 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Erasure in Text-to-Image Diffusion-based Foundation Models
Mar 25, 2025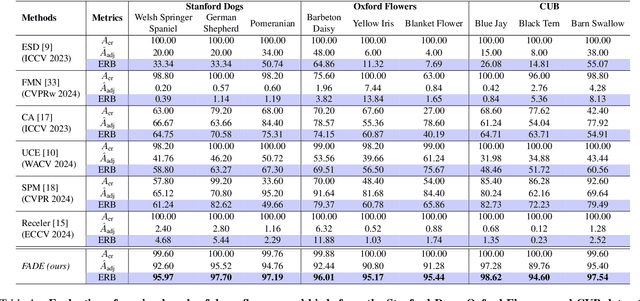
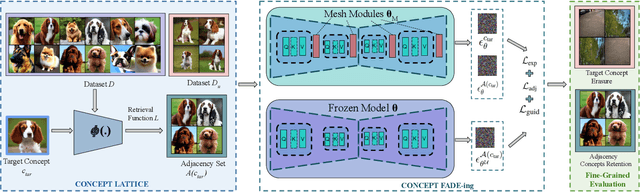
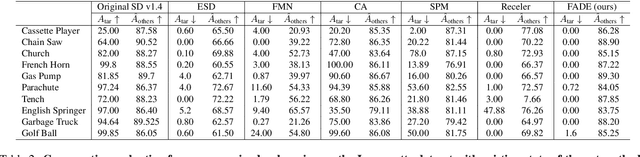
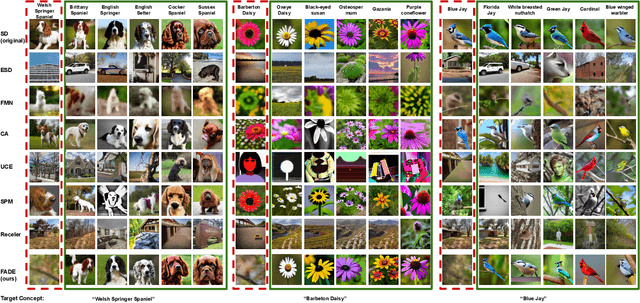
Existing unlearning algorithms in text-to-image generative models often fail to preserve the knowledge of semantically related concepts when removing specific target concepts: a challenge known as adjacency. To address this, we propose FADE (Fine grained Attenuation for Diffusion Erasure), introducing adjacency aware unlearning in diffusion models. FADE comprises two components: (1) the Concept Neighborhood, which identifies an adjacency set of related concepts, and (2) Mesh Modules, employing a structured combination of Expungement, Adjacency, and Guidance loss components. These enable precise erasure of target concepts while preserving fidelity across related and unrelated concepts. Evaluated on datasets like Stanford Dogs, Oxford Flowers, CUB, I2P, Imagenette, and ImageNet1k, FADE effectively removes target concepts with minimal impact on correlated concepts, achieving atleast a 12% improvement in retention performance over state-of-the-art methods.
Continual Unlearning for Foundational Text-to-Image Models without Generalization Erosion
Mar 17, 2025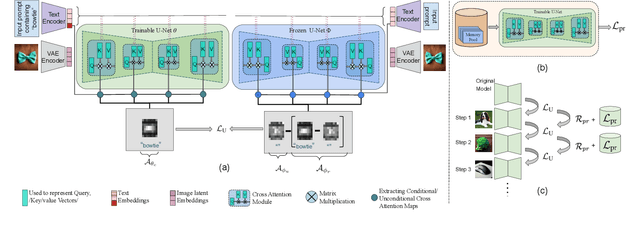

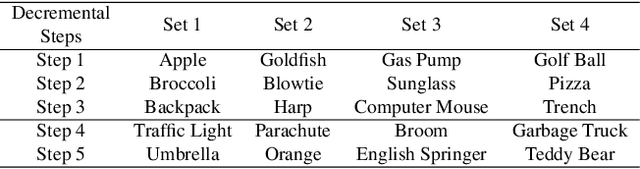

How can we effectively unlearn selected concepts from pre-trained generative foundation models without resorting to extensive retraining? This research introduces `continual unlearning', a novel paradigm that enables the targeted removal of multiple specific concepts from foundational generative models, incrementally. We propose Decremental Unlearning without Generalization Erosion (DUGE) algorithm which selectively unlearns the generation of undesired concepts while preserving the generation of related, non-targeted concepts and alleviating generalization erosion. For this, DUGE targets three losses: a cross-attention loss that steers the focus towards images devoid of the target concept; a prior-preservation loss that safeguards knowledge related to non-target concepts; and a regularization loss that prevents the model from suffering from generalization erosion. Experimental results demonstrate the ability of the proposed approach to exclude certain concepts without compromising the overall integrity and performance of the model. This offers a pragmatic solution for refining generative models, adeptly handling the intricacies of model training and concept management lowering the risks of copyright infringement, personal or licensed material misuse, and replication of distinctive artistic styles. Importantly, it maintains the non-targeted concepts, thereby safeguarding the model's core capabilities and effectiveness.
Navigating Text-to-Image Generative Bias across Indic Languages
Aug 01, 2024


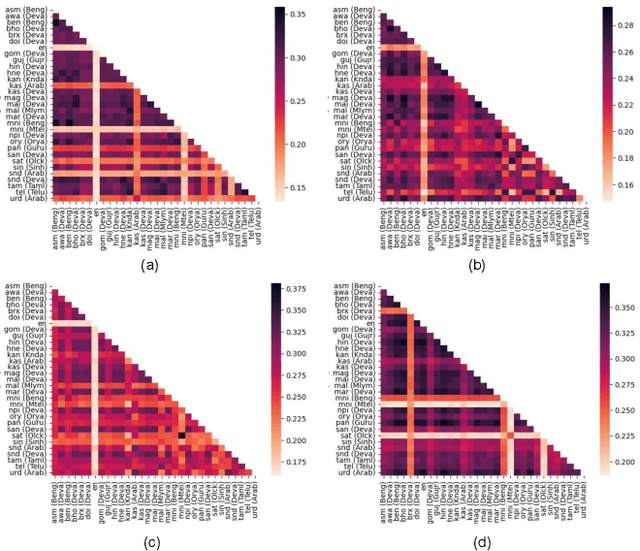
This research investigates biases in text-to-image (TTI) models for the Indic languages widely spoken across India. It evaluates and compares the generative performance and cultural relevance of leading TTI models in these languages against their performance in English. Using the proposed IndicTTI benchmark, we comprehensively assess the performance of 30 Indic languages with two open-source diffusion models and two commercial generation APIs. The primary objective of this benchmark is to evaluate the support for Indic languages in these models and identify areas needing improvement. Given the linguistic diversity of 30 languages spoken by over 1.4 billion people, this benchmark aims to provide a detailed and insightful analysis of TTI models' effectiveness within the Indic linguistic landscape. The data and code for the IndicTTI benchmark can be accessed at https://iab-rubric.org/resources/other-databases/indictti.
HyperMix: Out-of-Distribution Detection and Classification in Few-Shot Settings
Dec 22, 2023
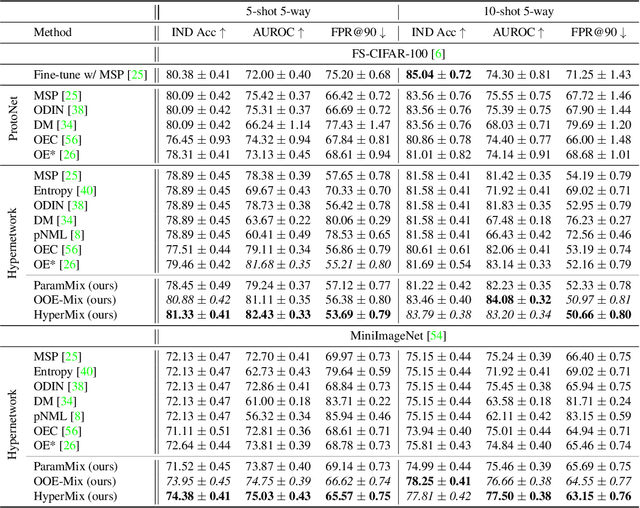
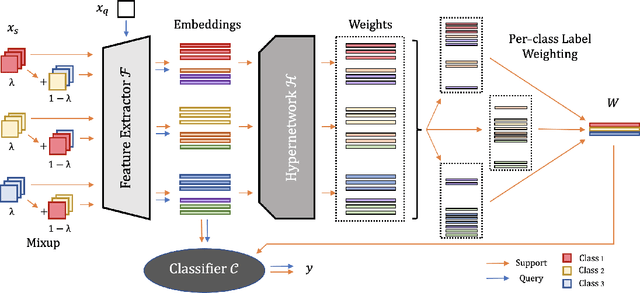
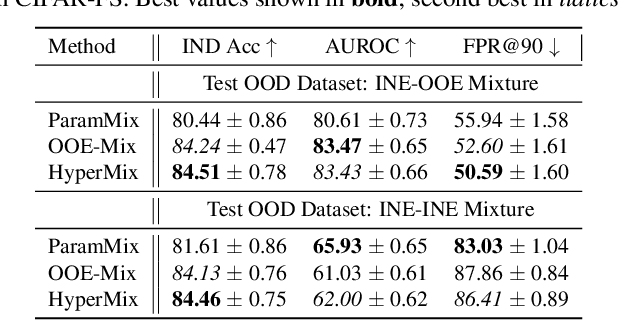
Out-of-distribution (OOD) detection is an important topic for real-world machine learning systems, but settings with limited in-distribution samples have been underexplored. Such few-shot OOD settings are challenging, as models have scarce opportunities to learn the data distribution before being tasked with identifying OOD samples. Indeed, we demonstrate that recent state-of-the-art OOD methods fail to outperform simple baselines in the few-shot setting. We thus propose a hypernetwork framework called HyperMix, using Mixup on the generated classifier parameters, as well as a natural out-of-episode outlier exposure technique that does not require an additional outlier dataset. We conduct experiments on CIFAR-FS and MiniImageNet, significantly outperforming other OOD methods in the few-shot regime.
Simple Transferability Estimation for Regression Tasks
Dec 04, 2023
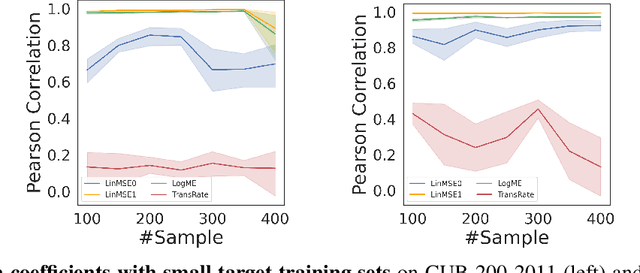
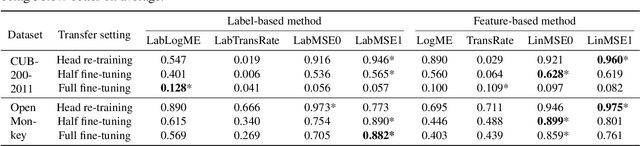
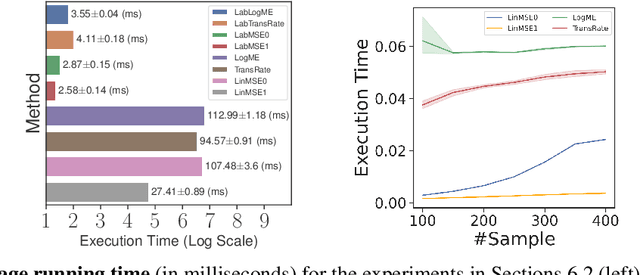
We consider transferability estimation, the problem of estimating how well deep learning models transfer from a source to a target task. We focus on regression tasks, which received little previous attention, and propose two simple and computationally efficient approaches that estimate transferability based on the negative regularized mean squared error of a linear regression model. We prove novel theoretical results connecting our approaches to the actual transferability of the optimal target models obtained from the transfer learning process. Despite their simplicity, our approaches significantly outperform existing state-of-the-art regression transferability estimators in both accuracy and efficiency. On two large-scale keypoint regression benchmarks, our approaches yield 12% to 36% better results on average while being at least 27% faster than previous state-of-the-art methods.
On Responsible Machine Learning Datasets with Fairness, Privacy, and Regulatory Norms
Oct 31, 2023
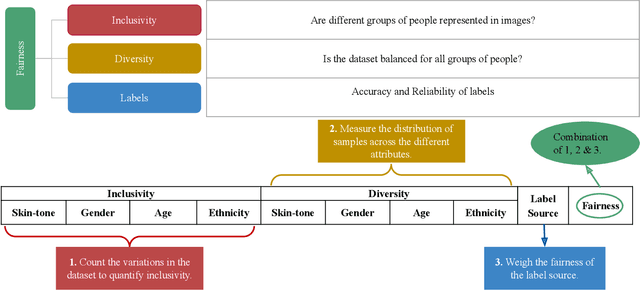


Artificial Intelligence (AI) has made its way into various scientific fields, providing astonishing improvements over existing algorithms for a wide variety of tasks. In recent years, there have been severe concerns over the trustworthiness of AI technologies. The scientific community has focused on the development of trustworthy AI algorithms. However, machine and deep learning algorithms, popular in the AI community today, depend heavily on the data used during their development. These learning algorithms identify patterns in the data, learning the behavioral objective. Any flaws in the data have the potential to translate directly into algorithms. In this study, we discuss the importance of Responsible Machine Learning Datasets and propose a framework to evaluate the datasets through a responsible rubric. While existing work focuses on the post-hoc evaluation of algorithms for their trustworthiness, we provide a framework that considers the data component separately to understand its role in the algorithm. We discuss responsible datasets through the lens of fairness, privacy, and regulatory compliance and provide recommendations for constructing future datasets. After surveying over 100 datasets, we use 60 datasets for analysis and demonstrate that none of these datasets is immune to issues of fairness, privacy preservation, and regulatory compliance. We provide modifications to the ``datasheets for datasets" with important additions for improved dataset documentation. With governments around the world regularizing data protection laws, the method for the creation of datasets in the scientific community requires revision. We believe this study is timely and relevant in today's era of AI.
MaLP: Manipulation Localization Using a Proactive Scheme
Apr 04, 2023



Advancements in the generation quality of various Generative Models (GMs) has made it necessary to not only perform binary manipulation detection but also localize the modified pixels in an image. However, prior works termed as passive for manipulation localization exhibit poor generalization performance over unseen GMs and attribute modifications. To combat this issue, we propose a proactive scheme for manipulation localization, termed MaLP. We encrypt the real images by adding a learned template. If the image is manipulated by any GM, this added protection from the template not only aids binary detection but also helps in identifying the pixels modified by the GM. The template is learned by leveraging local and global-level features estimated by a two-branch architecture. We show that MaLP performs better than prior passive works. We also show the generalizability of MaLP by testing on 22 different GMs, providing a benchmark for future research on manipulation localization. Finally, we show that MaLP can be used as a discriminator for improving the generation quality of GMs. Our models/codes are available at www.github.com/vishal3477/pro_loc.
You Only Need a Good Embeddings Extractor to Fix Spurious Correlations
Dec 12, 2022Spurious correlations in training data often lead to robustness issues since models learn to use them as shortcuts. For example, when predicting whether an object is a cow, a model might learn to rely on its green background, so it would do poorly on a cow on a sandy background. A standard dataset for measuring state-of-the-art on methods mitigating this problem is Waterbirds. The best method (Group Distributionally Robust Optimization - GroupDRO) currently achieves 89\% worst group accuracy and standard training from scratch on raw images only gets 72\%. GroupDRO requires training a model in an end-to-end manner with subgroup labels. In this paper, we show that we can achieve up to 90\% accuracy without using any sub-group information in the training set by simply using embeddings from a large pre-trained vision model extractor and training a linear classifier on top of it. With experiments on a wide range of pre-trained models and pre-training datasets, we show that the capacity of the pre-training model and the size of the pre-training dataset matters. Our experiments reveal that high capacity vision transformers perform better compared to high capacity convolutional neural networks, and larger pre-training dataset leads to better worst-group accuracy on the spurious correlation dataset.
A Whac-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others
Dec 09, 2022



Machine learning models have been found to learn shortcuts -- unintended decision rules that are unable to generalize -- undermining models' reliability. Previous works address this problem under the tenuous assumption that only a single shortcut exists in the training data. Real-world images are rife with multiple visual cues from background to texture. Key to advancing the reliability of vision systems is understanding whether existing methods can overcome multiple shortcuts or struggle in a Whac-A-Mole game, i.e., where mitigating one shortcut amplifies reliance on others. To address this shortcoming, we propose two benchmarks: 1) UrbanCars, a dataset with precisely controlled spurious cues, and 2) ImageNet-W, an evaluation set based on ImageNet for watermark, a shortcut we discovered affects nearly every modern vision model. Along with texture and background, ImageNet-W allows us to study multiple shortcuts emerging from training on natural images. We find computer vision models, including large foundation models -- regardless of training set, architecture, and supervision -- struggle when multiple shortcuts are present. Even methods explicitly designed to combat shortcuts struggle in a Whac-A-Mole dilemma. To tackle this challenge, we propose Last Layer Ensemble, a simple-yet-effective method to mitigate multiple shortcuts without Whac-A-Mole behavior. Our results surface multi-shortcut mitigation as an overlooked challenge critical to advancing the reliability of vision systems. The datasets and code are released: https://github.com/facebookresearch/Whac-A-Mole.git.
GliTr: Glimpse Transformers with Spatiotemporal Consistency for Online Action Prediction
Oct 24, 2022Many online action prediction models observe complete frames to locate and attend to informative subregions in the frames called glimpses and recognize an ongoing action based on global and local information. However, in applications with constrained resources, an agent may not be able to observe the complete frame, yet must still locate useful glimpses to predict an incomplete action based on local information only. In this paper, we develop Glimpse Transformers (GliTr), which observe only narrow glimpses at all times, thus predicting an ongoing action and the following most informative glimpse location based on the partial spatiotemporal information collected so far. In the absence of a ground truth for the optimal glimpse locations for action recognition, we train GliTr using a novel spatiotemporal consistency objective: We require GliTr to attend to the glimpses with features similar to the corresponding complete frames (i.e. spatial consistency) and the resultant class logits at time t equivalent to the ones predicted using whole frames up to t (i.e. temporal consistency). Inclusion of our proposed consistency objective yields ~10% higher accuracy on the Something-Something-v2 (SSv2) dataset than the baseline cross-entropy objective. Overall, despite observing only ~33% of the total area per frame, GliTr achieves 53.02%and 93.91% accuracy on the SSv2 and Jester datasets, respectively.