 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning-enhanced non-amnestic Alzheimer's disease diagnosis from MRI and clinical features
Jan 25, 2026Alzheimer's disease (AD), defined as an abnormal buildup of amyloid plaques and tau tangles in the brain can be diagnosed with high accuracy based on protein biomarkers via PET or CSF analysis. However, due to the invasive nature of biomarker collection, most AD diagnoses are made in memory clinics using cognitive tests and evaluation of hippocampal atrophy based on MRI. While clinical assessment and hippocampal volume show high diagnostic accuracy for amnestic or typical AD (tAD), a substantial subgroup of AD patients with atypical presentation (atAD) are routinely misdiagnosed. To improve diagnosis of atAD patients, we propose a machine learning approach to distinguish between atAD and non-AD cognitive impairment using clinical testing battery and MRI data collected as standard-of-care. We develop and evaluate our approach using 1410 subjects across four groups (273 tAD, 184 atAD, 235 non-AD, and 685 cognitively normal) collected from one private data set and two public data sets from the National Alzheimer's Coordinating Center (NACC) and the Alzheimer's Disease Neuroimaging Initiative (ADNI). We perform multiple atAD vs. non-AD classification experiments using clinical features and hippocampal volume as well as a comprehensive set of MRI features from across the brain. The best performance is achieved by incorporating additional important MRI features, which outperforms using hippocampal volume alone. Furthermore, we use the Boruta statistical approach to identify and visualize significant brain regions distinguishing between diagnostic groups. Our ML approach improves the percentage of correctly diagnosed atAD cases (the recall) from 52% to 69% for NACC and from 34% to 77% for ADNI, while achieving high precision. The proposed approach has important implications for improving diagnostic accuracy for non-amnestic atAD in clinical settings using only clinical testing battery and MRI.
Functional Brain Network Identification in Opioid Use Disorder Using Machine Learning Analysis of Resting-State fMRI BOLD Signals
Oct 24, 2024Understanding the neurobiology of opioid use disorder (OUD) using resting-state functional magnetic resonance imaging (rs-fMRI) may help inform treatment strategies to improve patient outcomes. Recent literature suggests temporal characteristics of rs-fMRI blood oxygenation level-dependent (BOLD) signals may offer complementary information to functional connectivity analysis. However, existing studies of OUD analyze BOLD signals using measures computed across all time points. This study, for the first time in the literature, employs data-driven machine learning (ML) modeling of rs-fMRI BOLD features representing multiple time points to identify region(s) of interest that differentiate OUD subjects from healthy controls (HC). Following the triple network model, we obtain rs-fMRI BOLD features from the default mode network (DMN), salience network (SN), and executive control network (ECN) for 31 OUD and 45 HC subjects. Then, we use the Boruta ML algorithm to identify statistically significant BOLD features that differentiate OUD from HC, identifying the DMN as the most salient functional network for OUD. Furthermore, we conduct brain activity mapping, showing heightened neural activity within the DMN for OUD. We perform 5-fold cross-validation classification (OUD vs. HC) experiments to study the discriminative power of functional network features with and without fusing demographic features. The DMN shows the most discriminative power, achieving mean AUC and F1 scores of 80.91% and 73.97%, respectively, when fusing BOLD and demographic features. Follow-up Boruta analysis using BOLD features extracted from the medial prefrontal cortex, posterior cingulate cortex, and left and right temporoparietal junctions reveals significant features for all four functional hubs within the DMN.
Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) for Improved User Engagement
Mar 12, 2024



Customizable 3D avatar-based facial expression stimuli may improve user engagement in behavioral biomarker discovery and therapeutic intervention for autism, Alzheimer's disease, facial palsy, and more. However, there is a lack of customizable avatar-based stimuli with Facial Action Coding System (FACS) action unit (AU) labels. Therefore, this study focuses on (1) FACS-labeled, customizable avatar-based expression stimuli for maintaining subjects' engagement, (2) learning-based measurements that quantify subjects' facial responses to such stimuli, and (3) validation of constructs represented by stimulus-measurement pairs. We propose Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) labeled with AUs by a certified FACS expert. To measure subjects' AUs in response to CADyFACE, we propose a novel Beta-guided Correlation and Multi-task Expression learning neural network (BeCoME-Net) for multi-label AU detection. The beta-guided correlation loss encourages feature correlation with AUs while discouraging correlation with subject identities for improved generalization. We train BeCoME-Net for unilateral and bilateral AU detection and compare with state-of-the-art approaches. To assess construct validity of CADyFACE and BeCoME-Net, twenty healthy adult volunteers complete expression recognition and mimicry tasks in an online feasibility study while webcam-based eye-tracking and video are collected. We test validity of multiple constructs, including face preference during recognition and AUs during mimicry.
Deep Adaptation of Adult-Child Facial Expressions by Fusing Landmark Features
Sep 18, 2022
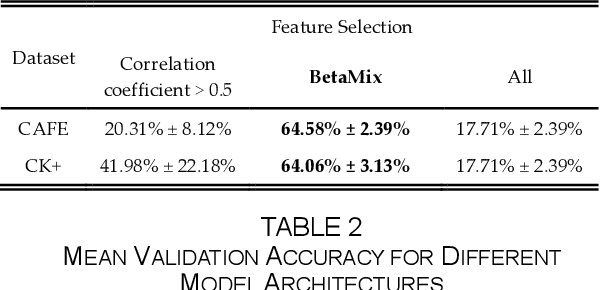

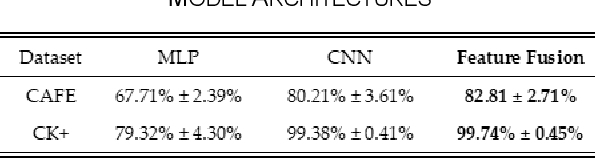
Imaging of facial affects may be used to measure psychophysiological attributes of children through their adulthood, especially for monitoring lifelong conditions like Autism Spectrum Disorder. Deep convolutional neural networks have shown promising results in classifying facial expressions of adults. However, classifier models trained with adult benchmark data are unsuitable for learning child expressions due to discrepancies in psychophysical development. Similarly, models trained with child data perform poorly in adult expression classification. We propose domain adaptation to concurrently align distributions of adult and child expressions in a shared latent space to ensure robust classification of either domain. Furthermore, age variations in facial images are studied in age-invariant face recognition yet remain unleveraged in adult-child expression classification. We take inspiration from multiple fields and propose deep adaptive FACial Expressions fusing BEtaMix SElected Landmark Features (FACE-BE-SELF) for adult-child facial expression classification. For the first time in the literature, a mixture of Beta distributions is used to decompose and select facial features based on correlations with expression, domain, and identity factors. We evaluate FACE-BE-SELF on two pairs of adult-child data sets. Our proposed FACE-BE-SELF approach outperforms adult-child transfer learning and other baseline domain adaptation methods in aligning latent representations of adult and child expressions.
Effect of Text Processing Steps on Twitter Sentiment Classification using Word Embedding
Jul 25, 2020
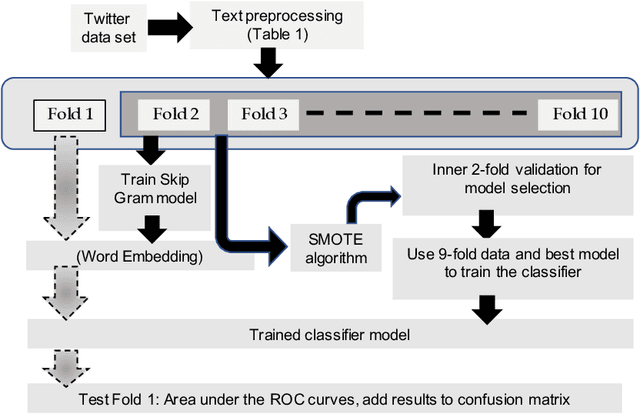

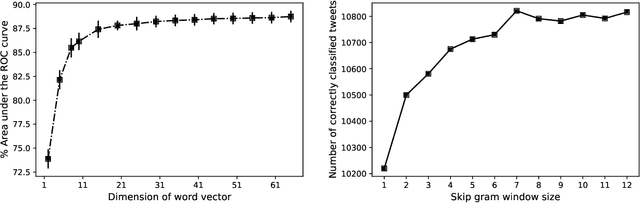
Processing of raw text is the crucial first step in text classification and sentiment analysis. However, text processing steps are often performed using off-the-shelf routines and pre-built word dictionaries without optimizing for domain, application, and context. This paper investigates the effect of seven text processing scenarios on a particular text domain (Twitter) and application (sentiment classification). Skip gram-based word embeddings are developed to include Twitter colloquial words, emojis, and hashtag keywords that are often removed for being unavailable in conventional literature corpora. Our experiments reveal negative effects on sentiment classification of two common text processing steps: 1) stop word removal and 2) averaging of word vectors to represent individual tweets. New effective steps for 1) including non-ASCII emoji characters, 2) measuring word importance from word embedding, 3) aggregating word vectors into a tweet embedding, and 4) developing linearly separable feature space have been proposed to optimize the sentiment classification pipeline. The best combination of text processing steps yields the highest average area under the curve (AUC) of 88.4 (+/-0.4) in classifying 14,640 tweets with three sentiment labels. Word selection from context-driven word embedding reveals that only the ten most important words in Tweets cumulatively yield over 98% of the maximum accuracy. Results demonstrate a means for data-driven selection of important words in tweet classification as opposed to using pre-built word dictionaries. The proposed tweet embedding is robust to and alleviates the need for several text processing steps.