 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-CEALS: Gaussian Cluster Embedding in Autoencoder Latent Space for Tabular Data Representation
Jan 05, 2023The latent space of autoencoders has been improved for clustering image data by jointly learning a t-distributed embedding with a clustering algorithm inspired by the neighborhood embedding concept proposed for data visualization. However, multivariate tabular data pose different challenges in representation learning than image data, where traditional machine learning is often superior to deep tabular data learning. In this paper, we address the challenges of learning tabular data in contrast to image data and present a novel Gaussian Cluster Embedding in Autoencoder Latent Space (G-CEALS) algorithm by replacing t-distributions with multivariate Gaussian clusters. Unlike current methods, the proposed approach independently defines the Gaussian embedding and the target cluster distribution to accommodate any clustering algorithm in representation learning. A trained G-CEALS model extracts a quality embedding for unseen test data. Based on the embedding clustering accuracy, the average rank of the proposed G-CEALS method is 1.4 (0.7), which is superior to all eight baseline clustering and cluster embedding methods on seven tabular data sets. This paper shows one of the first algorithms to jointly learn embedding and clustering to improve multivariate tabular data representation in downstream clustering.
Are Deep Image Embedding Clustering Methods Effective for Heterogeneous Tabular Data?
Dec 28, 2022Deep learning methods in the literature are invariably benchmarked on image data sets and then assumed to work on all data problems. Unfortunately, architectures designed for image learning are often not ready or optimal for non-image data without considering data-specific learning requirements. In this paper, we take a data-centric view to argue that deep image embedding clustering methods are not equally effective on heterogeneous tabular data sets. This paper performs one of the first studies on deep embedding clustering of seven tabular data sets using six state-of-the-art baseline methods proposed for image data sets. Our results reveal that the traditional clustering of tabular data ranks second out of eight methods and is superior to most deep embedding clustering baselines. Our observation is in line with the recent literature that traditional machine learning of tabular data is still a competitive approach against deep learning. Although surprising to many deep learning researchers, traditional clustering methods can be competitive baselines for tabular data, and outperforming these baselines remains a challenge for deep embedding clustering. Therefore, deep learning methods for image learning may not be fair or suitable baselines for tabular data without considering data-specific contrasts and learning requirements.
Perturbation of Deep Autoencoder Weights for Model Compression and Classification of Tabular Data
May 17, 2022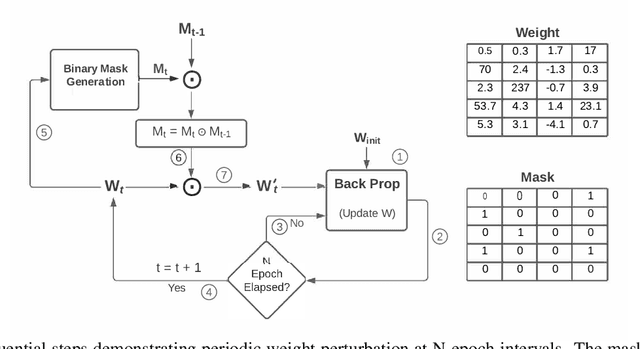
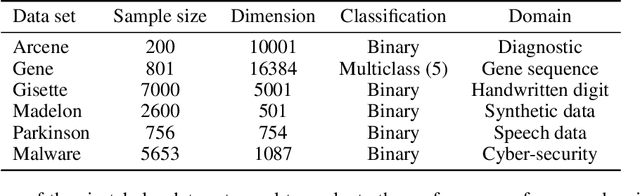
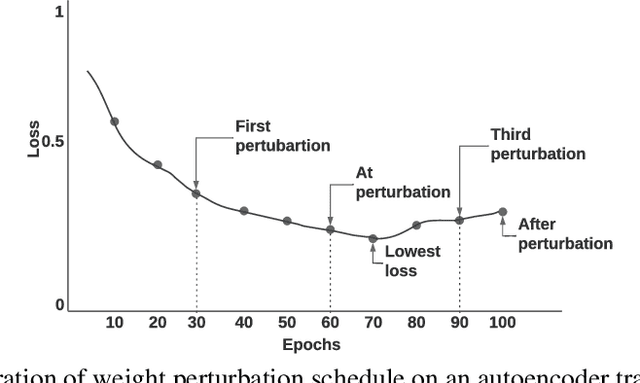
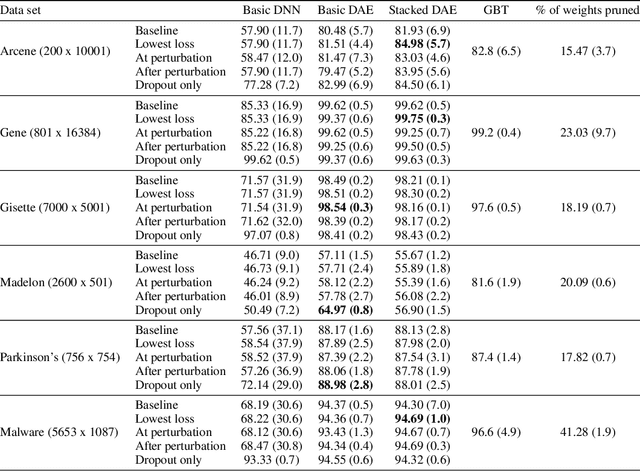
Fully connected deep neural networks (DNN) often include redundant weights leading to overfitting and high memory requirements. Additionally, the performance of DNN is often challenged by traditional machine learning models in tabular data classification. In this paper, we propose periodical perturbations (prune and regrow) of DNN weights, especially at the self-supervised pre-training stage of deep autoencoders. The proposed weight perturbation strategy outperforms dropout learning in four out of six tabular data sets in downstream classification tasks. The L1 or L2 regularization of weights at the same pretraining stage results in inferior classification performance compared to dropout or our weight perturbation routine. Unlike dropout learning, the proposed weight perturbation routine additionally achieves 15% to 40% sparsity across six tabular data sets for the compression of deep pretrained models. Our experiments reveal that a pretrained deep autoencoder with weight perturbation or dropout can outperform traditional machine learning in tabular data classification when fully connected DNN fails miserably. However, traditional machine learning models appear superior to any deep models when a tabular data set contains uncorrelated variables. Therefore, the success of deep models can be attributed to the inevitable presence of correlated variables in real-world data sets.
Missing Value Estimation using Clustering and Deep Learning within Multiple Imputation Framework
Feb 28, 2022
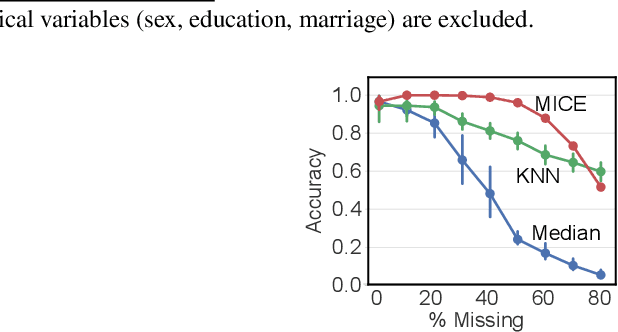
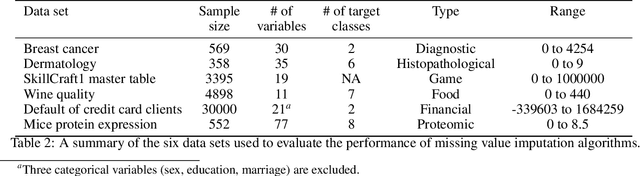
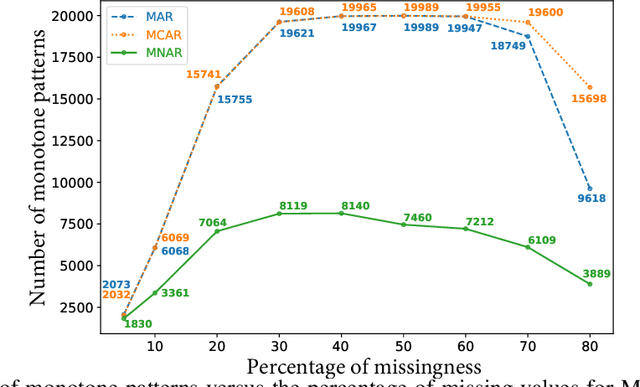
Missing values in tabular data restrict the use and performance of machine learning, requiring the imputation of missing values. The most popular imputation algorithm is arguably multiple imputations using chains of equations (MICE), which estimates missing values from linear conditioning on observed values. This paper proposes methods to improve both the imputation accuracy of MICE and the classification accuracy of imputed data by replacing MICE's linear conditioning with ensemble learning and deep neural networks (DNN). The imputation accuracy is further improved by characterizing individual samples with cluster labels (CISCL) obtained from the training data. Our extensive analyses involving six tabular data sets, up to 80% missingness, and three missingness types (missing completely at random, missing at random, missing not at random) reveal that ensemble or deep learning within MICE is superior to the baseline MICE (b-MICE), both of which are consistently outperformed by CISCL. Results show that CISCL plus b-MICE outperforms b-MICE for all percentages and types of missingness. Our proposed DNN based MICE and gradient boosting MICE plus CISCL (GB-MICE-CISCL) outperform seven other baseline imputation algorithms in most experimental cases. The classification accuracy on the data imputed by GB-MICE is improved by proposed GB-MICE-CISCL imputed data across all missingness percentages. Results also reveal a shortcoming of the MICE framework at high missingness (>50%) and when the missing type is not random. This paper provides a generalized approach to identifying the best imputation model for a data set with a missingness percentage and type.