 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeclimt-paraformer: Stable Emulation of Convective Parameterization using a Temporal Memory-aware Transformer
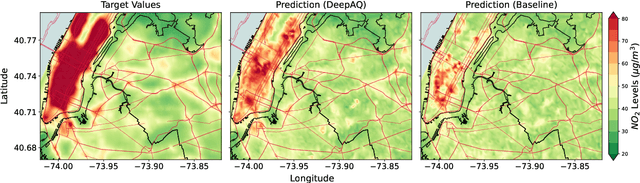
Apr 22, 2026Accurate representation of moist convective sub-grid-scale processes remains a major challenge in global climate models, as traditional parameterization schemes are both computationally expensive and difficult to scale. Neural network (NN) emulators offer a promising alternative by learning efficient mappings between atmospheric states and convective tendencies while retaining fidelity to the underlying physics. However, most existing NN-based parameterizations are memory-less and rely only on instantaneous inputs, even though convection evolves over time and depends on prior atmospheric states. Recent studies have begun to incorporate convective memory, but they often treat past states as independent features rather than modeling temporal dependencies explicitly. In this work, we develop a temporal memory-aware Transformer emulator for the Emanuel convective parameterization and evaluate it in a single-column climate model (SCM) under both offline and online configurations. The Transformer captures temporal correlations and nonlinear interactions across consecutive atmospheric states. Compared with baseline emulators, including a memory-less multilayer perceptron and a recurrent long short-term memory model, the Transformer achieves lower offline errors. Sensitivity analysis indicates that a memory length of approximately 100 minutes yields the best performance, whereas longer memory degrades performance. We further test the emulator in long-term coupled simulations and show that it remains stable over 10 years. Overall, this study demonstrates the importance of explicit temporal modeling for NN-based parameterizations.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Paraformer: Parameterization of Sub-grid Scale Processes Using Transformers
Dec 21, 2024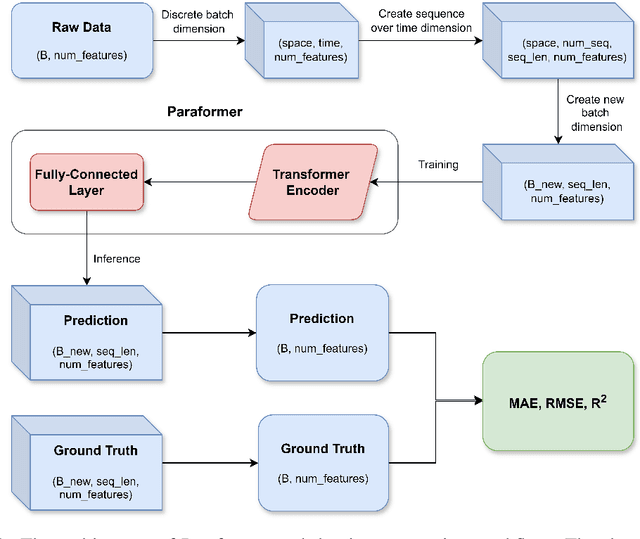



One of the major sources of uncertainty in the current generation of Global Climate Models (GCMs) is the representation of sub-grid scale physical processes. Over the years, a series of deep-learning-based parameterization schemes have been developed and tested on both idealized and real-geography GCMs. However, datasets on which previous deep-learning models were trained either contain limited variables or have low spatial-temporal coverage, which can not fully simulate the parameterization process. Additionally, these schemes rely on classical architectures while the latest attention mechanism used in Transformer models remains unexplored in this field. In this paper, we propose Paraformer, a "memory-aware" Transformer-based model on ClimSim, the largest dataset ever created for climate parameterization. Our results demonstrate that the proposed model successfully captures the complex non-linear dependencies in the sub-grid scale variables and outperforms classical deep-learning architectures. This work highlights the applicability of the attenuation mechanism in this field and provides valuable insights for developing future deep-learning-based climate parameterization schemes.
Adaptive Retrieval and Scalable Indexing for k-NN Search with Cross-Encoders
May 06, 2024Cross-encoder (CE) models which compute similarity by jointly encoding a query-item pair perform better than embedding-based models (dual-encoders) at estimating query-item relevance. Existing approaches perform k-NN search with CE by approximating the CE similarity with a vector embedding space fit either with dual-encoders (DE) or CUR matrix factorization. DE-based retrieve-and-rerank approaches suffer from poor recall on new domains and the retrieval with DE is decoupled from the CE. While CUR-based approaches can be more accurate than the DE-based approach, they require a prohibitively large number of CE calls to compute item embeddings, thus making it impractical for deployment at scale. In this paper, we address these shortcomings with our proposed sparse-matrix factorization based method that efficiently computes latent query and item embeddings to approximate CE scores and performs k-NN search with the approximate CE similarity. We compute item embeddings offline by factorizing a sparse matrix containing query-item CE scores for a set of train queries. Our method produces a high-quality approximation while requiring only a fraction of CE calls as compared to CUR-based methods, and allows for leveraging DE to initialize the embedding space while avoiding compute- and resource-intensive finetuning of DE via distillation. At test time, the item embeddings remain fixed and retrieval occurs over rounds, alternating between a) estimating the test query embedding by minimizing error in approximating CE scores of items retrieved thus far, and b) using the updated test query embedding for retrieving more items. Our k-NN search method improves recall by up to 5% (k=1) and 54% (k=100) over DE-based approaches. Additionally, our indexing approach achieves a speedup of up to 100x over CUR-based and 5x over DE distillation methods, while matching or improving k-NN search recall over baselines.
Adaptive Selection of Anchor Items for CUR-based k-NN search with Cross-Encoders
May 04, 2023



Cross-encoder models, which jointly encode and score a query-item pair, are typically prohibitively expensive for k-nearest neighbor search. Consequently, k-NN search is performed not with a cross-encoder, but with a heuristic retrieve (e.g., using BM25 or dual-encoder) and re-rank approach. Recent work proposes ANNCUR (Yadav et al., 2022) which uses CUR matrix factorization to produce an embedding space for efficient vector-based search that directly approximates the cross-encoder without the need for dual-encoders. ANNCUR defines this shared query-item embedding space by scoring the test query against anchor items which are sampled uniformly at random. While this minimizes average approximation error over all items, unsuitably high approximation error on top-k items remains and leads to poor recall of top-k (and especially top-1) items. Increasing the number of anchor items is a straightforward way of improving the approximation error and hence k-NN recall of ANNCUR but at the cost of increased inference latency. In this paper, we propose a new method for adaptively choosing anchor items that minimizes the approximation error for the practically important top-k neighbors for a query with minimal computational overhead. Our proposed method incrementally selects a suitable set of anchor items for a given test query over several rounds, using anchors chosen in previous rounds to inform selection of more anchor items. Empirically, our method consistently improves k-NN recall as compared to both ANNCUR and the widely-used dual-encoder-based retrieve-and-rerank approach.
CDA: Contrastive-adversarial Domain Adaptation
Jan 10, 2023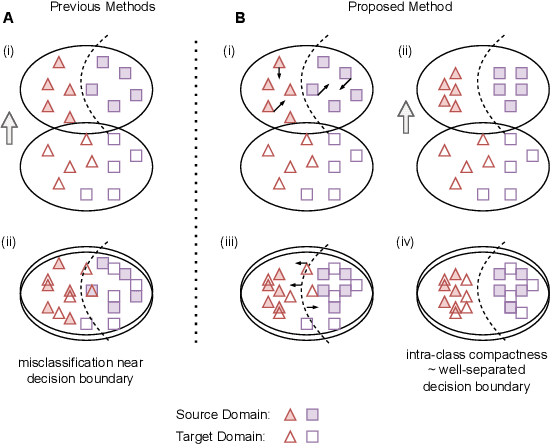
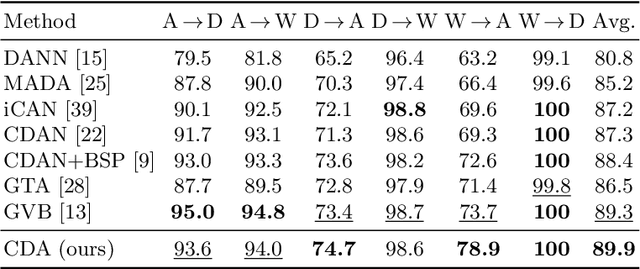
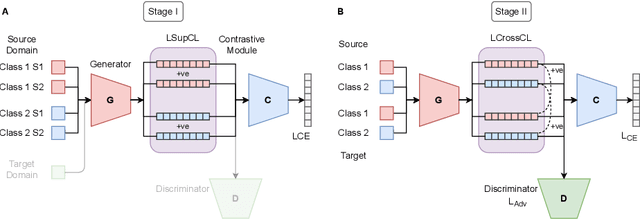
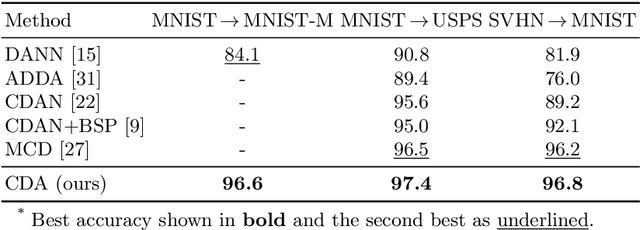
Recent advances in domain adaptation reveal that adversarial learning on deep neural networks can learn domain invariant features to reduce the shift between source and target domains. While such adversarial approaches achieve domain-level alignment, they ignore the class (label) shift. When class-conditional data distributions are significantly different between the source and target domain, it can generate ambiguous features near class boundaries that are more likely to be misclassified. In this work, we propose a two-stage model for domain adaptation called \textbf{C}ontrastive-adversarial \textbf{D}omain \textbf{A}daptation \textbf{(CDA)}. While the adversarial component facilitates domain-level alignment, two-stage contrastive learning exploits class information to achieve higher intra-class compactness across domains resulting in well-separated decision boundaries. Furthermore, the proposed contrastive framework is designed as a plug-and-play module that can be easily embedded with existing adversarial methods for domain adaptation. We conduct experiments on two widely used benchmark datasets for domain adaptation, namely, \textit{Office-31} and \textit{Digits-5}, and demonstrate that CDA achieves state-of-the-art results on both datasets.
Efficient Nearest Neighbor Search for Cross-Encoder Models using Matrix Factorization
Oct 23, 2022


Efficient k-nearest neighbor search is a fundamental task, foundational for many problems in NLP. When the similarity is measured by dot-product between dual-encoder vectors or $\ell_2$-distance, there already exist many scalable and efficient search methods. But not so when similarity is measured by more accurate and expensive black-box neural similarity models, such as cross-encoders, which jointly encode the query and candidate neighbor. The cross-encoders' high computational cost typically limits their use to reranking candidates retrieved by a cheaper model, such as dual encoder or TF-IDF. However, the accuracy of such a two-stage approach is upper-bounded by the recall of the initial candidate set, and potentially requires additional training to align the auxiliary retrieval model with the cross-encoder model. In this paper, we present an approach that avoids the use of a dual-encoder for retrieval, relying solely on the cross-encoder. Retrieval is made efficient with CUR decomposition, a matrix decomposition approach that approximates all pairwise cross-encoder distances from a small subset of rows and columns of the distance matrix. Indexing items using our approach is computationally cheaper than training an auxiliary dual-encoder model through distillation. Empirically, for k > 10, our approach provides test-time recall-vs-computational cost trade-offs superior to the current widely-used methods that re-rank items retrieved using a dual-encoder or TF-IDF.
Robustness of Explanation Methods for NLP Models
Jun 24, 2022



Explanation methods have emerged as an important tool to highlight the features responsible for the predictions of neural networks. There is mounting evidence that many explanation methods are rather unreliable and susceptible to malicious manipulations. In this paper, we particularly aim to understand the robustness of explanation methods in the context of text modality. We provide initial insights and results towards devising a successful adversarial attack against text explanations. To our knowledge, this is the first attempt to evaluate the adversarial robustness of an explanation method. Our experiments show the explanation method can be largely disturbed for up to 86% of the tested samples with small changes in the input sentence and its semantics.
Deep Transfer Learning on Satellite Imagery Improves Air Quality Estimates in Developing Nations
Feb 17, 2022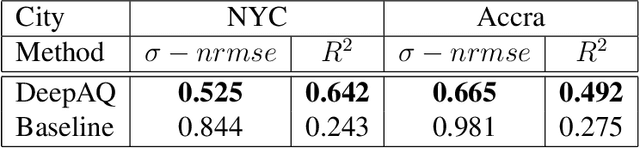
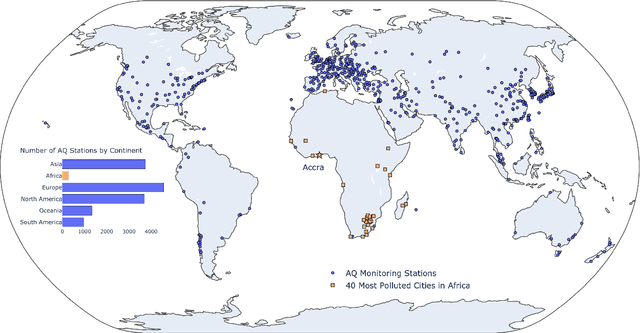
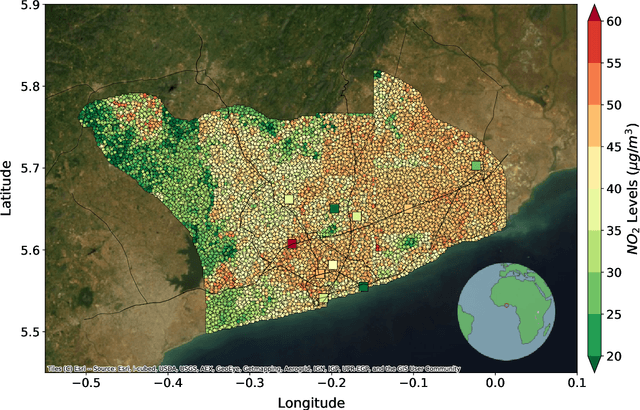
Urban air pollution is a public health challenge in low- and middle-income countries (LMICs). However, LMICs lack adequate air quality (AQ) monitoring infrastructure. A persistent challenge has been our inability to estimate AQ accurately in LMIC cities, which hinders emergency preparedness and risk mitigation. Deep learning-based models that map satellite imagery to AQ can be built for high-income countries (HICs) with adequate ground data. Here we demonstrate that a scalable approach that adapts deep transfer learning on satellite imagery for AQ can extract meaningful estimates and insights in LMIC cities based on spatiotemporal patterns learned in HIC cities. The approach is demonstrated for Accra in Ghana, Africa, with AQ patterns learned from two US cities, specifically Los Angeles and New York.
Session-Aware Query Auto-completion using Extreme Multi-label Ranking
Dec 09, 2020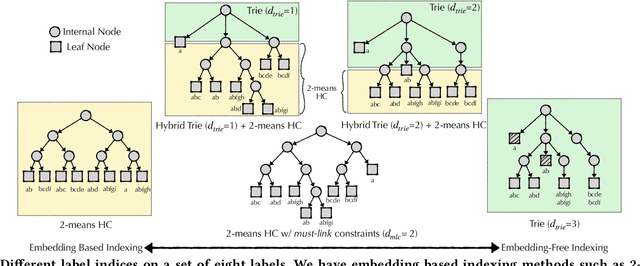
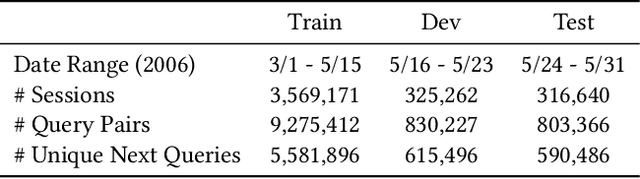
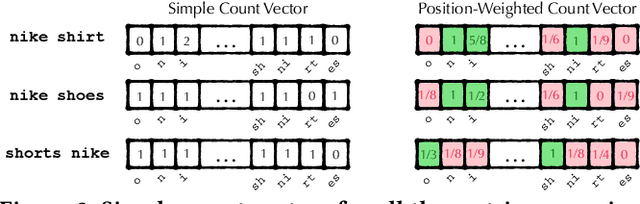
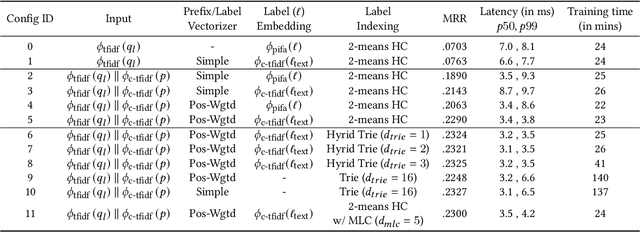
Query auto-completion is a fundamental feature in search engines where the task is to suggest plausible completions of a prefix typed in the search bar. Previous queries in the user session can provide useful context for the user's intent and can be leveraged to suggest auto-completions that are more relevant while adhering to the user's prefix. Such session-aware query auto-completions can be generated by sequence-to-sequence models; however, these generative approaches often do not meet the stringent latency requirements of responding to each user keystroke. Moreover, there is a danger of showing non-sensical queries in a generative approach. Another solution is to pre-compute a relatively small subset of relevant queries for common prefixes and rank them based on the context. However, such an approach would fail if no relevant queries for the current context are present in the pre-computed set. In this paper, we provide a solution to this problem: we take the novel approach of modeling session-aware query auto-completion as an eXtreme Multi-Label Ranking (XMR) problem where the input is the previous query in the session and the user's current prefix, while the output space is the set of millions of queries entered by users in the recent past. We adapt a popular XMR algorithm for this purpose by proposing several modifications to the key steps in the algorithm. The proposed modifications yield a 230% improvement in terms of Mean Reciprocal Rank over the baseline XMR approach on a public search logs dataset. Our approach meets the stringent latency requirements for auto-complete systems while leveraging session information in making suggestions. We show that session context leads to significant improvements in the quality of query auto-completions; in particular, for short prefixes with up to 3 characters, we see a 32% improvement over baselines that meet latency requirements.