precision--i.e., KBs that can be made to operate at a specific false positive rate, despite storing both difficult-to-evaluate subjective attributes and more traditional factual attributes. The key to our approach is probabilistically modeling user consensus with respect to each entity-attribute pair, rather than modeling each pair as either True or False. Uncertainty in the model is explicitly represented and used to control the KB's precision. We propose three neural networks for fitting the consensus model and evaluate each one on data from Google Maps--a large KB of locations and their subjective and factual attributes. The results demonstrate that our learned models are well-calibrated and thus can successfully be used to control the KB's precision. Moreover, when constrained to maintain 95% precision, the best consensus model matches the F-score of a baseline that models each entity-attribute pair as a binary variable and does not support tunable precision. When unconstrained, our model dominates the same baseline by 12% F-score. Finally, we perform an empirical analysis of attribute-attribute correlations and show that leveraging them effectively contributes to reduced uncertainty and better performance in attribute prediction.
An Online Hierarchical Algorithm for Extreme Clustering
Apr 06, 2017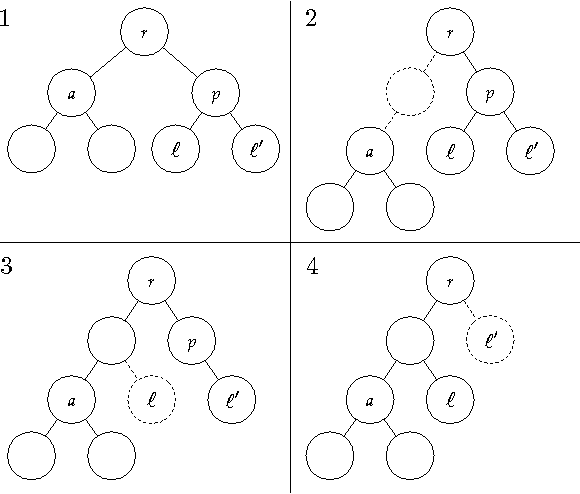
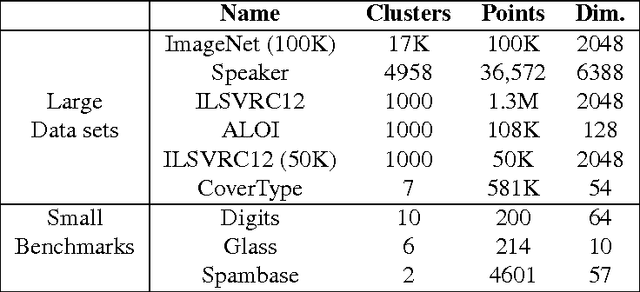
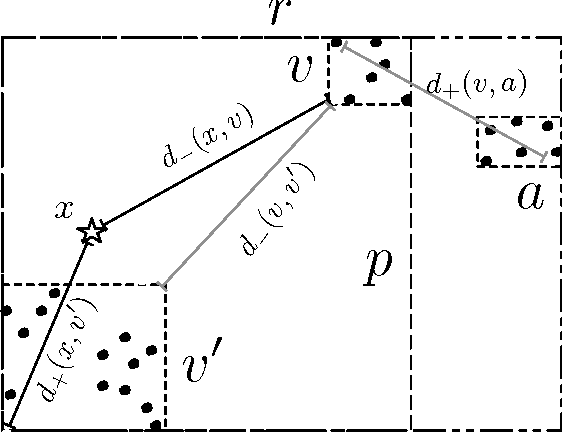

Many modern clustering methods scale well to a large number of data items, N, but not to a large number of clusters, K. This paper introduces PERCH, a new non-greedy algorithm for online hierarchical clustering that scales to both massive N and K--a problem setting we term extreme clustering. Our algorithm efficiently routes new data points to the leaves of an incrementally-built tree. Motivated by the desire for both accuracy and speed, our approach performs tree rotations for the sake of enhancing subtree purity and encouraging balancedness. We prove that, under a natural separability assumption, our non-greedy algorithm will produce trees with perfect dendrogram purity regardless of online data arrival order. Our experiments demonstrate that PERCH constructs more accurate trees than other tree-building clustering algorithms and scales well with both N and K, achieving a higher quality clustering than the strongest flat clustering competitor in nearly half the time.