 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Decision Transformers for Dynamic Dispatching in Material Handling Systems Leveraging Enterprise Big Data
Nov 04, 2024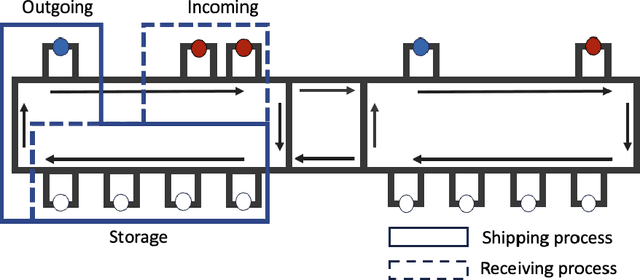

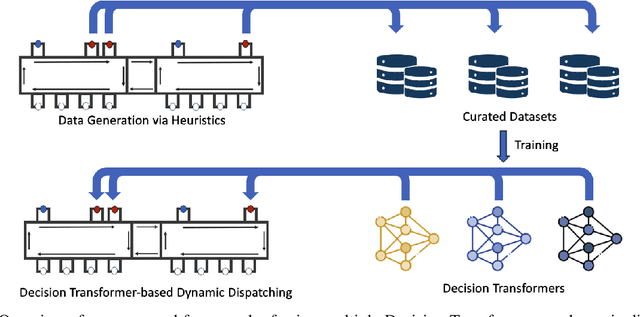
Dynamic dispatching rules that allocate resources to tasks in real-time play a critical role in ensuring efficient operations of many automated material handling systems across industries. Traditionally, the dispatching rules deployed are typically the result of manually crafted heuristics based on domain experts' knowledge. Generating these rules is time-consuming and often sub-optimal. As enterprises increasingly accumulate vast amounts of operational data, there is significant potential to leverage this big data to enhance the performance of automated systems. One promising approach is to use Decision Transformers, which can be trained on existing enterprise data to learn better dynamic dispatching rules for improving system throughput. In this work, we study the application of Decision Transformers as dynamic dispatching policies within an actual multi-agent material handling system and identify scenarios where enterprises can effectively leverage Decision Transformers on existing big data to gain business value. Our empirical results demonstrate that Decision Transformers can improve the material handling system's throughput by a considerable amount when the heuristic originally used in the enterprise data exhibits moderate performance and involves no randomness. When the original heuristic has strong performance, Decision Transformers can still improve the throughput but with a smaller improvement margin. However, when the original heuristics contain an element of randomness or when the performance of the dataset is below a certain threshold, Decision Transformers fail to outperform the original heuristic. These results highlight both the potential and limitations of Decision Transformers as dispatching policies for automated industrial material handling systems.
Equipment Health Assessment: Time Series Analysis for Wind Turbine Performance
Mar 01, 2024



In this study, we leverage SCADA data from diverse wind turbines to predict power output, employing advanced time series methods, specifically Functional Neural Networks (FNN) and Long Short-Term Memory (LSTM) networks. A key innovation lies in the ensemble of FNN and LSTM models, capitalizing on their collective learning. This ensemble approach outperforms individual models, ensuring stable and accurate power output predictions. Additionally, machine learning techniques are applied to detect wind turbine performance deterioration, enabling proactive maintenance strategies and health assessment. Crucially, our analysis reveals the uniqueness of each wind turbine, necessitating tailored models for optimal predictions. These insight underscores the importance of providing automatized customization for different turbines to keep human modeling effort low. Importantly, the methodologies developed in this analysis are not limited to wind turbines; they can be extended to predict and optimize performance in various machinery, highlighting the versatility and applicability of our research across diverse industrial contexts.
Predictive Analysis for Optimizing Port Operations
Jan 25, 2024Maritime transport is a pivotal logistics mode for the long-distance and bulk transportation of goods. However, the intricate planning involved in this mode is often hindered by uncertainties, including weather conditions, cargo diversity, and port dynamics, leading to increased costs. Consequently, accurately estimating vessel total (stay) time at port and potential delays becomes imperative for effective planning and scheduling in port operations. This study aims to develop a port operation solution with competitive prediction and classification capabilities for estimating vessel Total and Delay times. This research addresses a significant gap in port analysis models for vessel Stay and Delay times, offering a valuable contribution to the field of maritime logistics. The proposed solution is designed to assist decision-making in port environments and predict service delays. This is demonstrated through a case study on Brazil ports. Additionally, feature analysis is used to understand the key factors impacting maritime logistics, enhancing the overall understanding of the complexities involved in port operations.
An ensemble of convolution-based methods for fault detection using vibration signals
May 05, 2023
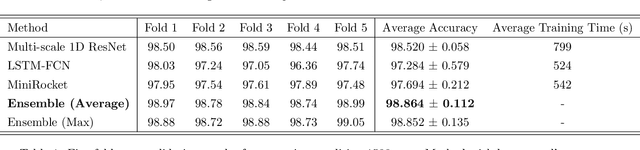
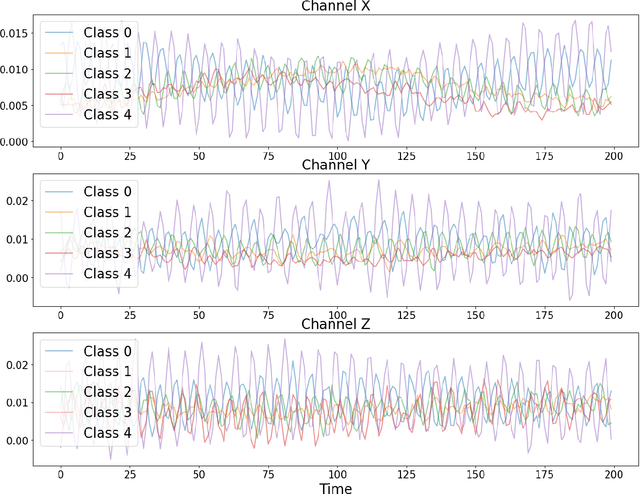
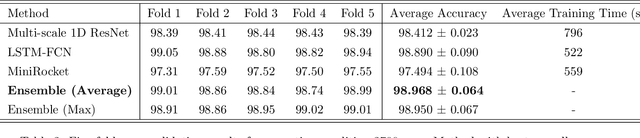
This paper focuses on solving a fault detection problem using multivariate time series of vibration signals collected from planetary gearboxes in a test rig. Various traditional machine learning and deep learning methods have been proposed for multivariate time-series classification, including distance-based, functional data-oriented, feature-driven, and convolution kernel-based methods. Recent studies have shown using convolution kernel-based methods like ROCKET, and 1D convolutional neural networks with ResNet and FCN, have robust performance for multivariate time-series data classification. We propose an ensemble of three convolution kernel-based methods and show its efficacy on this fault detection problem by outperforming other approaches and achieving an accuracy of more than 98.8\%.
Latent-Conditioned Policy Gradient for Multi-Objective Deep Reinforcement Learning
Mar 15, 2023Sequential decision making in the real world often requires finding a good balance of conflicting objectives. In general, there exist a plethora of Pareto-optimal policies that embody different patterns of compromises between objectives, and it is technically challenging to obtain them exhaustively using deep neural networks. In this work, we propose a novel multi-objective reinforcement learning (MORL) algorithm that trains a single neural network via policy gradient to approximately obtain the entire Pareto set in a single run of training, without relying on linear scalarization of objectives. The proposed method works in both continuous and discrete action spaces with no design change of the policy network. Numerical experiments in benchmark environments demonstrate the practicality and efficacy of our approach in comparison to standard MORL baselines.
CDA: Contrastive-adversarial Domain Adaptation
Jan 10, 2023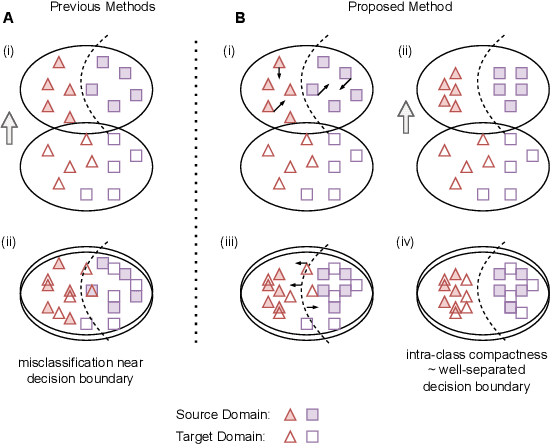
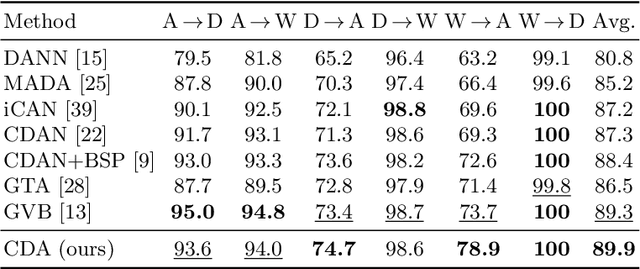
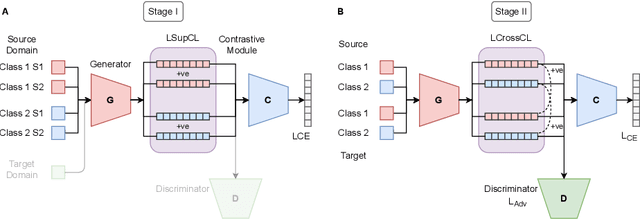
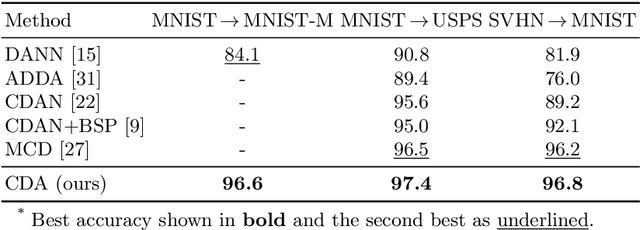
Recent advances in domain adaptation reveal that adversarial learning on deep neural networks can learn domain invariant features to reduce the shift between source and target domains. While such adversarial approaches achieve domain-level alignment, they ignore the class (label) shift. When class-conditional data distributions are significantly different between the source and target domain, it can generate ambiguous features near class boundaries that are more likely to be misclassified. In this work, we propose a two-stage model for domain adaptation called \textbf{C}ontrastive-adversarial \textbf{D}omain \textbf{A}daptation \textbf{(CDA)}. While the adversarial component facilitates domain-level alignment, two-stage contrastive learning exploits class information to achieve higher intra-class compactness across domains resulting in well-separated decision boundaries. Furthermore, the proposed contrastive framework is designed as a plug-and-play module that can be easily embedded with existing adversarial methods for domain adaptation. We conduct experiments on two widely used benchmark datasets for domain adaptation, namely, \textit{Office-31} and \textit{Digits-5}, and demonstrate that CDA achieves state-of-the-art results on both datasets.
A Functional approach for Two Way Dimension Reduction in Time Series
Jan 01, 2023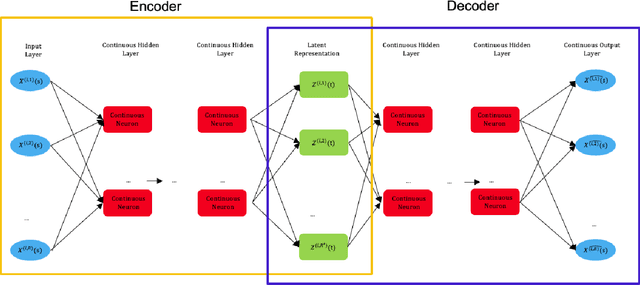
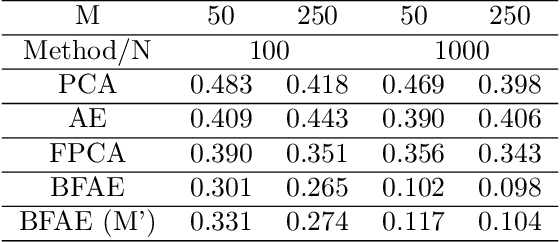
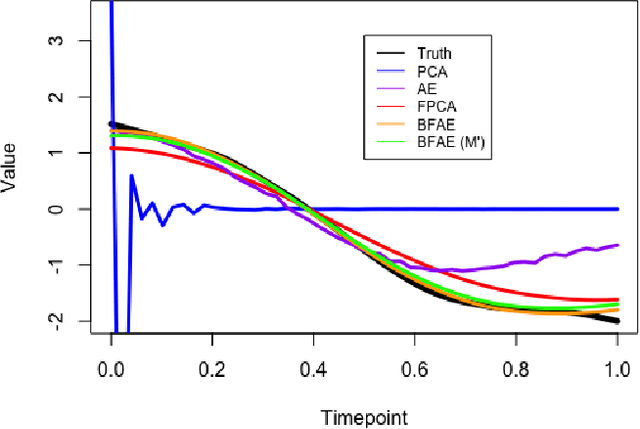
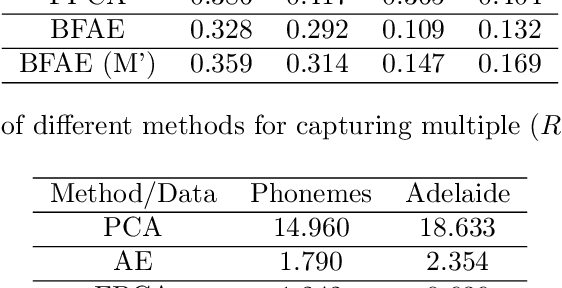
The rise in data has led to the need for dimension reduction techniques, especially in the area of non-scalar variables, including time series, natural language processing, and computer vision. In this paper, we specifically investigate dimension reduction for time series through functional data analysis. Current methods for dimension reduction in functional data are functional principal component analysis and functional autoencoders, which are limited to linear mappings or scalar representations for the time series, which is inefficient. In real data applications, the nature of the data is much more complex. We propose a non-linear function-on-function approach, which consists of a functional encoder and a functional decoder, that uses continuous hidden layers consisting of continuous neurons to learn the structure inherent in functional data, which addresses the aforementioned concerns in the existing approaches. Our approach gives a low dimension latent representation by reducing the number of functional features as well as the timepoints at which the functions are observed. The effectiveness of the proposed model is demonstrated through multiple simulations and real data examples.
* 10 pages, 4 figures, 4 tables
Sample-based Uncertainty Quantification with a Single Deterministic Neural Network
Sep 17, 2022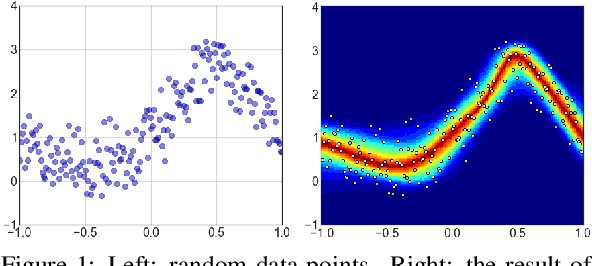
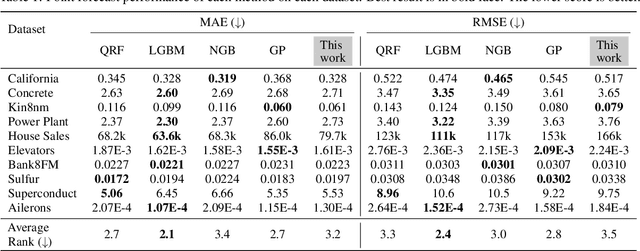
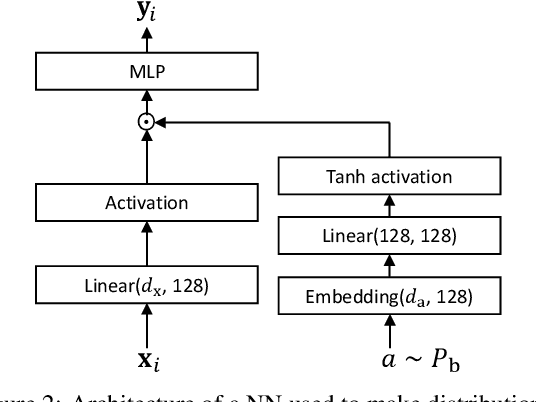
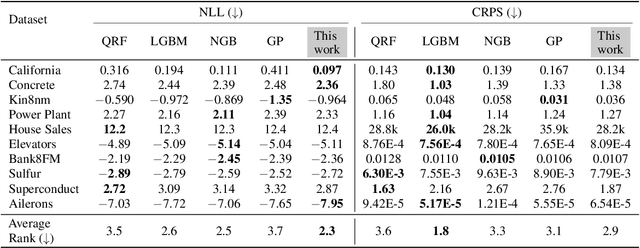
Development of an accurate, flexible, and numerically efficient uncertainty quantification (UQ) method is one of fundamental challenges in machine learning. Previously, a UQ method called DISCO Nets has been proposed (Bouchacourt et al., 2016) that trains a neural network by minimizing the so-called energy score on training data. This method has shown superior performance on a hand pose estimation task in computer vision, but it remained unclear whether this method works as nicely for regression on tabular data, and how it competes with more recent advanced UQ methods such as NGBoost. In this paper, we propose an improved neural architecture of DISCO Nets that admits a more stable and smooth training. We benchmark this approach on miscellaneous real-world tabular datasets and confirm that it is competitive with or even superior to standard UQ baselines. We also provide a new elementary proof for the validity of using the energy score to learn predictive distributions. Further, we point out that DISCO Nets in its original form ignore epistemic uncertainty and only capture aleatoric uncertainty. We propose a simple fix to this problem.
Distributional Actor-Critic Ensemble for Uncertainty-Aware Continuous Control
Jul 27, 2022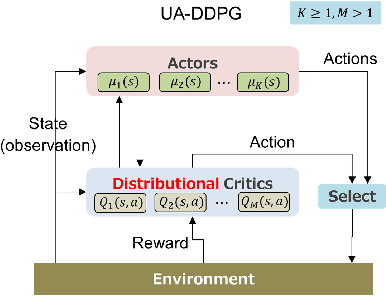
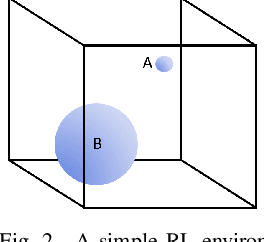
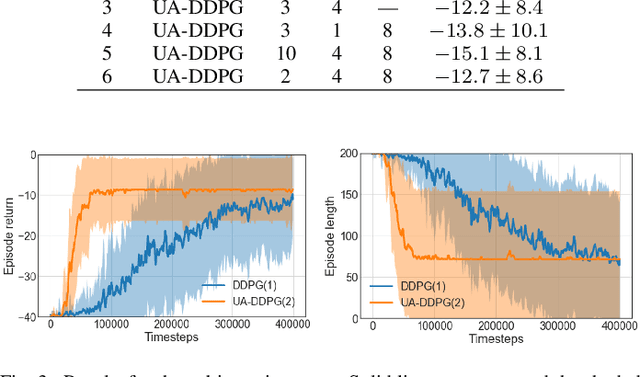
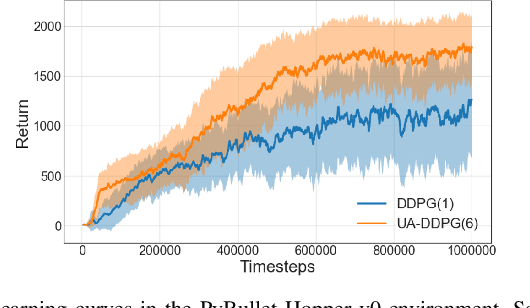
Uncertainty quantification is one of the central challenges for machine learning in real-world applications. In reinforcement learning, an agent confronts two kinds of uncertainty, called epistemic uncertainty and aleatoric uncertainty. Disentangling and evaluating these uncertainties simultaneously stands a chance of improving the agent's final performance, accelerating training, and facilitating quality assurance after deployment. In this work, we propose an uncertainty-aware reinforcement learning algorithm for continuous control tasks that extends the Deep Deterministic Policy Gradient algorithm (DDPG). It exploits epistemic uncertainty to accelerate exploration and aleatoric uncertainty to learn a risk-sensitive policy. We conduct numerical experiments showing that our variant of DDPG outperforms vanilla DDPG without uncertainty estimation in benchmark tasks on robotic control and power-grid optimization.
K-nearest Multi-agent Deep Reinforcement Learning for Collaborative Tasks with a Variable Number of Agents
Jan 18, 2022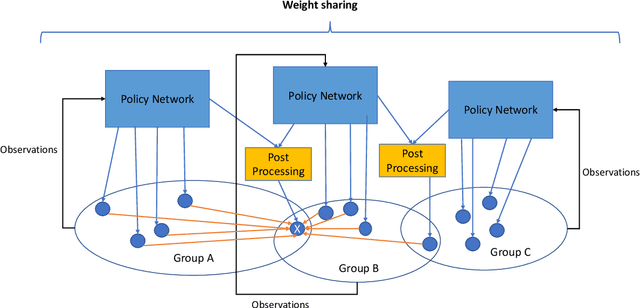
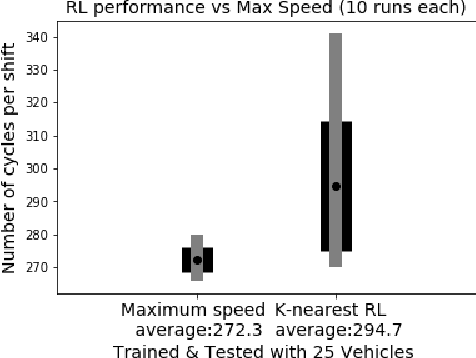
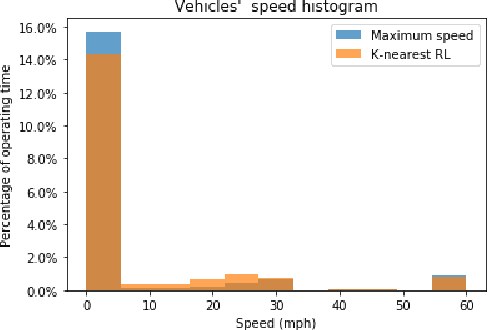
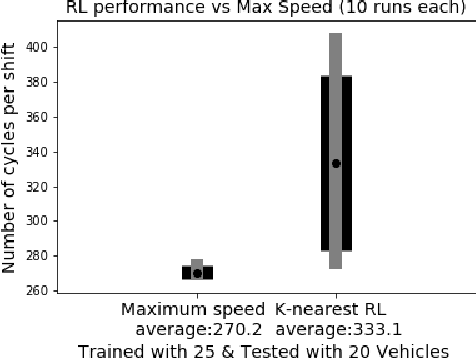
Traditionally, the performance of multi-agent deep reinforcement learning algorithms are demonstrated and validated in gaming environments where we often have a fixed number of agents. In many industrial applications, the number of available agents can change at any given day and even when the number of agents is known ahead of time, it is common for an agent to break during the operation and become unavailable for a period of time. In this paper, we propose a new deep reinforcement learning algorithm for multi-agent collaborative tasks with a variable number of agents. We demonstrate the application of our algorithm using a fleet management simulator developed by Hitachi to generate realistic scenarios in a production site.