 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn ensemble of convolution-based methods for fault detection using vibration signals
May 05, 2023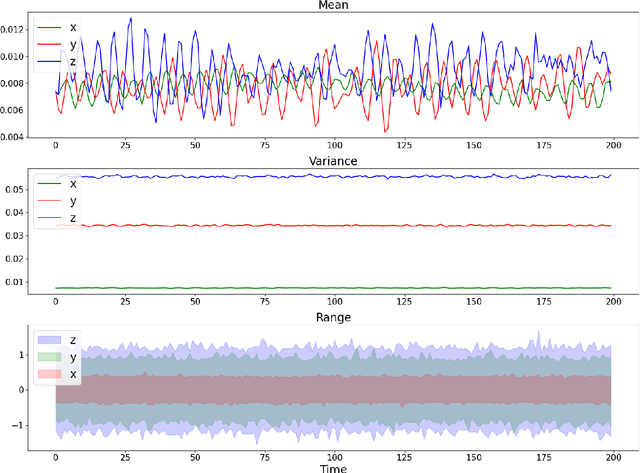
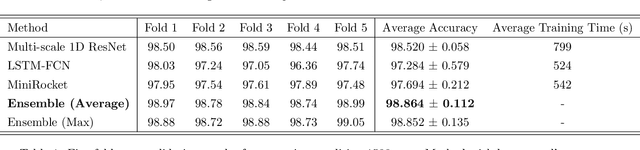
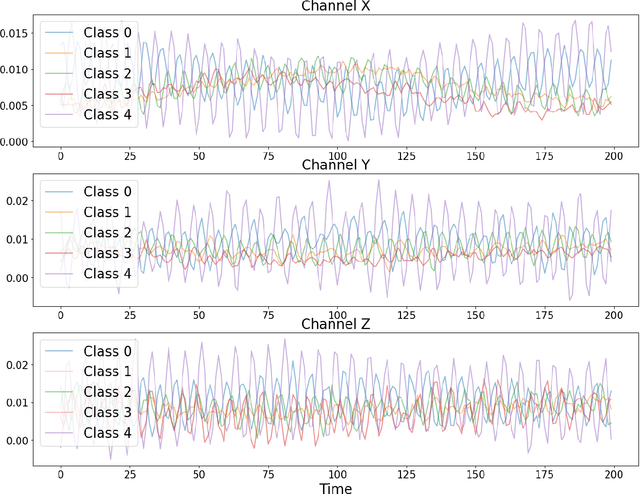
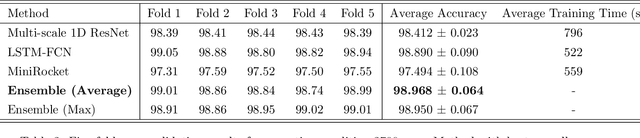
This paper focuses on solving a fault detection problem using multivariate time series of vibration signals collected from planetary gearboxes in a test rig. Various traditional machine learning and deep learning methods have been proposed for multivariate time-series classification, including distance-based, functional data-oriented, feature-driven, and convolution kernel-based methods. Recent studies have shown using convolution kernel-based methods like ROCKET, and 1D convolutional neural networks with ResNet and FCN, have robust performance for multivariate time-series data classification. We propose an ensemble of three convolution kernel-based methods and show its efficacy on this fault detection problem by outperforming other approaches and achieving an accuracy of more than 98.8\%.
Multi-module based CVAE to predict HVCM faults in the SNS accelerator
Apr 20, 2023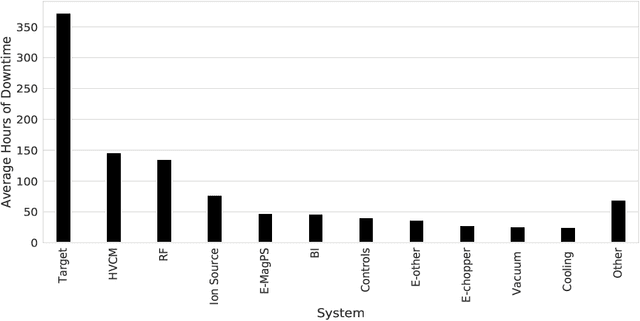



We present a multi-module framework based on Conditional Variational Autoencoder (CVAE) to detect anomalies in the power signals coming from multiple High Voltage Converter Modulators (HVCMs). We condition the model with the specific modulator type to capture different representations of the normal waveforms and to improve the sensitivity of the model to identify a specific type of fault when we have limited samples for a given module type. We studied several neural network (NN) architectures for our CVAE model and evaluated the model performance by looking at their loss landscape for stability and generalization. Our results for the Spallation Neutron Source (SNS) experimental data show that the trained model generalizes well to detecting multiple fault types for several HVCM module types. The results of this study can be used to improve the HVCM reliability and overall SNS uptime
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021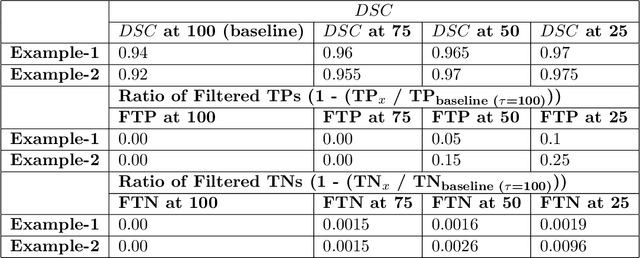
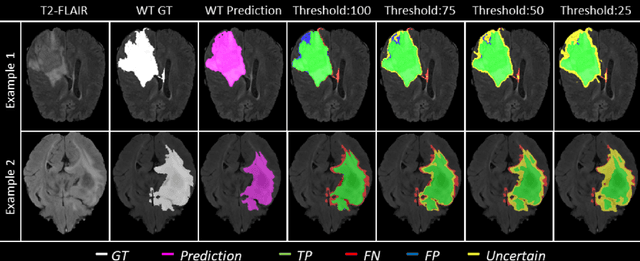
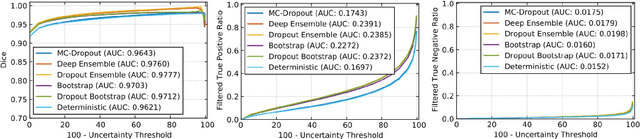
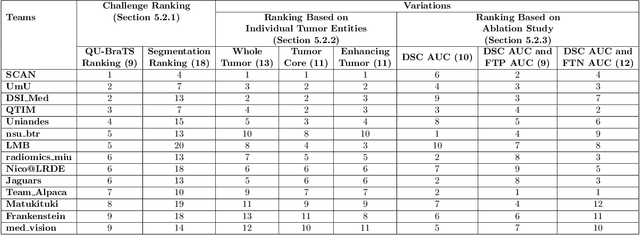
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Deep Cellular Recurrent Network for Efficient Analysis of Time-Series Data with Spatial Information
Jan 12, 2021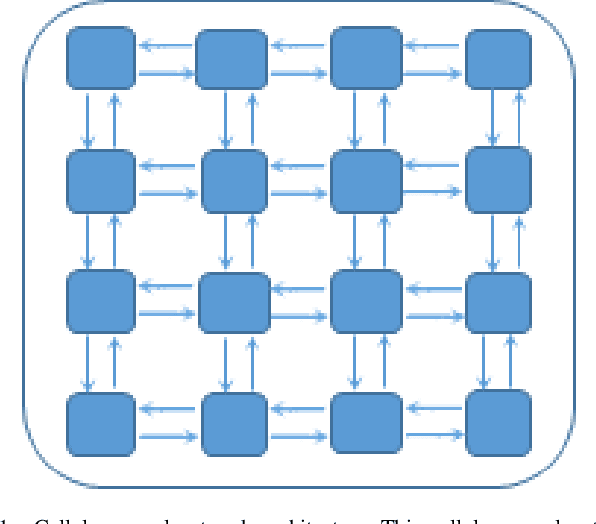
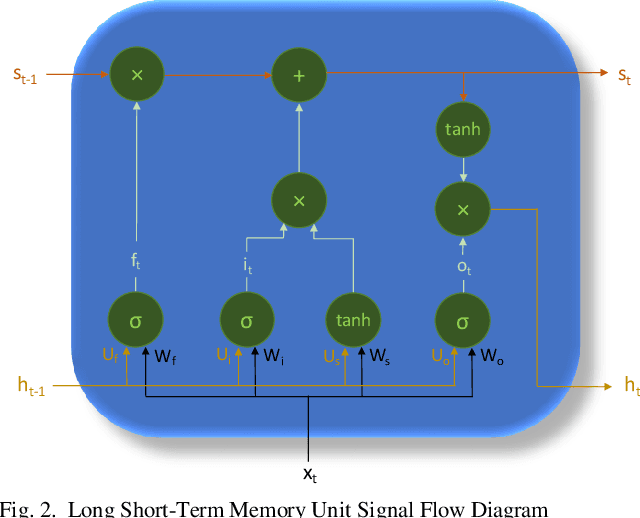
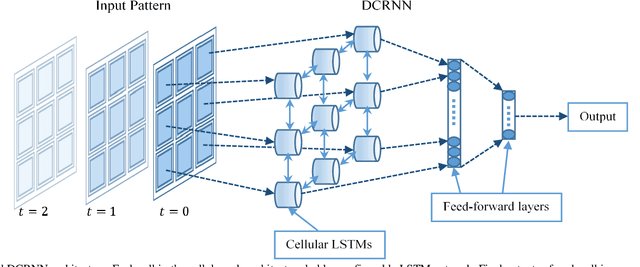
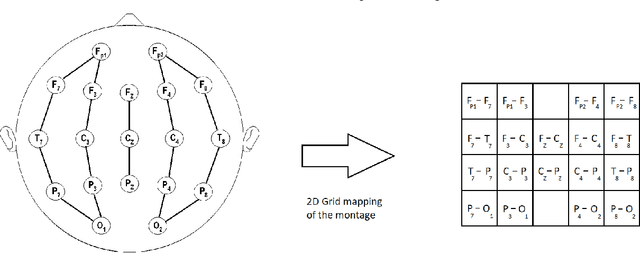
Efficient processing of large-scale time series data is an intricate problem in machine learning. Conventional sensor signal processing pipelines with hand engineered feature extraction often involve huge computational cost with high dimensional data. Deep recurrent neural networks have shown promise in automated feature learning for improved time-series processing. However, generic deep recurrent models grow in scale and depth with increased complexity of the data. This is particularly challenging in presence of high dimensional data with temporal and spatial characteristics. Consequently, this work proposes a novel deep cellular recurrent neural network (DCRNN) architecture to efficiently process complex multi-dimensional time series data with spatial information. The cellular recurrent architecture in the proposed model allows for location-aware synchronous processing of time series data from spatially distributed sensor signal sources. Extensive trainable parameter sharing due to cellularity in the proposed architecture ensures efficiency in the use of recurrent processing units with high-dimensional inputs. This study also investigates the versatility of the proposed DCRNN model for classification of multi-class time series data from different application domains. Consequently, the proposed DCRNN architecture is evaluated using two time-series datasets: a multichannel scalp EEG dataset for seizure detection, and a machine fault detection dataset obtained in-house. The results suggest that the proposed architecture achieves state-of-the-art performance while utilizing substantially less trainable parameters when compared to comparable methods in the literature.
Superconducting radio-frequency cavity fault classification using machine learning at Jefferson Laboratory
Jun 11, 2020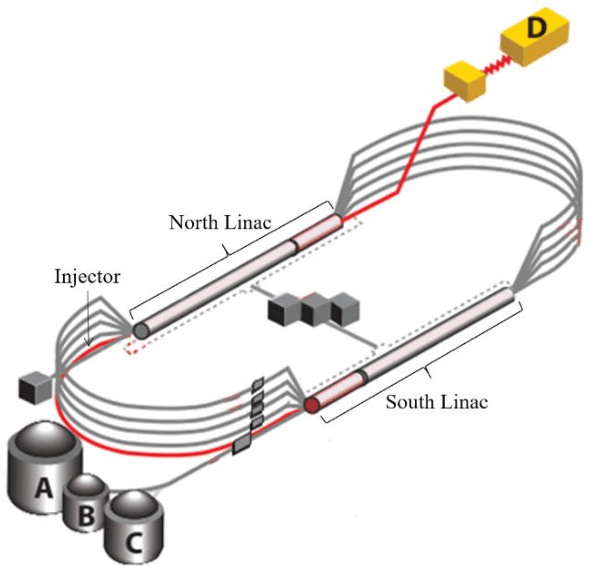


We report on the development of machine learning models for classifying C100 superconducting radio-frequency (SRF) cavity faults in the Continuous Electron Beam Accelerator Facility (CEBAF) at Jefferson Lab. CEBAF is a continuous-wave recirculating linac utilizing 418 SRF cavities to accelerate electrons up to 12 GeV through 5-passes. Of these, 96 cavities (12 cryomodules) are designed with a digital low-level RF system configured such that a cavity fault triggers waveform recordings of 17 RF signals for each of the 8 cavities in the cryomodule. Subject matter experts (SME) are able to analyze the collected time-series data and identify which of the eight cavities faulted first and classify the type of fault. This information is used to find trends and strategically deploy mitigations to problematic cryomodules. However manually labeling the data is laborious and time-consuming. By leveraging machine learning, near real-time (rather than post-mortem) identification of the offending cavity and classification of the fault type has been implemented. We discuss performance of the ML models during a recent physics run. Results show the cavity identification and fault classification models have accuracies of 84.9% and 78.2%, respectively.
Survey on Deep Neural Networks in Speech and Vision Systems
Aug 16, 2019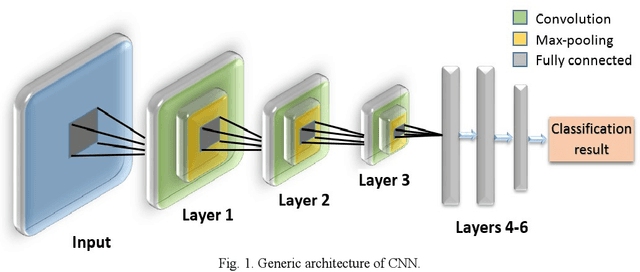
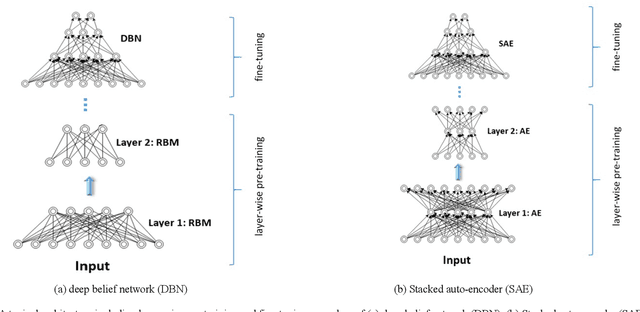
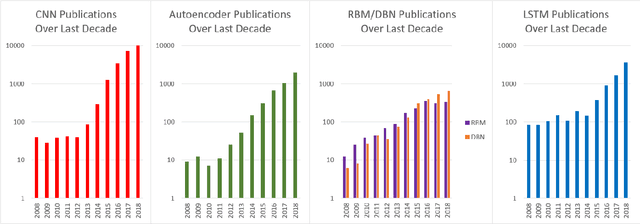
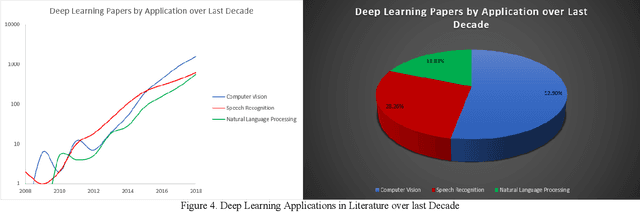
This survey presents a review of state-of-the-art deep neural network architectures, algorithms, and systems in vision and speech applications. Recent advances in deep artificial neural network algorithms and architectures have spurred rapid innovation and development of intelligent vision and speech systems. With availability of vast amounts of sensor data and cloud computing for processing and training of deep neural networks, and with increased sophistication in mobile and embedded technology, the next-generation intelligent systems are poised to revolutionize personal and commercial computing. This survey begins by providing background and evolution of some of the most successful deep learning models for intelligent vision and speech systems to date. An overview of large-scale industrial research and development efforts is provided to emphasize future trends and prospects of intelligent vision and speech systems. Robust and efficient intelligent systems demand low-latency and high fidelity in resource constrained hardware platforms such as mobile devices, robots, and automobiles. Therefore, this survey also provides a summary of key challenges and recent successes in running deep neural networks on hardware-restricted platforms, i.e. within limited memory, battery life, and processing capabilities. Finally, emerging applications of vision and speech across disciplines such as affective computing, intelligent transportation, and precision medicine are discussed. To our knowledge, this paper provides one of the most comprehensive surveys on the latest developments in intelligent vision and speech applications from the perspectives of both software and hardware systems. Many of these emerging technologies using deep neural networks show tremendous promise to revolutionize research and development for future vision and speech systems.