 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing Value Estimation using Clustering and Deep Learning within Multiple Imputation Framework
Paper and Code
Feb 28, 2022
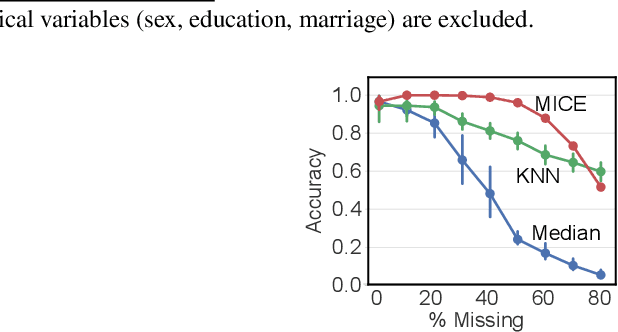
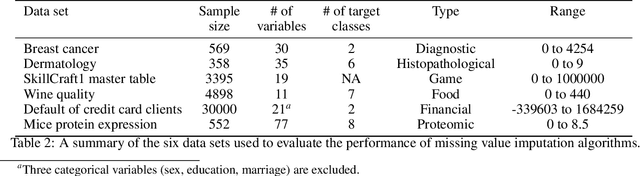
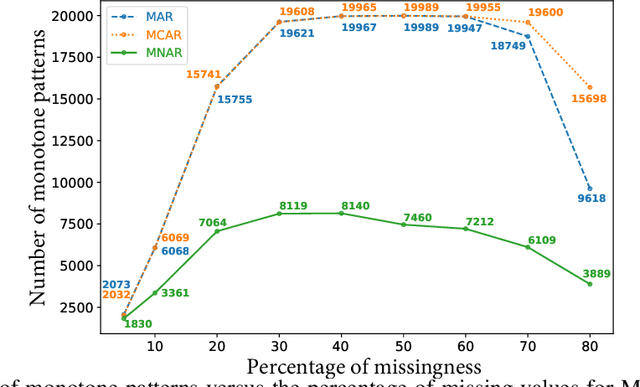
Missing values in tabular data restrict the use and performance of machine learning, requiring the imputation of missing values. The most popular imputation algorithm is arguably multiple imputations using chains of equations (MICE), which estimates missing values from linear conditioning on observed values. This paper proposes methods to improve both the imputation accuracy of MICE and the classification accuracy of imputed data by replacing MICE's linear conditioning with ensemble learning and deep neural networks (DNN). The imputation accuracy is further improved by characterizing individual samples with cluster labels (CISCL) obtained from the training data. Our extensive analyses involving six tabular data sets, up to 80% missingness, and three missingness types (missing completely at random, missing at random, missing not at random) reveal that ensemble or deep learning within MICE is superior to the baseline MICE (b-MICE), both of which are consistently outperformed by CISCL. Results show that CISCL plus b-MICE outperforms b-MICE for all percentages and types of missingness. Our proposed DNN based MICE and gradient boosting MICE plus CISCL (GB-MICE-CISCL) outperform seven other baseline imputation algorithms in most experimental cases. The classification accuracy on the data imputed by GB-MICE is improved by proposed GB-MICE-CISCL imputed data across all missingness percentages. Results also reveal a shortcoming of the MICE framework at high missingness (>50%) and when the missing type is not random. This paper provides a generalized approach to identifying the best imputation model for a data set with a missingness percentage and type.