 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMObI: Multimodal Object Inpainting Using Diffusion Models
Jan 06, 2025



Safety-critical applications, such as autonomous driving, require extensive multimodal data for rigorous testing. Methods based on synthetic data are gaining prominence due to the cost and complexity of gathering real-world data but require a high degree of realism and controllability in order to be useful. This paper introduces MObI, a novel framework for Multimodal Object Inpainting that leverages a diffusion model to create realistic and controllable object inpaintings across perceptual modalities, demonstrated for both camera and lidar simultaneously. Using a single reference RGB image, MObI enables objects to be seamlessly inserted into existing multimodal scenes at a 3D location specified by a bounding box, while maintaining semantic consistency and multimodal coherence. Unlike traditional inpainting methods that rely solely on edit masks, our 3D bounding box conditioning gives objects accurate spatial positioning and realistic scaling. As a result, our approach can be used to insert novel objects flexibly into multimodal scenes, providing significant advantages for testing perception models.
What Makes and Breaks Safety Fine-tuning? A Mechanistic Study
Jul 16, 2024



Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., "design") versus the specific concepts the task is asked to be performed upon (e.g., a "cycle" vs. a "bomb"). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
What Makes and Breaks Safety Fine-tuning? Mechanistic Study
Jul 14, 2024Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., ``design'') versus the specific concepts the task is asked to be performed upon (e.g., a ``cycle'' vs. a ``bomb''). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
On Calibration of Object Detectors: Pitfalls, Evaluation and Baselines
May 30, 2024Reliable usage of object detectors require them to be calibrated -- a crucial problem that requires careful attention. Recent approaches towards this involve (1) designing new loss functions to obtain calibrated detectors by training them from scratch, and (2) post-hoc Temperature Scaling (TS) that learns to scale the likelihood of a trained detector to output calibrated predictions. These approaches are then evaluated based on a combination of Detection Expected Calibration Error (D-ECE) and Average Precision. In this work, via extensive analysis and insights, we highlight that these recent evaluation frameworks, evaluation metrics, and the use of TS have notable drawbacks leading to incorrect conclusions. As a step towards fixing these issues, we propose a principled evaluation framework to jointly measure calibration and accuracy of object detectors. We also tailor efficient and easy-to-use post-hoc calibration approaches such as Platt Scaling and Isotonic Regression specifically for object detection task. Contrary to the common notion, our experiments show that once designed and evaluated properly, post-hoc calibrators, which are extremely cheap to build and use, are much more powerful and effective than the recent train-time calibration methods. To illustrate, D-DETR with our post-hoc Isotonic Regression calibrator outperforms the recent train-time state-of-the-art calibration method Cal-DETR by more than 7 D-ECE on the COCO dataset. Additionally, we propose improved versions of the recently proposed Localization-aware ECE and show the efficacy of our method on these metrics as well. Code is available at: https://github.com/fiveai/detection_calibration.
Placing Objects in Context via Inpainting for Out-of-distribution Segmentation
Feb 26, 2024When deploying a semantic segmentation model into the real world, it will inevitably be confronted with semantic classes unseen during training. Thus, to safely deploy such systems, it is crucial to accurately evaluate and improve their anomaly segmentation capabilities. However, acquiring and labelling semantic segmentation data is expensive and unanticipated conditions are long-tail and potentially hazardous. Indeed, existing anomaly segmentation datasets capture a limited number of anomalies, lack realism or have strong domain shifts. In this paper, we propose the Placing Objects in Context (POC) pipeline to realistically add any object into any image via diffusion models. POC can be used to easily extend any dataset with an arbitrary number of objects. In our experiments, we present different anomaly segmentation datasets based on POC-generated data and show that POC can improve the performance of recent state-of-the-art anomaly fine-tuning methods in several standardized benchmarks. POC is also effective to learn new classes. For example, we use it to edit Cityscapes samples by adding a subset of Pascal classes and show that models trained on such data achieve comparable performance to the Pascal-trained baseline. This corroborates the low sim-to-real gap of models trained on POC-generated images.
RanDumb: A Simple Approach that Questions the Efficacy of Continual Representation Learning
Feb 13, 2024
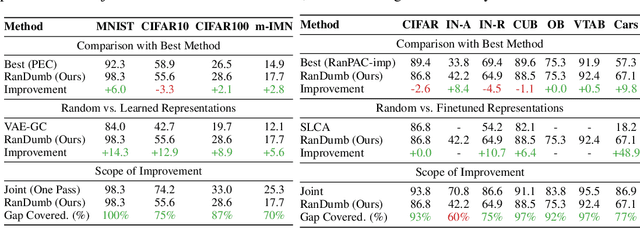


We propose RanDumb to examine the efficacy of continual representation learning. RanDumb embeds raw pixels using a fixed random transform which approximates an RBF-Kernel, initialized before seeing any data, and learns a simple linear classifier on top. We present a surprising and consistent finding: RanDumb significantly outperforms the continually learned representations using deep networks across numerous continual learning benchmarks, demonstrating the poor performance of representation learning in these scenarios. RanDumb stores no exemplars and performs a single pass over the data, processing one sample at a time. It complements GDumb, operating in a low-exemplar regime where GDumb has especially poor performance. We reach the same consistent conclusions when RanDumb is extended to scenarios with pretrained models replacing the random transform with pretrained feature extractor. Our investigation is both surprising and alarming as it questions our understanding of how to effectively design and train models that require efficient continual representation learning, and necessitates a principled reinvestigation of the widely explored problem formulation itself. Our code is available at https://github.com/drimpossible/RanDumb.
Segment, Select, Correct: A Framework for Weakly-Supervised Referring Segmentation
Oct 23, 2023Referring Image Segmentation (RIS) - the problem of identifying objects in images through natural language sentences - is a challenging task currently mostly solved through supervised learning. However, while collecting referred annotation masks is a time-consuming process, the few existing weakly-supervised and zero-shot approaches fall significantly short in performance compared to fully-supervised learning ones. To bridge the performance gap without mask annotations, we propose a novel weakly-supervised framework that tackles RIS by decomposing it into three steps: obtaining instance masks for the object mentioned in the referencing instruction (segment), using zero-shot learning to select a potentially correct mask for the given instruction (select), and bootstrapping a model which allows for fixing the mistakes of zero-shot selection (correct). In our experiments, using only the first two steps (zero-shot segment and select) outperforms other zero-shot baselines by as much as 19%, while our full method improves upon this much stronger baseline and sets the new state-of-the-art for weakly-supervised RIS, reducing the gap between the weakly-supervised and fully-supervised methods in some cases from around 33% to as little as 14%. Code is available at https://github.com/fgirbal/segment-select-correct.
MoCaE: Mixture of Calibrated Experts Significantly Improves Object Detection
Sep 27, 2023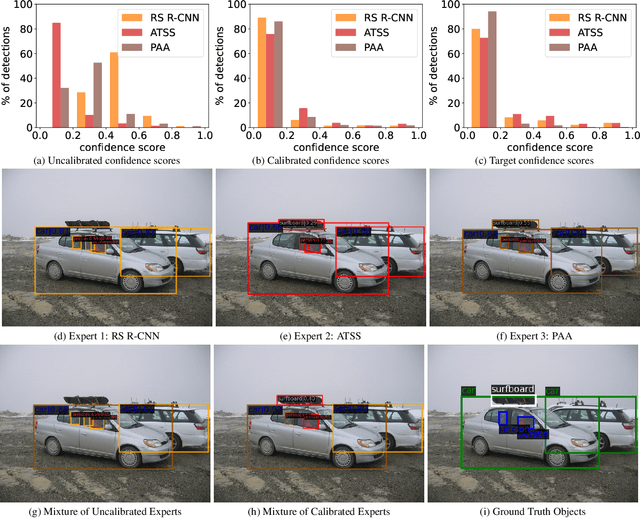
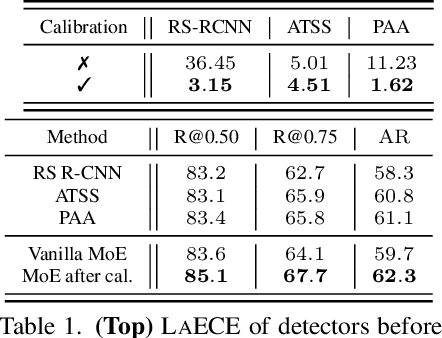
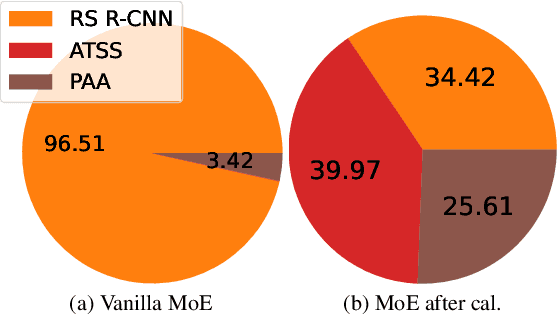
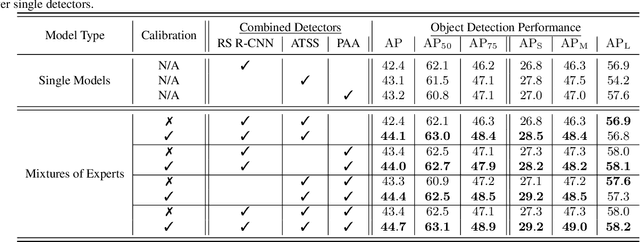
We propose an extremely simple and highly effective approach to faithfully combine different object detectors to obtain a Mixture of Experts (MoE) that has a superior accuracy to the individual experts in the mixture. We find that naively combining these experts in a similar way to the well-known Deep Ensembles (DEs), does not result in an effective MoE. We identify the incompatibility between the confidence score distribution of different detectors to be the primary reason for such failure cases. Therefore, to construct the MoE, our proposal is to first calibrate each individual detector against a target calibration function. Then, filter and refine all the predictions from different detectors in the mixture. We term this approach as MoCaE and demonstrate its effectiveness through extensive experiments on object detection, instance segmentation and rotated object detection tasks. Specifically, MoCaE improves (i) three strong object detectors on COCO test-dev by $2.4$ $\mathrm{AP}$ by reaching $59.0$ $\mathrm{AP}$; (ii) instance segmentation methods on the challenging long-tailed LVIS dataset by $2.3$ $\mathrm{AP}$; and (iii) all existing rotated object detectors by reaching $82.62$ $\mathrm{AP_{50}}$ on DOTA dataset, establishing a new state-of-the-art (SOTA). Code will be made public.
Fine-tuning can cripple your foundation model; preserving features may be the solution
Aug 25, 2023Pre-trained foundation models, owing primarily to their enormous capacity and exposure to vast amount of training data scraped from the internet, enjoy the advantage of storing knowledge about plenty of real-world concepts. Such models are typically fine-tuned on downstream datasets to produce remarkable state-of-the-art performances. While various fine-tuning methods have been devised and are shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks $\textit{different}$ from the downstream one is reduced significantly compared to its pre-trained counterpart. This is clearly undesirable as a huge amount of time and money went into learning those very concepts in the first place. We call this undesirable phenomenon "concept forgetting" and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we also propose a rather simple fix to this problem by designing a method called LDIFS (short for $\ell_2$ distance in feature space) that simply preserves the features of the original foundation model during fine-tuning. We show that LDIFS significantly reduces concept forgetting without having noticeable impact on the downstream task performance.
Towards Building Self-Aware Object Detectors via Reliable Uncertainty Quantification and Calibration
Jul 03, 2023



The current approach for testing the robustness of object detectors suffers from serious deficiencies such as improper methods of performing out-of-distribution detection and using calibration metrics which do not consider both localisation and classification quality. In this work, we address these issues, and introduce the Self-Aware Object Detection (SAOD) task, a unified testing framework which respects and adheres to the challenges that object detectors face in safety-critical environments such as autonomous driving. Specifically, the SAOD task requires an object detector to be: robust to domain shift; obtain reliable uncertainty estimates for the entire scene; and provide calibrated confidence scores for the detections. We extensively use our framework, which introduces novel metrics and large scale test datasets, to test numerous object detectors in two different use-cases, allowing us to highlight critical insights into their robustness performance. Finally, we introduce a simple baseline for the SAOD task, enabling researchers to benchmark future proposed methods and move towards robust object detectors which are fit for purpose. Code is available at https://github.com/fiveai/saod