 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttack Assessment and Augmented Identity Recognition for Human Skeleton Data
Mar 25, 2026Machine learning models trained on small data sets for security applications are especially vulnerable to adversarial attacks. Person identification from LiDAR based skeleton data requires time consuming and expensive data acquisition for each subject identity. Recently, Assessment and Augmented Identity Recognition for Skeletons (AAIRS) has been used to train Hierarchical Co-occurrence Networks for Person Identification (HCN-ID) with small LiDAR based skeleton data sets. However, AAIRS does not evaluate robustness of HCN-ID to adversarial attacks or inoculate the model to defend against such attacks. Popular perturbation-based approaches to generating adversarial attacks are constrained to targeted perturbations added to real training samples, which is not ideal for inoculating models with small training sets. Thus, we propose Attack-AAIRS, a novel addition to the AAIRS framework. Attack-AAIRS leverages a small real data set and a GAN generated synthetic data set to assess and improve model robustness against unseen adversarial attacks. Rather than being constrained to perturbations of limited real training samples, the GAN learns the distribution of adversarial attack samples that exploit weaknesses in HCN-ID. Attack samples drawn from this distribution augment training for inoculation of the HCN-ID to improve robustness. Ten-fold cross validation of Attack-AAIRS yields increased robustness to unseen attacks- including FGSM, PGD, Additive Gaussian Noise, MI-FGSM, and BIM. The HCN-ID Synthetic Data Quality Score for Attack-AAIRS indicates that generated attack samples are of similar quality to the original benign synthetic samples generated by AAIRS. Furthermore, inoculated models show consistent final test accuracy with the original model trained on real data, demonstrating that our method improves robustness to adversarial attacks without reducing test performance on real data.
* 8 pages, 9 figures, 3 tables
Machine learning-enhanced non-amnestic Alzheimer's disease diagnosis from MRI and clinical features
Jan 25, 2026Alzheimer's disease (AD), defined as an abnormal buildup of amyloid plaques and tau tangles in the brain can be diagnosed with high accuracy based on protein biomarkers via PET or CSF analysis. However, due to the invasive nature of biomarker collection, most AD diagnoses are made in memory clinics using cognitive tests and evaluation of hippocampal atrophy based on MRI. While clinical assessment and hippocampal volume show high diagnostic accuracy for amnestic or typical AD (tAD), a substantial subgroup of AD patients with atypical presentation (atAD) are routinely misdiagnosed. To improve diagnosis of atAD patients, we propose a machine learning approach to distinguish between atAD and non-AD cognitive impairment using clinical testing battery and MRI data collected as standard-of-care. We develop and evaluate our approach using 1410 subjects across four groups (273 tAD, 184 atAD, 235 non-AD, and 685 cognitively normal) collected from one private data set and two public data sets from the National Alzheimer's Coordinating Center (NACC) and the Alzheimer's Disease Neuroimaging Initiative (ADNI). We perform multiple atAD vs. non-AD classification experiments using clinical features and hippocampal volume as well as a comprehensive set of MRI features from across the brain. The best performance is achieved by incorporating additional important MRI features, which outperforms using hippocampal volume alone. Furthermore, we use the Boruta statistical approach to identify and visualize significant brain regions distinguishing between diagnostic groups. Our ML approach improves the percentage of correctly diagnosed atAD cases (the recall) from 52% to 69% for NACC and from 34% to 77% for ADNI, while achieving high precision. The proposed approach has important implications for improving diagnostic accuracy for non-amnestic atAD in clinical settings using only clinical testing battery and MRI.
Hierarchical Bayesian Framework for Multisource Domain Adaptation
Dec 21, 2025Multisource domain adaptation (MDA) aims to use multiple source datasets with available labels to infer labels on a target dataset without available labels for target supervision. Prior works on MDA in the literature is ad-hoc as the pretraining of source models is either based on weight sharing or uses independently trained models. This work proposes a Bayesian framework for pretraining in MDA by considering that the distributions of different source domains are typically similar. The Hierarchical Bayesian Framework uses similarity between the different source data distributions to optimize the pretraining for MDA. Experiments using the proposed Bayesian framework for MDA show that our framework improves accuracy on recognition tasks for a large benchmark dataset. Performance comparison with state-of-the-art MDA methods on the challenging problem of human action recognition in multi-domain benchmark Daily-DA RGB video shows the proposed Bayesian Framework offers a 17.29% improvement in accuracy when compared to the state-of-the-art methods in the literature.
Functional Brain Network Identification in Opioid Use Disorder Using Machine Learning Analysis of Resting-State fMRI BOLD Signals
Oct 24, 2024Understanding the neurobiology of opioid use disorder (OUD) using resting-state functional magnetic resonance imaging (rs-fMRI) may help inform treatment strategies to improve patient outcomes. Recent literature suggests temporal characteristics of rs-fMRI blood oxygenation level-dependent (BOLD) signals may offer complementary information to functional connectivity analysis. However, existing studies of OUD analyze BOLD signals using measures computed across all time points. This study, for the first time in the literature, employs data-driven machine learning (ML) modeling of rs-fMRI BOLD features representing multiple time points to identify region(s) of interest that differentiate OUD subjects from healthy controls (HC). Following the triple network model, we obtain rs-fMRI BOLD features from the default mode network (DMN), salience network (SN), and executive control network (ECN) for 31 OUD and 45 HC subjects. Then, we use the Boruta ML algorithm to identify statistically significant BOLD features that differentiate OUD from HC, identifying the DMN as the most salient functional network for OUD. Furthermore, we conduct brain activity mapping, showing heightened neural activity within the DMN for OUD. We perform 5-fold cross-validation classification (OUD vs. HC) experiments to study the discriminative power of functional network features with and without fusing demographic features. The DMN shows the most discriminative power, achieving mean AUC and F1 scores of 80.91% and 73.97%, respectively, when fusing BOLD and demographic features. Follow-up Boruta analysis using BOLD features extracted from the medial prefrontal cortex, posterior cingulate cortex, and left and right temporoparietal junctions reveals significant features for all four functional hubs within the DMN.
Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) for Improved User Engagement
Mar 12, 2024



Customizable 3D avatar-based facial expression stimuli may improve user engagement in behavioral biomarker discovery and therapeutic intervention for autism, Alzheimer's disease, facial palsy, and more. However, there is a lack of customizable avatar-based stimuli with Facial Action Coding System (FACS) action unit (AU) labels. Therefore, this study focuses on (1) FACS-labeled, customizable avatar-based expression stimuli for maintaining subjects' engagement, (2) learning-based measurements that quantify subjects' facial responses to such stimuli, and (3) validation of constructs represented by stimulus-measurement pairs. We propose Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) labeled with AUs by a certified FACS expert. To measure subjects' AUs in response to CADyFACE, we propose a novel Beta-guided Correlation and Multi-task Expression learning neural network (BeCoME-Net) for multi-label AU detection. The beta-guided correlation loss encourages feature correlation with AUs while discouraging correlation with subject identities for improved generalization. We train BeCoME-Net for unilateral and bilateral AU detection and compare with state-of-the-art approaches. To assess construct validity of CADyFACE and BeCoME-Net, twenty healthy adult volunteers complete expression recognition and mimicry tasks in an online feasibility study while webcam-based eye-tracking and video are collected. We test validity of multiple constructs, including face preference during recognition and AUs during mimicry.
Prediction of Rapid Early Progression and Survival Risk with Pre-Radiation MRI in WHO Grade 4 Glioma Patients
Jun 28, 2023



Recent clinical research describes a subset of glioblastoma patients that exhibit REP prior to start of radiation therapy. Current literature has thus far described this population using clinicopathologic features. To our knowledge, this study is the first to investigate the potential of conventional ra-diomics, sophisticated multi-resolution fractal texture features, and different molecular features (MGMT, IDH mutations) as a diagnostic and prognostic tool for prediction of REP from non-REP cases using computational and statistical modeling methods. Radiation-planning T1 post-contrast (T1C) MRI sequences of 70 patients are analyzed. Ensemble method with 5-fold cross validation over 1000 iterations offers AUC of 0.793 with standard deviation of 0.082 for REP and non-REP classification. In addition, copula-based modeling under dependent censoring (where a subset of the patients may not be followed up until death) identifies significant features (p-value <0.05) for survival probability and prognostic grouping of patient cases. The prediction of survival for the patients cohort produces precision of 0.881 with standard deviation of 0.056. The prognostic index (PI) calculated using the fused features suggests that 84.62% of REP cases fall under the bad prognostic group, suggesting potentiality of fused features to predict a higher percentage of REP cases. The experimental result further shows that mul-ti-resolution fractal texture features perform better than conventional radiomics features for REP and survival outcomes.
Deep Adaptation of Adult-Child Facial Expressions by Fusing Landmark Features
Sep 18, 2022
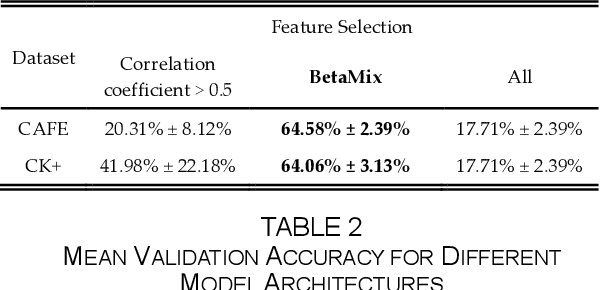

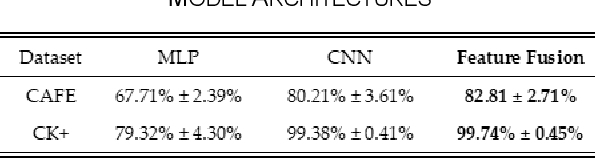
Imaging of facial affects may be used to measure psychophysiological attributes of children through their adulthood, especially for monitoring lifelong conditions like Autism Spectrum Disorder. Deep convolutional neural networks have shown promising results in classifying facial expressions of adults. However, classifier models trained with adult benchmark data are unsuitable for learning child expressions due to discrepancies in psychophysical development. Similarly, models trained with child data perform poorly in adult expression classification. We propose domain adaptation to concurrently align distributions of adult and child expressions in a shared latent space to ensure robust classification of either domain. Furthermore, age variations in facial images are studied in age-invariant face recognition yet remain unleveraged in adult-child expression classification. We take inspiration from multiple fields and propose deep adaptive FACial Expressions fusing BEtaMix SElected Landmark Features (FACE-BE-SELF) for adult-child facial expression classification. For the first time in the literature, a mixture of Beta distributions is used to decompose and select facial features based on correlations with expression, domain, and identity factors. We evaluate FACE-BE-SELF on two pairs of adult-child data sets. Our proposed FACE-BE-SELF approach outperforms adult-child transfer learning and other baseline domain adaptation methods in aligning latent representations of adult and child expressions.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021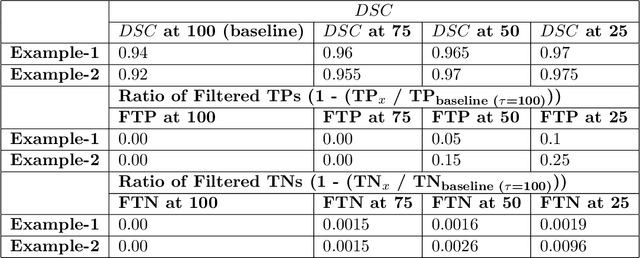
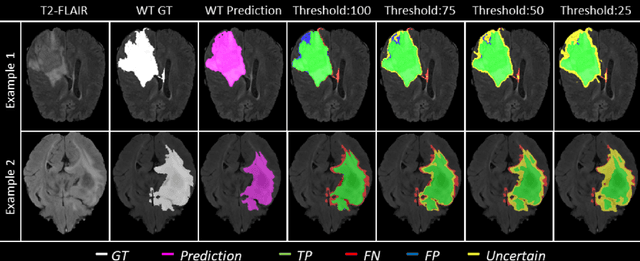
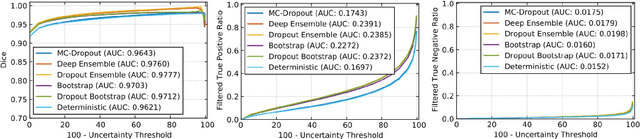
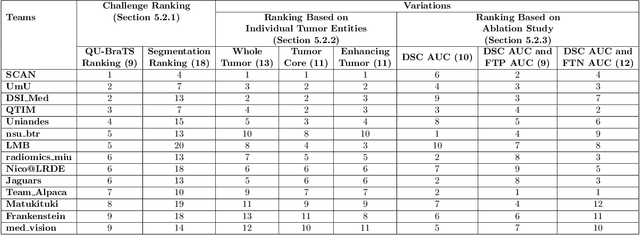
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Detecting floodwater on roadways from image data with handcrafted features and deep transfer learning
Aug 31, 2019
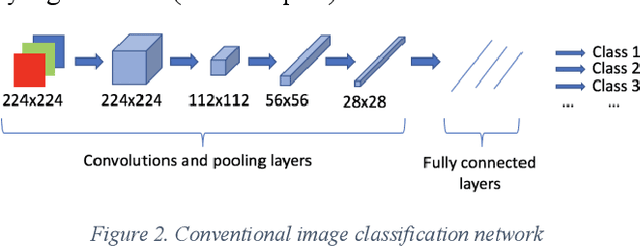
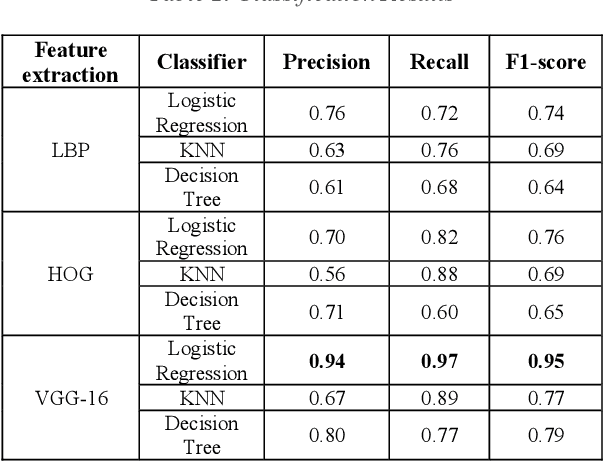
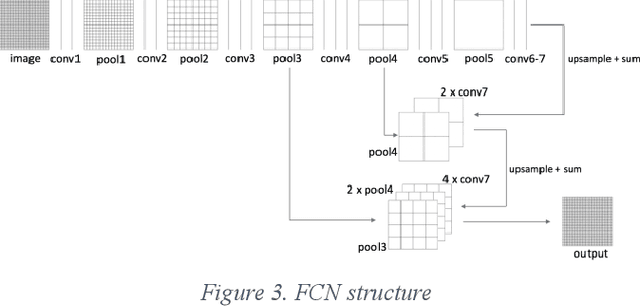
Detecting roadway segments inundated due to floodwater has important applications for vehicle routing and traffic management decisions. This paper proposes a set of algorithms to automatically detect floodwater that may be present in an image captured by mobile phones or other types of optical cameras. For this purpose, image classification and flood area segmentation methods are developed. For the classification task, we used Local Binary Patterns (LBP), Histogram of Oriented Gradients (HOG) and pre-trained deep neural network (VGG-16) as feature extractors and trained logistic regression, k-nearest neighbors, and decision tree classifiers on the extracted features. Pre-trained VGG-16 network with logistic regression classifier outperformed all other methods. For the flood area segmentation task, we investigated superpixel based methods and Fully Convolutional Neural Network (FCN). Similar to the classification task, we trained logistic regression and k-nearest neighbors classifiers on the superpixel areas and compared that with an end-to-end trained FCN. Conditional Random Fields (CRF) method was applied after both segmentation methods to post-process coarse segmentation results. FCN offered the highest scores in all metrics; it was followed by superpixel-based logistic regression and then superpixel-based KNN.
Survey on Deep Neural Networks in Speech and Vision Systems
Aug 16, 2019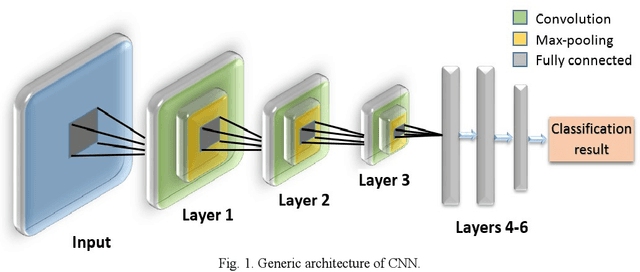
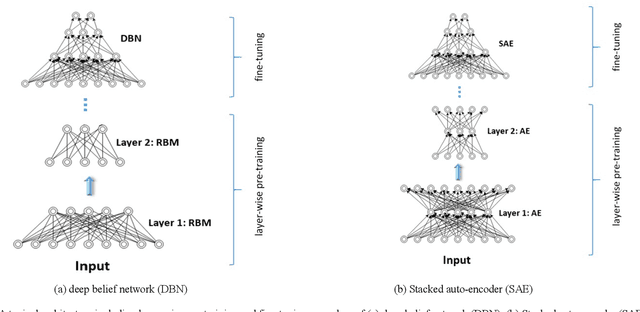
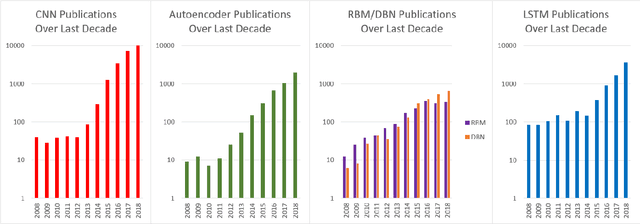
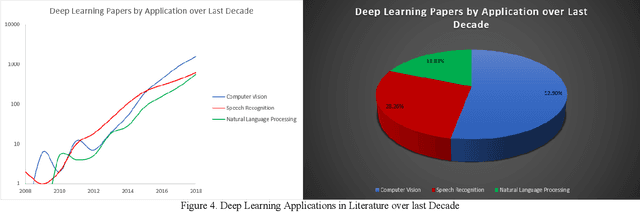
This survey presents a review of state-of-the-art deep neural network architectures, algorithms, and systems in vision and speech applications. Recent advances in deep artificial neural network algorithms and architectures have spurred rapid innovation and development of intelligent vision and speech systems. With availability of vast amounts of sensor data and cloud computing for processing and training of deep neural networks, and with increased sophistication in mobile and embedded technology, the next-generation intelligent systems are poised to revolutionize personal and commercial computing. This survey begins by providing background and evolution of some of the most successful deep learning models for intelligent vision and speech systems to date. An overview of large-scale industrial research and development efforts is provided to emphasize future trends and prospects of intelligent vision and speech systems. Robust and efficient intelligent systems demand low-latency and high fidelity in resource constrained hardware platforms such as mobile devices, robots, and automobiles. Therefore, this survey also provides a summary of key challenges and recent successes in running deep neural networks on hardware-restricted platforms, i.e. within limited memory, battery life, and processing capabilities. Finally, emerging applications of vision and speech across disciplines such as affective computing, intelligent transportation, and precision medicine are discussed. To our knowledge, this paper provides one of the most comprehensive surveys on the latest developments in intelligent vision and speech applications from the perspectives of both software and hardware systems. Many of these emerging technologies using deep neural networks show tremendous promise to revolutionize research and development for future vision and speech systems.