 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWith Great Backbones Comes Great Adversarial Transferability
Jan 21, 2025



Advances in self-supervised learning (SSL) for machine vision have improved representation robustness and model performance, giving rise to pre-trained backbones like \emph{ResNet} and \emph{ViT} models tuned with SSL methods such as \emph{SimCLR}. Due to the computational and data demands of pre-training, the utilization of such backbones becomes a strenuous necessity. However, employing these backbones may inherit vulnerabilities to adversarial attacks. While adversarial robustness has been studied under \emph{white-box} and \emph{black-box} settings, the robustness of models tuned on pre-trained backbones remains largely unexplored. Additionally, the role of tuning meta-information in mitigating exploitation risks is unclear. This work systematically evaluates the adversarial robustness of such models across $20,000$ combinations of tuning meta-information, including fine-tuning techniques, backbone families, datasets, and attack types. We propose using proxy models to transfer attacks, simulating varying levels of target knowledge by fine-tuning these proxies with diverse configurations. Our findings reveal that proxy-based attacks approach the effectiveness of \emph{white-box} methods, even with minimal tuning knowledge. We also introduce a naive "backbone attack," leveraging only the backbone to generate adversarial samples, which outperforms \emph{black-box} attacks and rivals \emph{white-box} methods, highlighting critical risks in model-sharing practices. Finally, our ablations reveal how increasing tuning meta-information impacts attack transferability, measuring each meta-information combination.
How Aligned are Generative Models to Humans in High-Stakes Decision-Making?
Oct 20, 2024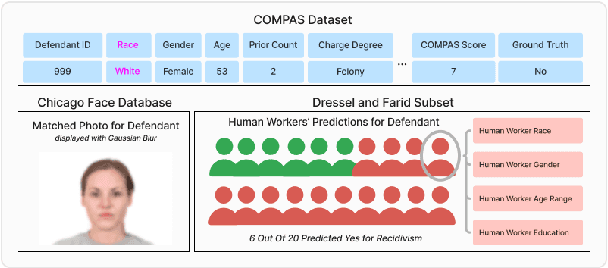


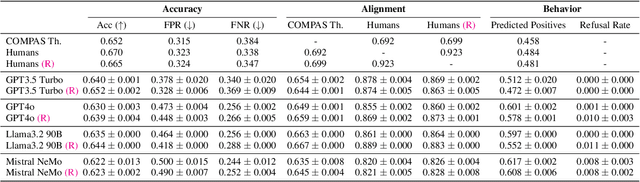
Large generative models (LMs) are increasingly being considered for high-stakes decision-making. This work considers how such models compare to humans and predictive AI models on a specific case of recidivism prediction. We combine three datasets -- COMPAS predictive AI risk scores, human recidivism judgements, and photos -- into a dataset on which we study the properties of several state-of-the-art, multimodal LMs. Beyond accuracy and bias, we focus on studying human-LM alignment on the task of recidivism prediction. We investigate if these models can be steered towards human decisions, the impact of adding photos, and whether anti-discimination prompting is effective. We find that LMs can be steered to outperform humans and COMPAS using in context-learning. We find anti-discrimination prompting to have unintended effects, causing some models to inhibit themselves and significantly reduce their number of positive predictions.
A Whac-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others
Dec 09, 2022



Machine learning models have been found to learn shortcuts -- unintended decision rules that are unable to generalize -- undermining models' reliability. Previous works address this problem under the tenuous assumption that only a single shortcut exists in the training data. Real-world images are rife with multiple visual cues from background to texture. Key to advancing the reliability of vision systems is understanding whether existing methods can overcome multiple shortcuts or struggle in a Whac-A-Mole game, i.e., where mitigating one shortcut amplifies reliance on others. To address this shortcoming, we propose two benchmarks: 1) UrbanCars, a dataset with precisely controlled spurious cues, and 2) ImageNet-W, an evaluation set based on ImageNet for watermark, a shortcut we discovered affects nearly every modern vision model. Along with texture and background, ImageNet-W allows us to study multiple shortcuts emerging from training on natural images. We find computer vision models, including large foundation models -- regardless of training set, architecture, and supervision -- struggle when multiple shortcuts are present. Even methods explicitly designed to combat shortcuts struggle in a Whac-A-Mole dilemma. To tackle this challenge, we propose Last Layer Ensemble, a simple-yet-effective method to mitigate multiple shortcuts without Whac-A-Mole behavior. Our results surface multi-shortcut mitigation as an overlooked challenge critical to advancing the reliability of vision systems. The datasets and code are released: https://github.com/facebookresearch/Whac-A-Mole.git.
Generating High Fidelity Data from Low-density Regions using Diffusion Models
Mar 31, 2022
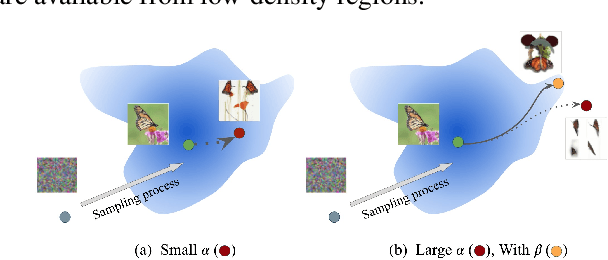

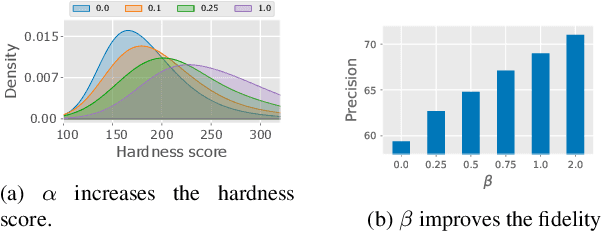
Our work focuses on addressing sample deficiency from low-density regions of data manifold in common image datasets. We leverage diffusion process based generative models to synthesize novel images from low-density regions. We observe that uniform sampling from diffusion models predominantly samples from high-density regions of the data manifold. Therefore, we modify the sampling process to guide it towards low-density regions while simultaneously maintaining the fidelity of synthetic data. We rigorously demonstrate that our process successfully generates novel high fidelity samples from low-density regions. We further examine generated samples and show that the model does not memorize low-density data and indeed learns to generate novel samples from low-density regions.
Large-Scale Attribute-Object Compositions
May 24, 2021

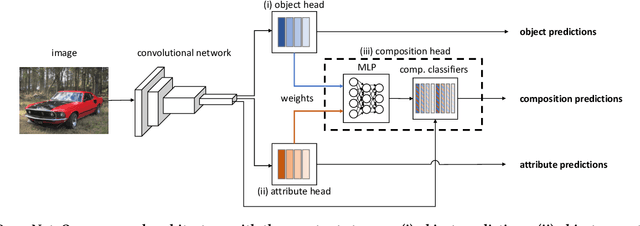
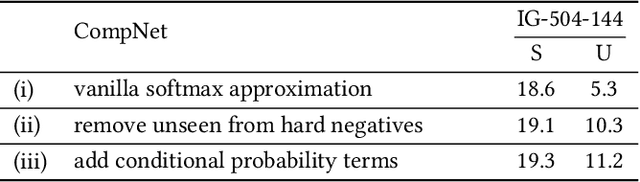
We study the problem of learning how to predict attribute-object compositions from images, and its generalization to unseen compositions missing from the training data. To the best of our knowledge, this is a first large-scale study of this problem, involving hundreds of thousands of compositions. We train our framework with images from Instagram using hashtags as noisy weak supervision. We make careful design choices for data collection and modeling, in order to handle noisy annotations and unseen compositions. Finally, extensive evaluations show that learning to compose classifiers outperforms late fusion of individual attribute and object predictions, especially in the case of unseen attribute-object pairs.
Towards measuring fairness in AI: the Casual Conversations dataset
Apr 06, 2021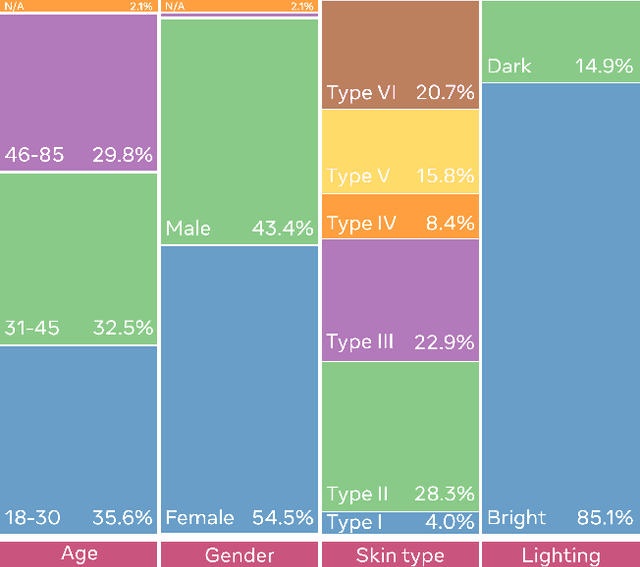



This paper introduces a novel dataset to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of age, genders, apparent skin tones and ambient lighting conditions. Our dataset is composed of 3,011 subjects and contains over 45,000 videos, with an average of 15 videos per person. The videos were recorded in multiple U.S. states with a diverse set of adults in various age, gender and apparent skin tone groups. A key feature is that each subject agreed to participate for their likenesses to be used. Additionally, our age and gender annotations are provided by the subjects themselves. A group of trained annotators labeled the subjects' apparent skin tone using the Fitzpatrick skin type scale. Moreover, annotations for videos recorded in low ambient lighting are also provided. As an application to measure robustness of predictions across certain attributes, we provide a comprehensive study on the top five winners of the DeepFake Detection Challenge (DFDC). Experimental evaluation shows that the winning models are less performant on some specific groups of people, such as subjects with darker skin tones and thus may not generalize to all people. In addition, we also evaluate the state-of-the-art apparent age and gender classification methods. Our experiments provides a through analysis on these models in terms of fair treatment of people from various backgrounds.
Attention-Based Query Expansion Learning
Jul 15, 2020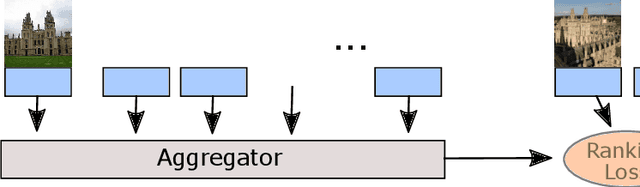

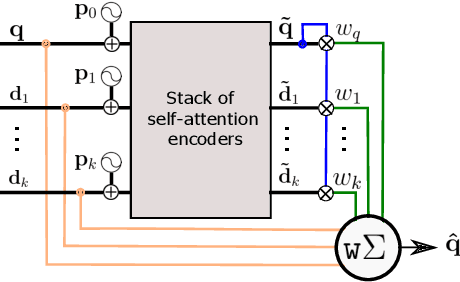
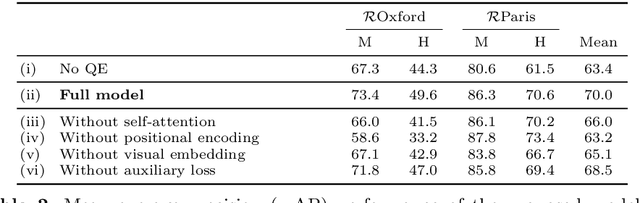
Query expansion is a technique widely used in image search consisting in combining highly ranked images from an original query into an expanded query that is then reissued, generally leading to increased recall and precision. An important aspect of query expansion is choosing an appropriate way to combine the images into a new query. Interestingly, despite the undeniable empirical success of query expansion, ad-hoc methods with different caveats have dominated the landscape, and not a lot of research has been done on learning how to do query expansion. In this paper we propose a more principled framework to query expansion, where one trains, in a discriminative manner, a model that learns how images should be aggregated to form the expanded query. Within this framework, we propose a model that leverages a self-attention mechanism to effectively learn how to transfer information between the different images before aggregating them. Our approach obtains higher accuracy than existing approaches on standard benchmarks. More importantly, our approach is the only one that consistently shows high accuracy under different regimes, overcoming caveats of existing methods.
Using Hindsight to Anchor Past Knowledge in Continual Learning
Feb 19, 2020
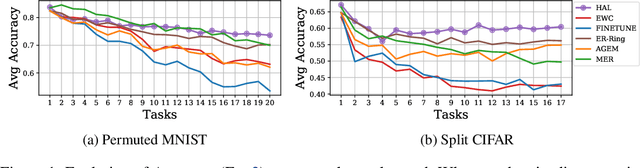

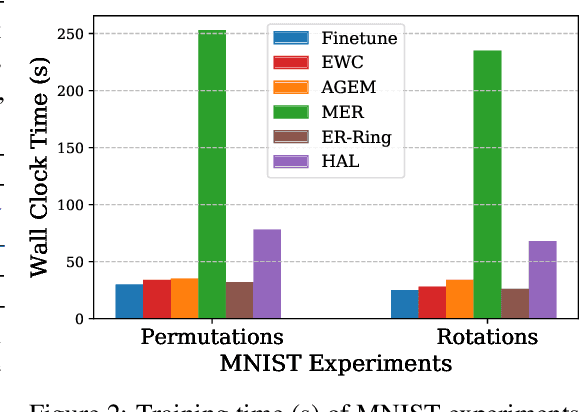
In continual learning, the learner faces a stream of data whose distribution changes over time. Modern neural networks are known to suffer under this setting, as they quickly forget previously acquired knowledge. To address such catastrophic forgetting, many continual learning methods implement different types of experience replay, re-learning on past data stored in a small buffer known as episodic memory. In this work, we complement experience replay with a new objective that we call anchoring, where the learner uses bilevel optimization to update its knowledge on the current task, while keeping intact the predictions on some anchor points of past tasks. These anchor points are learned using gradient-based optimization to maximize forgetting, which is approximated by fine-tuning the currently trained model on the episodic memory of past tasks. Experiments on several supervised learning benchmarks for continual learning demonstrate that our approach improves the standard experience replay in terms of both accuracy and forgetting metrics and for various sizes of episodic memories.
Decoupling Representation and Classifier for Long-Tailed Recognition
Oct 21, 2019
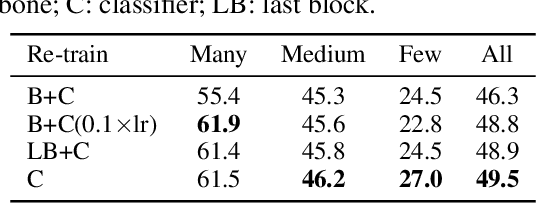

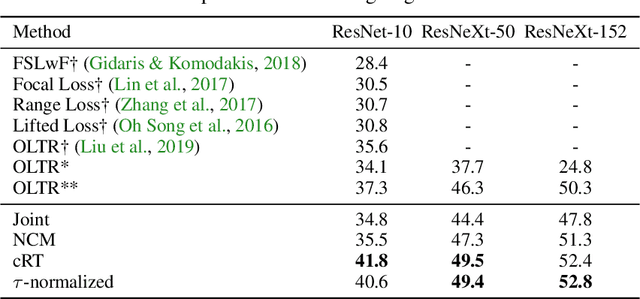
The long-tail distribution of the visual world poses great challenges for deep learning based classification models on how to handle the class imbalance problem. Existing solutions usually involve class-balancing strategies, e.g., by loss re-weighting, data re-sampling, or transfer learning from head- to tail-classes, but most of them adhere to the scheme of jointly learning representations and classifiers. In this work, we decouple the learning procedure into representation learning and classification, and systematically explore how different balancing strategies affect them for long-tailed recognition. The findings are surprising: (1) data imbalance might not be an issue in learning high-quality representations; (2) with representations learned with the simplest instance-balanced (natural) sampling, it is also possible to achieve strong long-tailed recognition ability at little cost by adjusting only the classifier. We conduct extensive experiments and set new state-of-the-art performance on common long-tailed benchmarks like ImageNet-LT, Places-LT and iNaturalist, showing that it is possible to outperform carefully designed losses, sampling strategies, even complex modules with memory, by using a straightforward approach that decouples representation and classification.
Rosetta: Large scale system for text detection and recognition in images
Oct 11, 2019
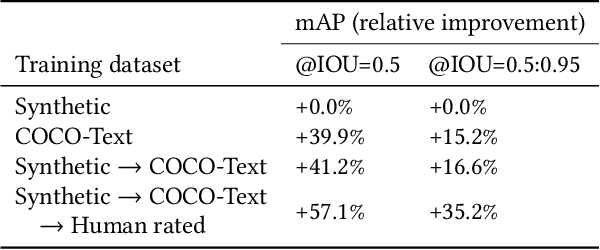
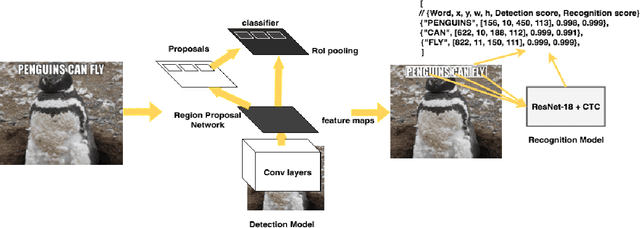

In this paper we present a deployed, scalable optical character recognition (OCR) system, which we call Rosetta, designed to process images uploaded daily at Facebook scale. Sharing of image content has become one of the primary ways to communicate information among internet users within social networks such as Facebook and Instagram, and the understanding of such media, including its textual information, is of paramount importance to facilitate search and recommendation applications. We present modeling techniques for efficient detection and recognition of text in images and describe Rosetta's system architecture. We perform extensive evaluation of presented technologies, explain useful practical approaches to build an OCR system at scale, and provide insightful intuitions as to why and how certain components work based on the lessons learnt during the development and deployment of the system.