 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) for Improved User Engagement
Mar 12, 2024



Customizable 3D avatar-based facial expression stimuli may improve user engagement in behavioral biomarker discovery and therapeutic intervention for autism, Alzheimer's disease, facial palsy, and more. However, there is a lack of customizable avatar-based stimuli with Facial Action Coding System (FACS) action unit (AU) labels. Therefore, this study focuses on (1) FACS-labeled, customizable avatar-based expression stimuli for maintaining subjects' engagement, (2) learning-based measurements that quantify subjects' facial responses to such stimuli, and (3) validation of constructs represented by stimulus-measurement pairs. We propose Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) labeled with AUs by a certified FACS expert. To measure subjects' AUs in response to CADyFACE, we propose a novel Beta-guided Correlation and Multi-task Expression learning neural network (BeCoME-Net) for multi-label AU detection. The beta-guided correlation loss encourages feature correlation with AUs while discouraging correlation with subject identities for improved generalization. We train BeCoME-Net for unilateral and bilateral AU detection and compare with state-of-the-art approaches. To assess construct validity of CADyFACE and BeCoME-Net, twenty healthy adult volunteers complete expression recognition and mimicry tasks in an online feasibility study while webcam-based eye-tracking and video are collected. We test validity of multiple constructs, including face preference during recognition and AUs during mimicry.
Prediction of Rapid Early Progression and Survival Risk with Pre-Radiation MRI in WHO Grade 4 Glioma Patients
Jun 28, 2023



Recent clinical research describes a subset of glioblastoma patients that exhibit REP prior to start of radiation therapy. Current literature has thus far described this population using clinicopathologic features. To our knowledge, this study is the first to investigate the potential of conventional ra-diomics, sophisticated multi-resolution fractal texture features, and different molecular features (MGMT, IDH mutations) as a diagnostic and prognostic tool for prediction of REP from non-REP cases using computational and statistical modeling methods. Radiation-planning T1 post-contrast (T1C) MRI sequences of 70 patients are analyzed. Ensemble method with 5-fold cross validation over 1000 iterations offers AUC of 0.793 with standard deviation of 0.082 for REP and non-REP classification. In addition, copula-based modeling under dependent censoring (where a subset of the patients may not be followed up until death) identifies significant features (p-value <0.05) for survival probability and prognostic grouping of patient cases. The prediction of survival for the patients cohort produces precision of 0.881 with standard deviation of 0.056. The prognostic index (PI) calculated using the fused features suggests that 84.62% of REP cases fall under the bad prognostic group, suggesting potentiality of fused features to predict a higher percentage of REP cases. The experimental result further shows that mul-ti-resolution fractal texture features perform better than conventional radiomics features for REP and survival outcomes.
Deep Adaptation of Adult-Child Facial Expressions by Fusing Landmark Features
Sep 18, 2022
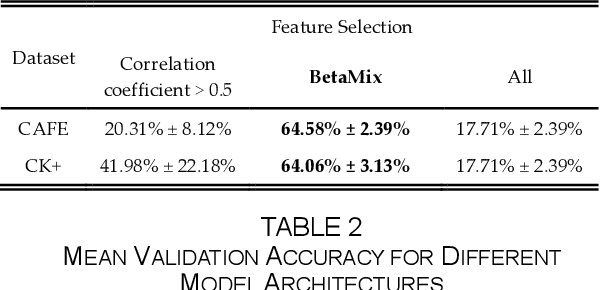

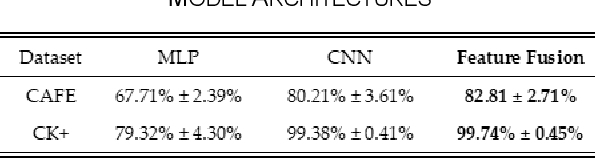
Imaging of facial affects may be used to measure psychophysiological attributes of children through their adulthood, especially for monitoring lifelong conditions like Autism Spectrum Disorder. Deep convolutional neural networks have shown promising results in classifying facial expressions of adults. However, classifier models trained with adult benchmark data are unsuitable for learning child expressions due to discrepancies in psychophysical development. Similarly, models trained with child data perform poorly in adult expression classification. We propose domain adaptation to concurrently align distributions of adult and child expressions in a shared latent space to ensure robust classification of either domain. Furthermore, age variations in facial images are studied in age-invariant face recognition yet remain unleveraged in adult-child expression classification. We take inspiration from multiple fields and propose deep adaptive FACial Expressions fusing BEtaMix SElected Landmark Features (FACE-BE-SELF) for adult-child facial expression classification. For the first time in the literature, a mixture of Beta distributions is used to decompose and select facial features based on correlations with expression, domain, and identity factors. We evaluate FACE-BE-SELF on two pairs of adult-child data sets. Our proposed FACE-BE-SELF approach outperforms adult-child transfer learning and other baseline domain adaptation methods in aligning latent representations of adult and child expressions.
Missing Value Estimation using Clustering and Deep Learning within Multiple Imputation Framework
Feb 28, 2022
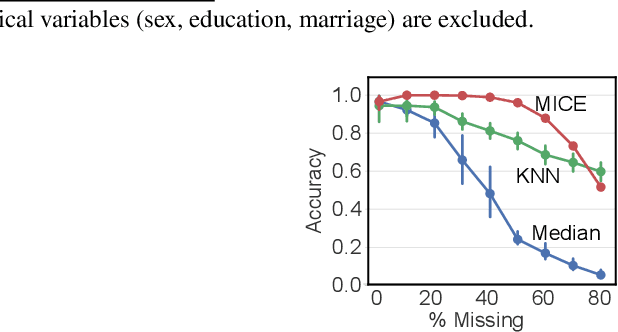
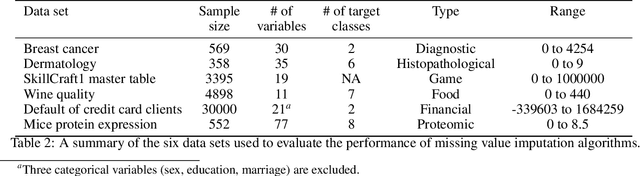
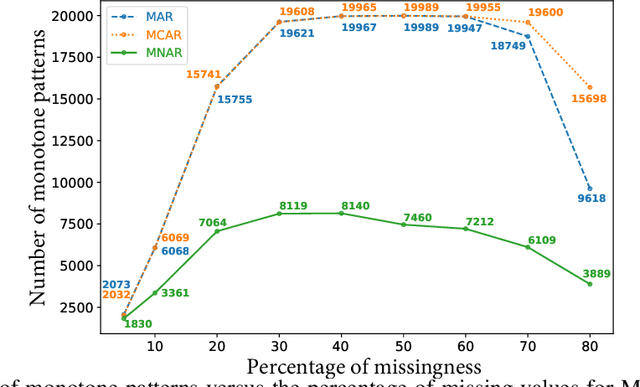
Missing values in tabular data restrict the use and performance of machine learning, requiring the imputation of missing values. The most popular imputation algorithm is arguably multiple imputations using chains of equations (MICE), which estimates missing values from linear conditioning on observed values. This paper proposes methods to improve both the imputation accuracy of MICE and the classification accuracy of imputed data by replacing MICE's linear conditioning with ensemble learning and deep neural networks (DNN). The imputation accuracy is further improved by characterizing individual samples with cluster labels (CISCL) obtained from the training data. Our extensive analyses involving six tabular data sets, up to 80% missingness, and three missingness types (missing completely at random, missing at random, missing not at random) reveal that ensemble or deep learning within MICE is superior to the baseline MICE (b-MICE), both of which are consistently outperformed by CISCL. Results show that CISCL plus b-MICE outperforms b-MICE for all percentages and types of missingness. Our proposed DNN based MICE and gradient boosting MICE plus CISCL (GB-MICE-CISCL) outperform seven other baseline imputation algorithms in most experimental cases. The classification accuracy on the data imputed by GB-MICE is improved by proposed GB-MICE-CISCL imputed data across all missingness percentages. Results also reveal a shortcoming of the MICE framework at high missingness (>50%) and when the missing type is not random. This paper provides a generalized approach to identifying the best imputation model for a data set with a missingness percentage and type.