 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDA: Contrastive-adversarial Domain Adaptation
Jan 10, 2023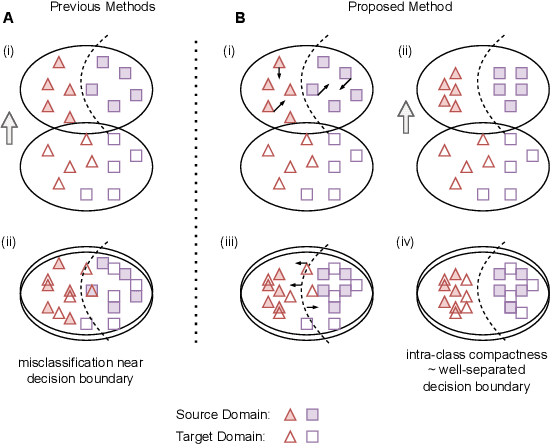
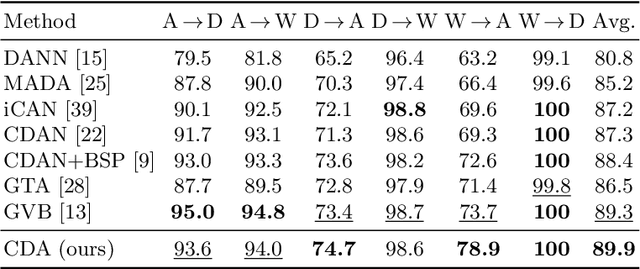
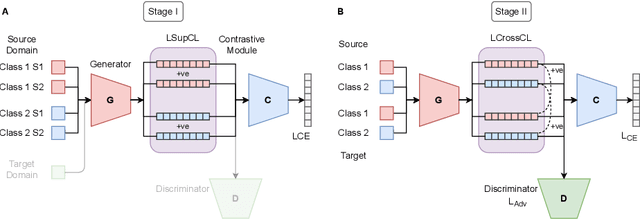
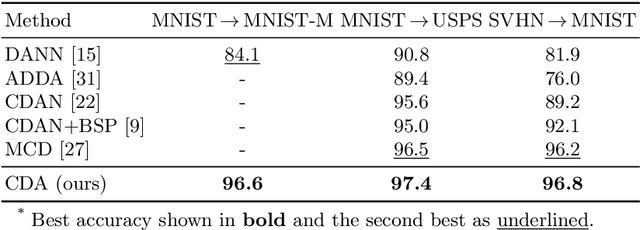
Recent advances in domain adaptation reveal that adversarial learning on deep neural networks can learn domain invariant features to reduce the shift between source and target domains. While such adversarial approaches achieve domain-level alignment, they ignore the class (label) shift. When class-conditional data distributions are significantly different between the source and target domain, it can generate ambiguous features near class boundaries that are more likely to be misclassified. In this work, we propose a two-stage model for domain adaptation called \textbf{C}ontrastive-adversarial \textbf{D}omain \textbf{A}daptation \textbf{(CDA)}. While the adversarial component facilitates domain-level alignment, two-stage contrastive learning exploits class information to achieve higher intra-class compactness across domains resulting in well-separated decision boundaries. Furthermore, the proposed contrastive framework is designed as a plug-and-play module that can be easily embedded with existing adversarial methods for domain adaptation. We conduct experiments on two widely used benchmark datasets for domain adaptation, namely, \textit{Office-31} and \textit{Digits-5}, and demonstrate that CDA achieves state-of-the-art results on both datasets.
Wisdom of the Ensemble: Improving Consistency of Deep Learning Models
Nov 13, 2020

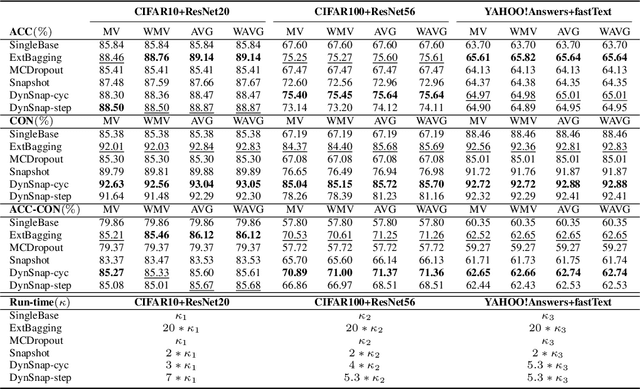
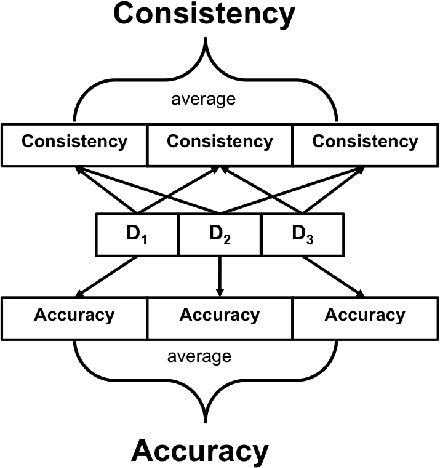
Deep learning classifiers are assisting humans in making decisions and hence the user's trust in these models is of paramount importance. Trust is often a function of constant behavior. From an AI model perspective it means given the same input the user would expect the same output, especially for correct outputs, or in other words consistently correct outputs. This paper studies a model behavior in the context of periodic retraining of deployed models where the outputs from successive generations of the models might not agree on the correct labels assigned to the same input. We formally define consistency and correct-consistency of a learning model. We prove that consistency and correct-consistency of an ensemble learner is not less than the average consistency and correct-consistency of individual learners and correct-consistency can be improved with a probability by combining learners with accuracy not less than the average accuracy of ensemble component learners. To validate the theory using three datasets and two state-of-the-art deep learning classifiers we also propose an efficient dynamic snapshot ensemble method and demonstrate its value.