 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Text Processing Steps on Twitter Sentiment Classification using Word Embedding
Jul 25, 2020

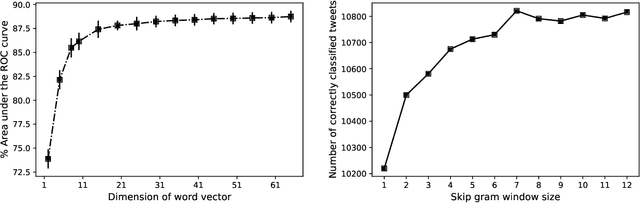
Processing of raw text is the crucial first step in text classification and sentiment analysis. However, text processing steps are often performed using off-the-shelf routines and pre-built word dictionaries without optimizing for domain, application, and context. This paper investigates the effect of seven text processing scenarios on a particular text domain (Twitter) and application (sentiment classification). Skip gram-based word embeddings are developed to include Twitter colloquial words, emojis, and hashtag keywords that are often removed for being unavailable in conventional literature corpora. Our experiments reveal negative effects on sentiment classification of two common text processing steps: 1) stop word removal and 2) averaging of word vectors to represent individual tweets. New effective steps for 1) including non-ASCII emoji characters, 2) measuring word importance from word embedding, 3) aggregating word vectors into a tweet embedding, and 4) developing linearly separable feature space have been proposed to optimize the sentiment classification pipeline. The best combination of text processing steps yields the highest average area under the curve (AUC) of 88.4 (+/-0.4) in classifying 14,640 tweets with three sentiment labels. Word selection from context-driven word embedding reveals that only the ten most important words in Tweets cumulatively yield over 98% of the maximum accuracy. Results demonstrate a means for data-driven selection of important words in tweet classification as opposed to using pre-built word dictionaries. The proposed tweet embedding is robust to and alleviates the need for several text processing steps.