 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning can cripple your foundation model; preserving features may be the solution
Aug 25, 2023Pre-trained foundation models, owing primarily to their enormous capacity and exposure to vast amount of training data scraped from the internet, enjoy the advantage of storing knowledge about plenty of real-world concepts. Such models are typically fine-tuned on downstream datasets to produce remarkable state-of-the-art performances. While various fine-tuning methods have been devised and are shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks $\textit{different}$ from the downstream one is reduced significantly compared to its pre-trained counterpart. This is clearly undesirable as a huge amount of time and money went into learning those very concepts in the first place. We call this undesirable phenomenon "concept forgetting" and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we also propose a rather simple fix to this problem by designing a method called LDIFS (short for $\ell_2$ distance in feature space) that simply preserves the features of the original foundation model during fine-tuning. We show that LDIFS significantly reduces concept forgetting without having noticeable impact on the downstream task performance.
Open Vocabulary Semantic Segmentation with Patch Aligned Contrastive Learning
Dec 09, 2022We introduce Patch Aligned Contrastive Learning (PACL), a modified compatibility function for CLIP's contrastive loss, intending to train an alignment between the patch tokens of the vision encoder and the CLS token of the text encoder. With such an alignment, a model can identify regions of an image corresponding to a given text input, and therefore transfer seamlessly to the task of open vocabulary semantic segmentation without requiring any segmentation annotations during training. Using pre-trained CLIP encoders with PACL, we are able to set the state-of-the-art on the task of open vocabulary zero-shot segmentation on 4 different segmentation benchmarks: Pascal VOC, Pascal Context, COCO Stuff and ADE20K. Furthermore, we show that PACL is also applicable to image-level predictions and when used with a CLIP backbone, provides a general improvement in zero-shot classification accuracy compared to CLIP, across a suite of 12 image classification datasets.
Raising the Bar on the Evaluation of Out-of-Distribution Detection
Sep 24, 2022


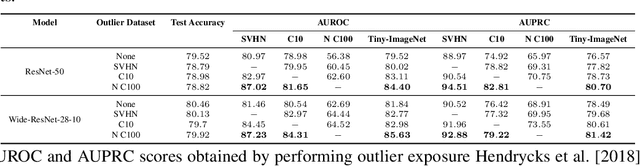
In image classification, a lot of development has happened in detecting out-of-distribution (OoD) data. However, most OoD detection methods are evaluated on a standard set of datasets, arbitrarily different from training data. There is no clear definition of what forms a ``good" OoD dataset. Furthermore, the state-of-the-art OoD detection methods already achieve near perfect results on these standard benchmarks. In this paper, we define 2 categories of OoD data using the subtly different concepts of perceptual/visual and semantic similarity to in-distribution (iD) data. We define Near OoD samples as perceptually similar but semantically different from iD samples, and Shifted samples as points which are visually different but semantically akin to iD data. We then propose a GAN based framework for generating OoD samples from each of these 2 categories, given an iD dataset. Through extensive experiments on MNIST, CIFAR-10/100 and ImageNet, we show that a) state-of-the-art OoD detection methods which perform exceedingly well on conventional benchmarks are significantly less robust to our proposed benchmark. Moreover, b) models performing well on our setup also perform well on conventional real-world OoD detection benchmarks and vice versa, thereby indicating that one might not even need a separate OoD set, to reliably evaluate performance in OoD detection.
Deep Deterministic Uncertainty for Semantic Segmentation
Oct 29, 2021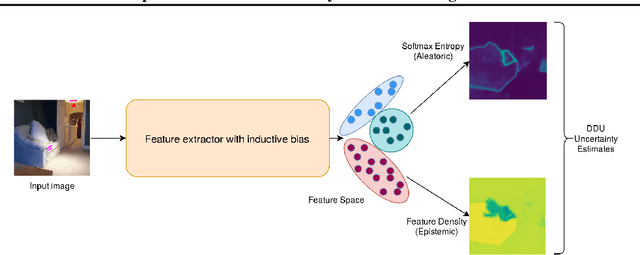
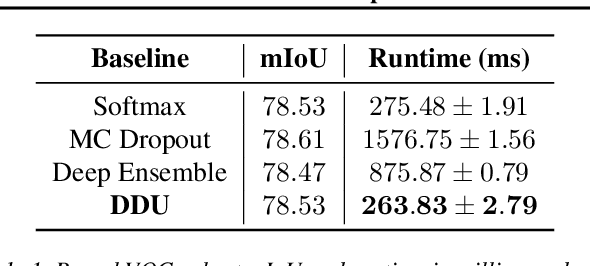
We extend Deep Deterministic Uncertainty (DDU), a method for uncertainty estimation using feature space densities, to semantic segmentation. DDU enables quantifying and disentangling epistemic and aleatoric uncertainty in a single forward pass through the model. We study the similarity of feature representations of pixels at different locations for the same class and conclude that it is feasible to apply DDU location independently, which leads to a significant reduction in memory consumption compared to pixel dependent DDU. Using the DeepLab-v3+ architecture on Pascal VOC 2012, we show that DDU improves upon MC Dropout and Deep Ensembles while being significantly faster to compute.
Deterministic Neural Networks with Appropriate Inductive Biases Capture Epistemic and Aleatoric Uncertainty
Feb 23, 2021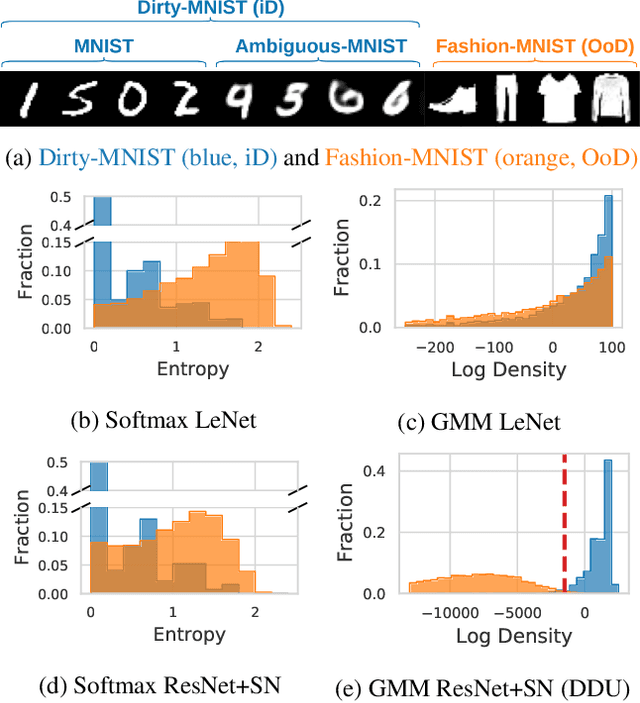

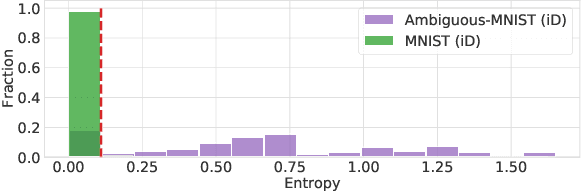
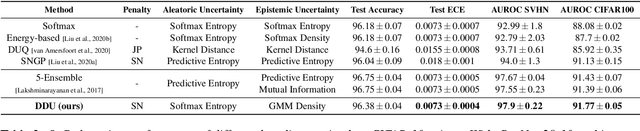
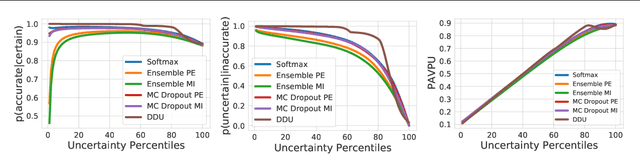
We show that a single softmax neural net with minimal changes can beat the uncertainty predictions of Deep Ensembles and other more complex single-forward-pass uncertainty approaches. Softmax neural nets cannot capture epistemic uncertainty reliably because for OoD points they extrapolate arbitrarily and suffer from feature collapse. This results in arbitrary softmax entropies for OoD points which can have high entropy, low, or anything in between. We study why, and show that with the right inductive biases, softmax neural nets trained with maximum likelihood reliably capture epistemic uncertainty through the feature-space density. This density is obtained using Gaussian Discriminant Analysis, but it cannot disentangle uncertainties. We show that it is necessary to combine this density with the softmax entropy to disentangle aleatoric and epistemic uncertainty -- crucial e.g. for active learning. We examine the quality of epistemic uncertainty on active learning and OoD detection, where we obtain SOTA ~0.98 AUROC on CIFAR-10 vs SVHN.
On Batch Normalisation for Approximate Bayesian Inference
Dec 24, 2020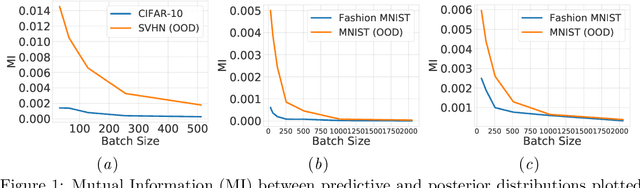
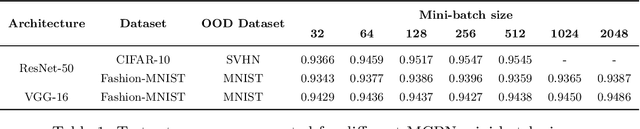
We study batch normalisation in the context of variational inference methods in Bayesian neural networks, such as mean-field or MC Dropout. We show that batch-normalisation does not affect the optimum of the evidence lower bound (ELBO). Furthermore, we study the Monte Carlo Batch Normalisation (MCBN) algorithm, proposed as an approximate inference technique parallel to MC Dropout, and show that for larger batch sizes, MCBN fails to capture epistemic uncertainty. Finally, we provide insights into what is required to fix this failure, namely having to view the mini-batch size as a variational parameter in MCBN. We comment on the asymptotics of the ELBO with respect to this variational parameter, showing that as dataset size increases towards infinity, the batch-size must increase towards infinity as well for MCBN to be a valid approximate inference technique.
Calibrating Deep Neural Networks using Focal Loss
Feb 21, 2020



Miscalibration -- a mismatch between a model's confidence and its correctness -- of Deep Neural Networks (DNNs) makes their predictions hard to rely on. Ideally, we want networks to be accurate, calibrated and confident. We show that, as opposed to the standard cross-entropy loss, focal loss (Lin et al., 2017) allows us to learn models that are already very well calibrated. When combined with temperature scaling, whilst preserving accuracy, it yields state-of-the-art calibrated models. We provide a thorough analysis of the factors causing miscalibration, and use the insights we glean from this to justify the empirically excellent performance of focal loss. To facilitate the use of focal loss in practice, we also provide a principled approach to automatically select the hyperparameter involved in the loss function. We perform extensive experiments on a variety of computer vision and NLP datasets, and with a wide variety of network architectures, and show that our approach achieves state-of-the-art accuracy and calibration in almost all cases.
Let's Take This Online: Adapting Scene Coordinate Regression Network Predictions for Online RGB-D Camera Relocalisation
Jun 20, 2019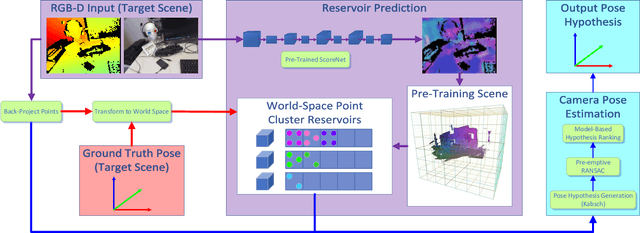
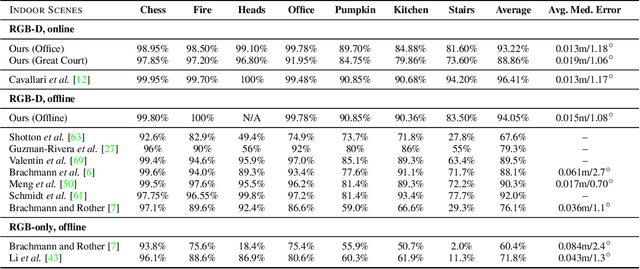
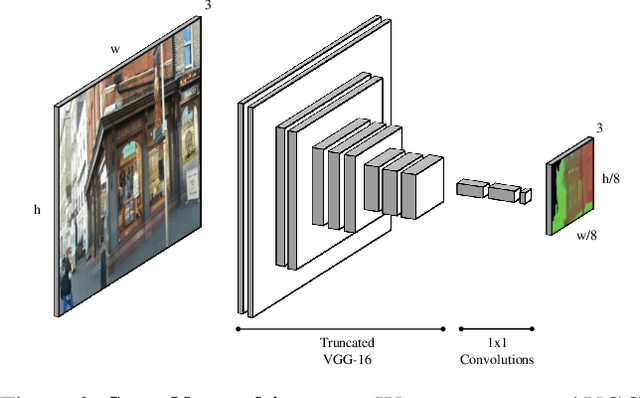
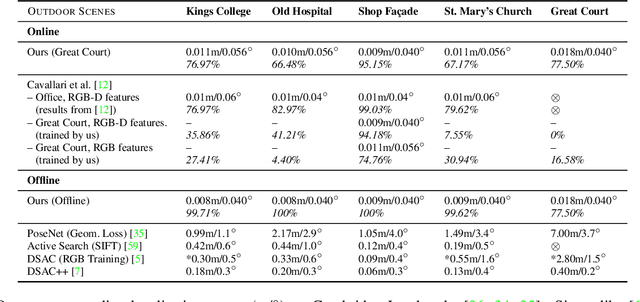
Many applications require a camera to be relocalised online, without expensive offline training on the target scene. Whilst both keyframe and sparse keypoint matching methods can be used online, the former often fail away from the training trajectory, and the latter can struggle in textureless regions. By contrast, scene coordinate regression (SCoRe) methods generalise to novel poses and can leverage dense correspondences to improve robustness, and recent work has shown how to adapt SCoRe forests between scenes, allowing their state-of-the-art performance to be leveraged online. However, because they use features hand-crafted for indoor use, they do not generalise well to harder outdoor scenes. Whilst replacing the forest with a neural network and learning suitable features for outdoor use is possible, the techniques used to adapt forests between scenes are unfortunately harder to transfer to a network context. In this paper, we address this by proposing a novel way of leveraging a network trained on one scene to predict points in another scene. Our approach replaces the appearance clustering performed by the branching structure of a regression forest with a two-step process that first uses the network to predict points in the original scene, and then uses these predicted points to look up clusters of points from the new scene. We show experimentally that our online approach achieves state-of-the-art performance on both the 7-Scenes and Cambridge Landmarks datasets, whilst running in under 300ms, making it highly effective in live scenarios.
On the Importance of Strong Baselines in Bayesian Deep Learning
Nov 30, 2018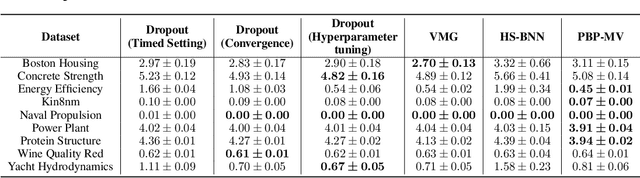
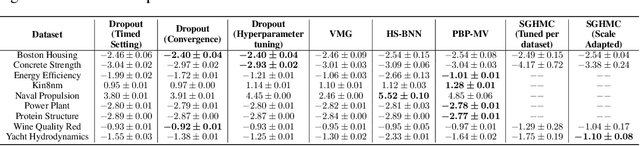
Like all sub-fields of machine learning Bayesian Deep Learning is driven by empirical validation of its theoretical proposals. Given the many aspects of an experiment it is always possible that minor or even major experimental flaws can slip by both authors and reviewers. One of the most popular experiments used to evaluate approximate inference techniques is the regression experiment on UCI datasets. However, in this experiment, models which have been trained to convergence have often been compared with baselines trained only for a fixed number of iterations. We find that a well-established baseline, Monte Carlo dropout, when evaluated under the same experimental settings shows significant improvements. In fact, the baseline outperforms or performs competitively with methods that claimed to be superior to the very same baseline method when they were introduced. Hence, by exposing this flaw in experimental procedure, we highlight the importance of using identical experimental setups to evaluate, compare, and benchmark methods in Bayesian Deep Learning.
Evaluating Bayesian Deep Learning Methods for Semantic Segmentation
Nov 30, 2018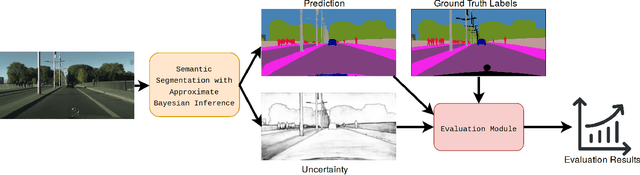
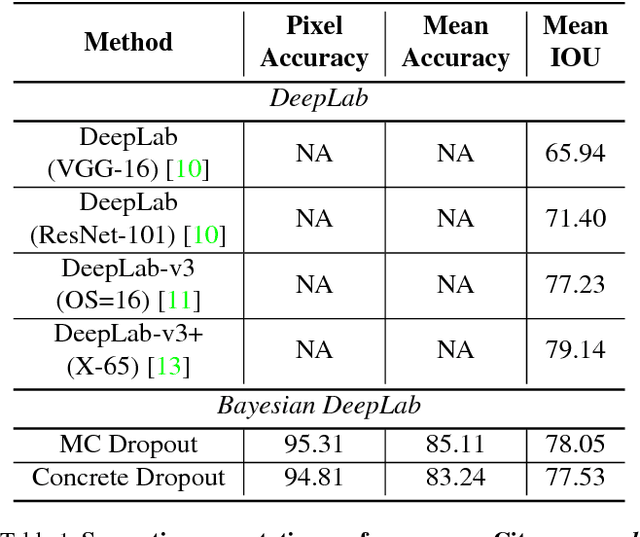
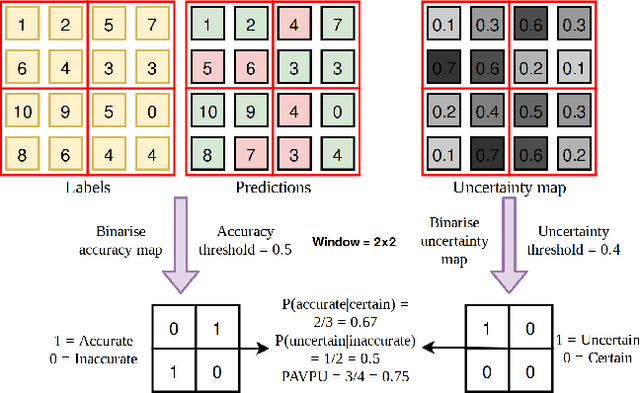
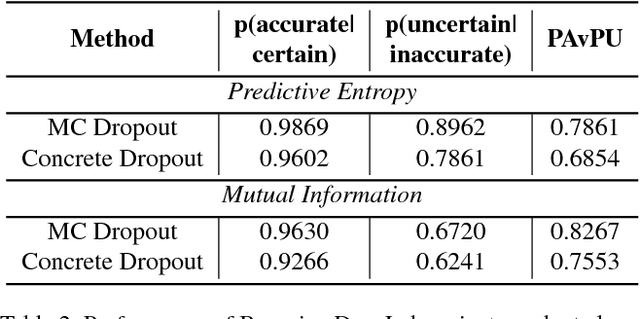
Deep learning has been revolutionary for computer vision and semantic segmentation in particular, with Bayesian Deep Learning (BDL) used to obtain uncertainty maps from deep models when predicting semantic classes. This information is critical when using semantic segmentation for autonomous driving for example. Standard semantic segmentation systems have well-established evaluation metrics. However, with BDL's rising popularity in computer vision we require new metrics to evaluate whether a BDL method produces better uncertainty estimates than another method. In this work we propose three such metrics to evaluate BDL models designed specifically for the task of semantic segmentation. We modify DeepLab-v3+, one of the state-of-the-art deep neural networks, and create its Bayesian counterpart using MC dropout and Concrete dropout as inference techniques. We then compare and test these two inference techniques on the well-known Cityscapes dataset using our suggested metrics. Our results provide new benchmarks for researchers to compare and evaluate their improved uncertainty quantification in pursuit of safer semantic segmentation.