 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the interplay of label bias with subgroup size and separability: A case study in mammographic density classification
Jul 24, 2025Systematic mislabelling affecting specific subgroups (i.e., label bias) in medical imaging datasets represents an understudied issue concerning the fairness of medical AI systems. In this work, we investigated how size and separability of subgroups affected by label bias influence the learned features and performance of a deep learning model. Therefore, we trained deep learning models for binary tissue density classification using the EMory BrEast imaging Dataset (EMBED), where label bias affected separable subgroups (based on imaging manufacturer) or non-separable "pseudo-subgroups". We found that simulated subgroup label bias led to prominent shifts in the learned feature representations of the models. Importantly, these shifts within the feature space were dependent on both the relative size and the separability of the subgroup affected by label bias. We also observed notable differences in subgroup performance depending on whether a validation set with clean labels was used to define the classification threshold for the model. For instance, with label bias affecting the majority separable subgroup, the true positive rate for that subgroup fell from 0.898, when the validation set had clean labels, to 0.518, when the validation set had biased labels. Our work represents a key contribution toward understanding the consequences of label bias on subgroup fairness in medical imaging AI.
Where are we with calibration under dataset shift in image classification?
Jul 10, 2025

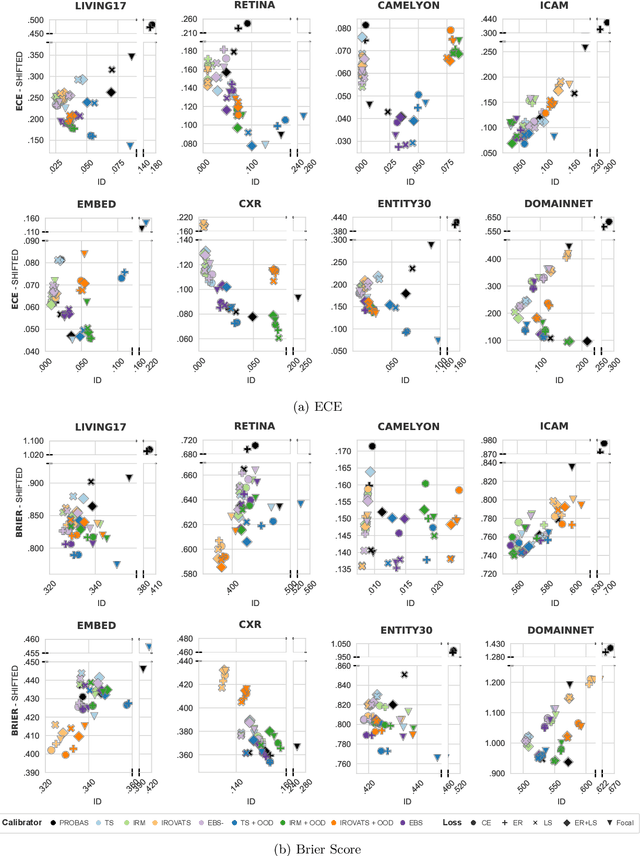
We conduct an extensive study on the state of calibration under real-world dataset shift for image classification. Our work provides important insights on the choice of post-hoc and in-training calibration techniques, and yields practical guidelines for all practitioners interested in robust calibration under shift. We compare various post-hoc calibration methods, and their interactions with common in-training calibration strategies (e.g., label smoothing), across a wide range of natural shifts, on eight different classification tasks across several imaging domains. We find that: (i) simultaneously applying entropy regularisation and label smoothing yield the best calibrated raw probabilities under dataset shift, (ii) post-hoc calibrators exposed to a small amount of semantic out-of-distribution data (unrelated to the task) are most robust under shift, (iii) recent calibration methods specifically aimed at increasing calibration under shifts do not necessarily offer significant improvements over simpler post-hoc calibration methods, (iv) improving calibration under shifts often comes at the cost of worsening in-distribution calibration. Importantly, these findings hold for randomly initialised classifiers, as well as for those finetuned from foundation models, the latter being consistently better calibrated compared to models trained from scratch. Finally, we conduct an in-depth analysis of ensembling effects, finding that (i) applying calibration prior to ensembling (instead of after) is more effective for calibration under shifts, (ii) for ensembles, OOD exposure deteriorates the ID-shifted calibration trade-off, (iii) ensembling remains one of the most effective methods to improve calibration robustness and, combined with finetuning from foundation models, yields best calibration results overall.
Decoupled Classifier-Free Guidance for Counterfactual Diffusion Models
Jun 17, 2025Counterfactual image generation aims to simulate realistic visual outcomes under specific causal interventions. Diffusion models have recently emerged as a powerful tool for this task, combining DDIM inversion with conditional generation via classifier-free guidance (CFG). However, standard CFG applies a single global weight across all conditioning variables, which can lead to poor identity preservation and spurious attribute changes - a phenomenon known as attribute amplification. To address this, we propose Decoupled Classifier-Free Guidance (DCFG), a flexible and model-agnostic framework that introduces group-wise conditioning control. DCFG builds on an attribute-split embedding strategy that disentangles semantic inputs, enabling selective guidance on user-defined attribute groups. For counterfactual generation, we partition attributes into intervened and invariant sets based on a causal graph and apply distinct guidance to each. Experiments on CelebA-HQ, MIMIC-CXR, and EMBED show that DCFG improves intervention fidelity, mitigates unintended changes, and enhances reversibility, enabling more faithful and interpretable counterfactual image generation.
Automatic dataset shift identification to support root cause analysis of AI performance drift
Nov 13, 2024Shifts in data distribution can substantially harm the performance of clinical AI models. Hence, various methods have been developed to detect the presence of such shifts at deployment time. However, root causes of dataset shifts are varied, and the choice of shift mitigation strategies is highly dependent on the precise type of shift encountered at test time. As such, detecting test-time dataset shift is not sufficient: precisely identifying which type of shift has occurred is critical. In this work, we propose the first unsupervised dataset shift identification framework, effectively distinguishing between prevalence shift (caused by a change in the label distribution), covariate shift (caused by a change in input characteristics) and mixed shifts (simultaneous prevalence and covariate shifts). We discuss the importance of self-supervised encoders for detecting subtle covariate shifts and propose a novel shift detector leveraging both self-supervised encoders and task model outputs for improved shift detection. We report promising results for the proposed shift identification framework across three different imaging modalities (chest radiography, digital mammography, and retinal fundus images) on five types of real-world dataset shifts, using four large publicly available datasets.
Debiasing Counterfactuals In the Presence of Spurious Correlations
Aug 21, 2023



Deep learning models can perform well in complex medical imaging classification tasks, even when basing their conclusions on spurious correlations (i.e. confounders), should they be prevalent in the training dataset, rather than on the causal image markers of interest. This would thereby limit their ability to generalize across the population. Explainability based on counterfactual image generation can be used to expose the confounders but does not provide a strategy to mitigate the bias. In this work, we introduce the first end-to-end training framework that integrates both (i) popular debiasing classifiers (e.g. distributionally robust optimization (DRO)) to avoid latching onto the spurious correlations and (ii) counterfactual image generation to unveil generalizable imaging markers of relevance to the task. Additionally, we propose a novel metric, Spurious Correlation Latching Score (SCLS), to quantify the extent of the classifier reliance on the spurious correlation as exposed by the counterfactual images. Through comprehensive experiments on two public datasets (with the simulated and real visual artifacts), we demonstrate that the debiasing method: (i) learns generalizable markers across the population, and (ii) successfully ignores spurious correlations and focuses on the underlying disease pathology.
Mitigating Calibration Bias Without Fixed Attribute Grouping for Improved Fairness in Medical Imaging Analysis
Jul 20, 2023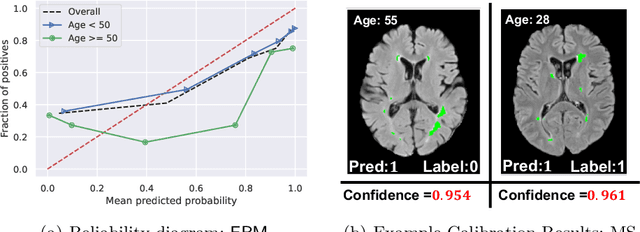
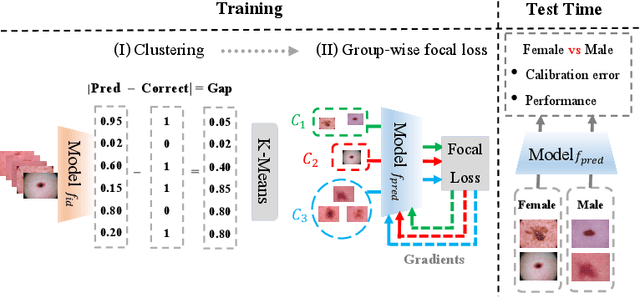

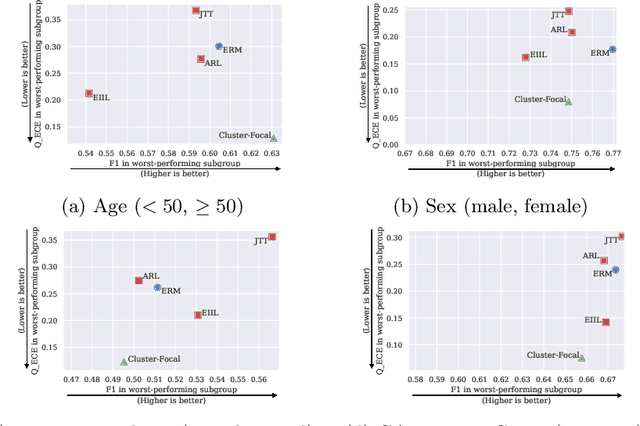
Trustworthy deployment of deep learning medical imaging models into real-world clinical practice requires that they be calibrated. However, models that are well calibrated overall can still be poorly calibrated for a sub-population, potentially resulting in a clinician unwittingly making poor decisions for this group based on the recommendations of the model. Although methods have been shown to successfully mitigate biases across subgroups in terms of model accuracy, this work focuses on the open problem of mitigating calibration biases in the context of medical image analysis. Our method does not require subgroup attributes during training, permitting the flexibility to mitigate biases for different choices of sensitive attributes without re-training. To this end, we propose a novel two-stage method: Cluster-Focal to first identify poorly calibrated samples, cluster them into groups, and then introduce group-wise focal loss to improve calibration bias. We evaluate our method on skin lesion classification with the public HAM10000 dataset, and on predicting future lesional activity for multiple sclerosis (MS) patients. In addition to considering traditional sensitive attributes (e.g. age, sex) with demographic subgroups, we also consider biases among groups with different image-derived attributes, such as lesion load, which are required in medical image analysis. Our results demonstrate that our method effectively controls calibration error in the worst-performing subgroups while preserving prediction performance, and outperforming recent baselines.
Improving Image-Based Precision Medicine with Uncertainty-Aware Causal Models
May 05, 2023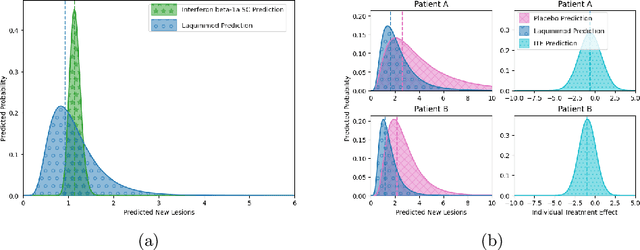
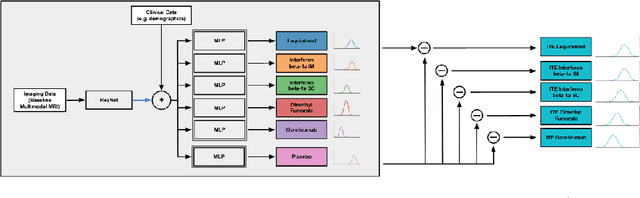
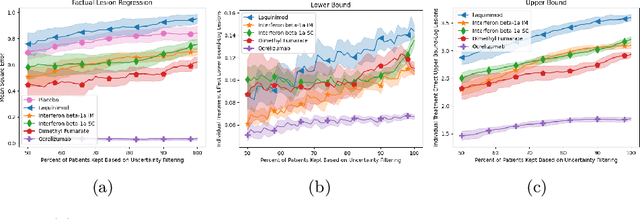
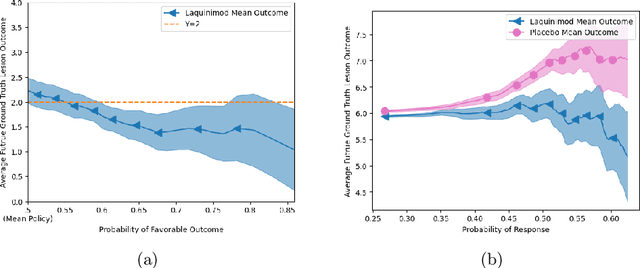
Image-based precision medicine aims to personalize treatment decisions based on an individual's unique imaging features so as to improve their clinical outcome. Machine learning frameworks that integrate uncertainty estimation as part of their treatment recommendations would be safer and more reliable. However, little work has been done in adapting uncertainty estimation techniques and validation metrics for precision medicine. In this paper, we use Bayesian deep learning for estimating the posterior distribution over factual and counterfactual outcomes on several treatments. This allows for estimating the uncertainty for each treatment option and for the individual treatment effects (ITE) between any two treatments. We train and evaluate this model to predict future new and enlarging T2 lesion counts on a large, multi-center dataset of MR brain images of patients with multiple sclerosis, exposed to several treatments during randomized controlled trials. We evaluate the correlation of the uncertainty estimate with the factual error, and, given the lack of ground truth counterfactual outcomes, demonstrate how uncertainty for the ITE prediction relates to bounds on the ITE error. Lastly, we demonstrate how knowledge of uncertainty could modify clinical decision-making to improve individual patient and clinical trial outcomes.
Evaluating the Fairness of Deep Learning Uncertainty Estimates in Medical Image Analysis
Mar 06, 2023



Although deep learning (DL) models have shown great success in many medical image analysis tasks, deployment of the resulting models into real clinical contexts requires: (1) that they exhibit robustness and fairness across different sub-populations, and (2) that the confidence in DL model predictions be accurately expressed in the form of uncertainties. Unfortunately, recent studies have indeed shown significant biases in DL models across demographic subgroups (e.g., race, sex, age) in the context of medical image analysis, indicating a lack of fairness in the models. Although several methods have been proposed in the ML literature to mitigate a lack of fairness in DL models, they focus entirely on the absolute performance between groups without considering their effect on uncertainty estimation. In this work, we present the first exploration of the effect of popular fairness models on overcoming biases across subgroups in medical image analysis in terms of bottom-line performance, and their effects on uncertainty quantification. We perform extensive experiments on three different clinically relevant tasks: (i) skin lesion classification, (ii) brain tumour segmentation, and (iii) Alzheimer's disease clinical score regression. Our results indicate that popular ML methods, such as data-balancing and distributionally robust optimization, succeed in mitigating fairness issues in terms of the model performances for some of the tasks. However, this can come at the cost of poor uncertainty estimates associated with the model predictions. This tradeoff must be mitigated if fairness models are to be adopted in medical image analysis.
You Only Need a Good Embeddings Extractor to Fix Spurious Correlations
Dec 12, 2022Spurious correlations in training data often lead to robustness issues since models learn to use them as shortcuts. For example, when predicting whether an object is a cow, a model might learn to rely on its green background, so it would do poorly on a cow on a sandy background. A standard dataset for measuring state-of-the-art on methods mitigating this problem is Waterbirds. The best method (Group Distributionally Robust Optimization - GroupDRO) currently achieves 89\% worst group accuracy and standard training from scratch on raw images only gets 72\%. GroupDRO requires training a model in an end-to-end manner with subgroup labels. In this paper, we show that we can achieve up to 90\% accuracy without using any sub-group information in the training set by simply using embeddings from a large pre-trained vision model extractor and training a linear classifier on top of it. With experiments on a wide range of pre-trained models and pre-training datasets, we show that the capacity of the pre-training model and the size of the pre-training dataset matters. Our experiments reveal that high capacity vision transformers perform better compared to high capacity convolutional neural networks, and larger pre-training dataset leads to better worst-group accuracy on the spurious correlation dataset.
Rethinking Generalization: The Impact of Annotation Style on Medical Image Segmentation
Oct 31, 2022Generalization is an important attribute of machine learning models, particularly for those that are to be deployed in a medical context, where unreliable predictions can have real world consequences. While the failure of models to generalize across datasets is typically attributed to a mismatch in the data distributions, performance gaps are often a consequence of biases in the ``ground-truth" label annotations. This is particularly important in the context of medical image segmentation of pathological structures (e.g. lesions), where the annotation process is much more subjective, and affected by a number underlying factors, including the annotation protocol, rater education/experience, and clinical aims, among others. In this paper, we show that modeling annotation biases, rather than ignoring them, poses a promising way of accounting for differences in annotation style across datasets. To this end, we propose a generalized conditioning framework to (1) learn and account for different annotation styles across multiple datasets using a single model, (2) identify similar annotation styles across different datasets in order to permit their effective aggregation, and (3) fine-tune a fully trained model to a new annotation style with just a few samples. Next, we present an image-conditioning approach to model annotation styles that correlate with specific image features, potentially enabling detection biases to be more easily identified.