 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenMM: Geometrically and Temporally Consistent Multimodal Data Generation for Video and LiDAR
Jun 15, 2024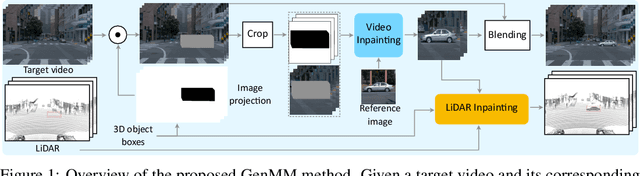
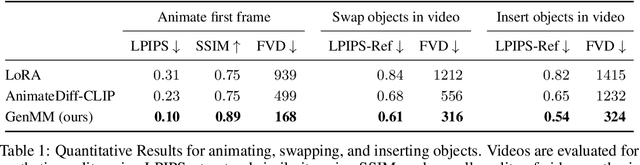
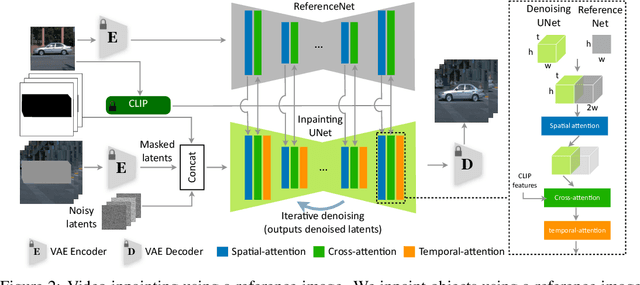

Multimodal synthetic data generation is crucial in domains such as autonomous driving, robotics, augmented/virtual reality, and retail. We propose a novel approach, GenMM, for jointly editing RGB videos and LiDAR scans by inserting temporally and geometrically consistent 3D objects. Our method uses a reference image and 3D bounding boxes to seamlessly insert and blend new objects into target videos. We inpaint the 2D Regions of Interest (consistent with 3D boxes) using a diffusion-based video inpainting model. We then compute semantic boundaries of the object and estimate it's surface depth using state-of-the-art semantic segmentation and monocular depth estimation techniques. Subsequently, we employ a geometry-based optimization algorithm to recover the 3D shape of the object's surface, ensuring it fits precisely within the 3D bounding box. Finally, LiDAR rays intersecting with the new object surface are updated to reflect consistent depths with its geometry. Our experiments demonstrate the effectiveness of GenMM in inserting various 3D objects across video and LiDAR modalities.
A Revised Generative Evaluation of Visual Dialogue
Apr 24, 2020
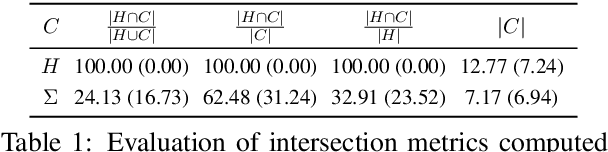
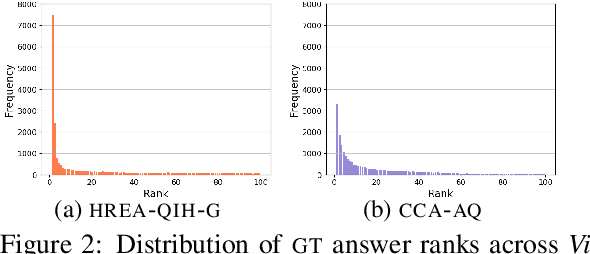
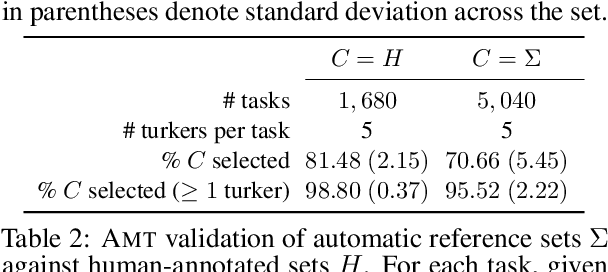
Evaluating Visual Dialogue, the task of answering a sequence of questions relating to a visual input, remains an open research challenge. The current evaluation scheme of the VisDial dataset computes the ranks of ground-truth answers in predefined candidate sets, which Massiceti et al. (2018) show can be susceptible to the exploitation of dataset biases. This scheme also does little to account for the different ways of expressing the same answer--an aspect of language that has been well studied in NLP. We propose a revised evaluation scheme for the VisDial dataset leveraging metrics from the NLP literature to measure consensus between answers generated by the model and a set of relevant answers. We construct these relevant answer sets using a simple and effective semi-supervised method based on correlation, which allows us to automatically extend and scale sparse relevance annotations from humans to the entire dataset. We release these sets and code for the revised evaluation scheme as DenseVisDial, and intend them to be an improvement to the dataset in the face of its existing constraints and design choices.
Calibrating Deep Neural Networks using Focal Loss
Feb 21, 2020



Miscalibration -- a mismatch between a model's confidence and its correctness -- of Deep Neural Networks (DNNs) makes their predictions hard to rely on. Ideally, we want networks to be accurate, calibrated and confident. We show that, as opposed to the standard cross-entropy loss, focal loss (Lin et al., 2017) allows us to learn models that are already very well calibrated. When combined with temperature scaling, whilst preserving accuracy, it yields state-of-the-art calibrated models. We provide a thorough analysis of the factors causing miscalibration, and use the insights we glean from this to justify the empirically excellent performance of focal loss. To facilitate the use of focal loss in practice, we also provide a principled approach to automatically select the hyperparameter involved in the loss function. We perform extensive experiments on a variety of computer vision and NLP datasets, and with a wide variety of network architectures, and show that our approach achieves state-of-the-art accuracy and calibration in almost all cases.
Domain Partitioning Network
Feb 21, 2019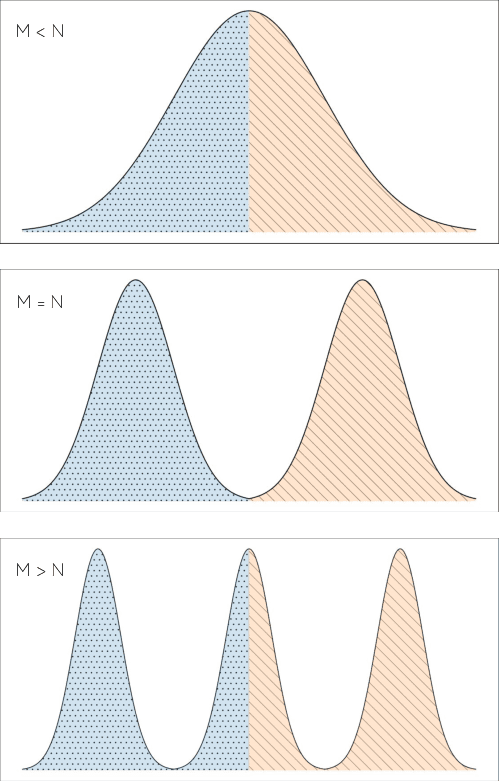
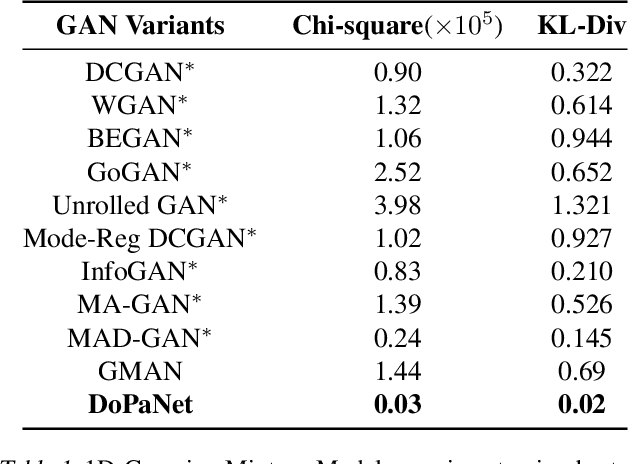
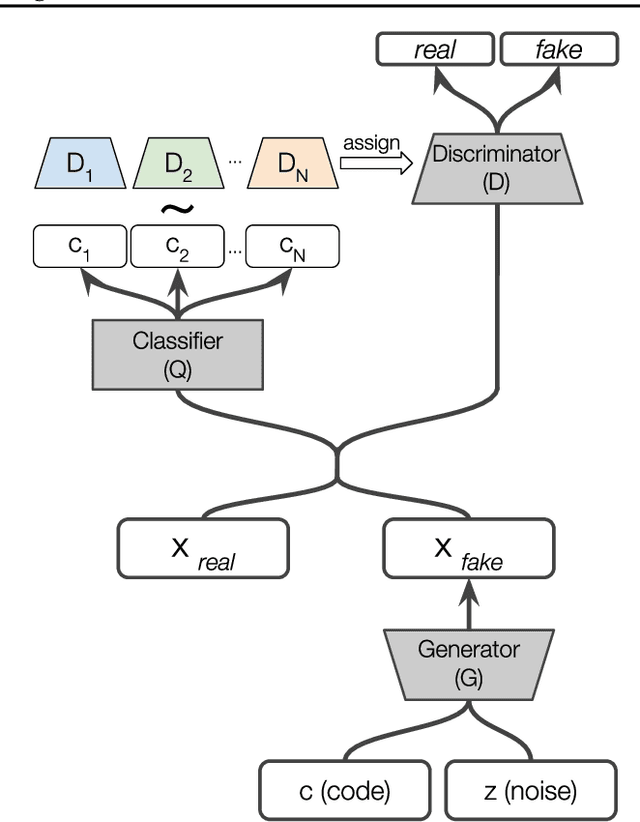

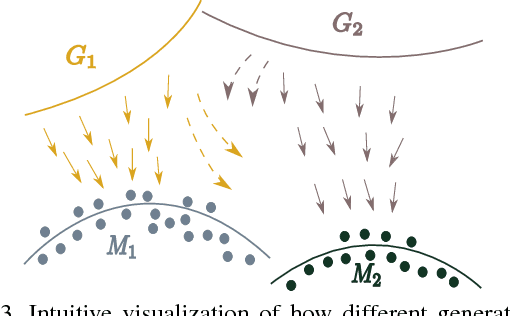
Standard adversarial training involves two agents, namely a generator and a discriminator, playing a mini-max game. However, even if the players converge to an equilibrium, the generator may only recover a part of the target data distribution, in a situation commonly referred to as mode collapse. In this work, we present the Domain Partitioning Network (DoPaNet), a new approach to deal with mode collapse in generative adversarial learning. We employ multiple discriminators, each encouraging the generator to cover a different part of the target distribution. To ensure these parts do not overlap and collapse into the same mode, we add a classifier as a third agent in the game. The classifier decides which discriminator the generator is trained against for each sample. Through experiments on toy examples and real images, we show the merits of DoPaNet in covering the real distribution and its superiority with respect to the competing methods. Besides, we also show that we can control the modes from which samples are generated using DoPaNet.
Multi-Agent Diverse Generative Adversarial Networks
Jul 16, 2018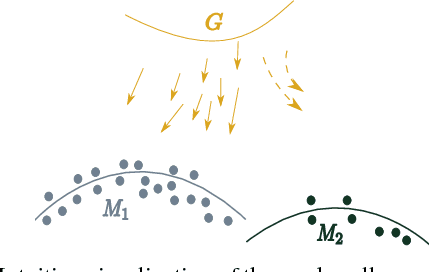
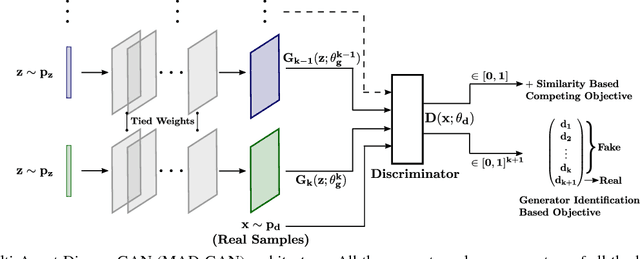

We propose MAD-GAN, an intuitive generalization to the Generative Adversarial Networks (GANs) and its conditional variants to address the well known problem of mode collapse. First, MAD-GAN is a multi-agent GAN architecture incorporating multiple generators and one discriminator. Second, to enforce that different generators capture diverse high probability modes, the discriminator of MAD-GAN is designed such that along with finding the real and fake samples, it is also required to identify the generator that generated the given fake sample. Intuitively, to succeed in this task, the discriminator must learn to push different generators towards different identifiable modes. We perform extensive experiments on synthetic and real datasets and compare MAD-GAN with different variants of GAN. We show high quality diverse sample generations for challenging tasks such as image-to-image translation and face generation. In addition, we also show that MAD-GAN is able to disentangle different modalities when trained using highly challenging diverse-class dataset (e.g. dataset with images of forests, icebergs, and bedrooms). In the end, we show its efficacy on the unsupervised feature representation task. In Appendix, we introduce a similarity based competing objective (MAD-GAN-Sim) which encourages different generators to generate diverse samples based on a user defined similarity metric. We show its performance on the image-to-image translation, and also show its effectiveness on the unsupervised feature representation task.
Contextual RNN-GANs for Abstract Reasoning Diagram Generation
Dec 06, 2016
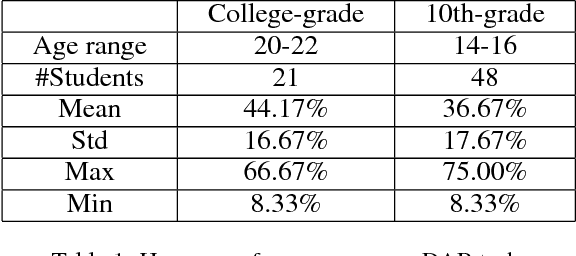
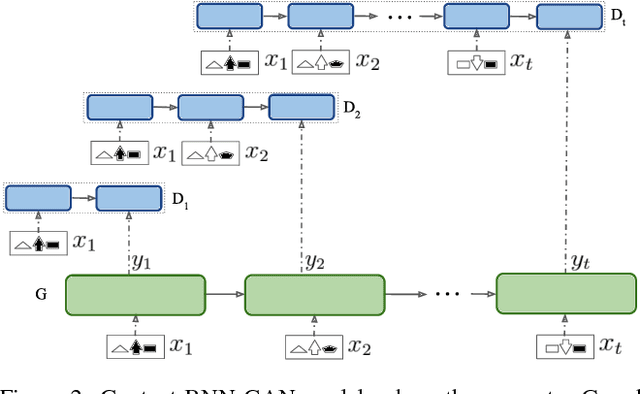
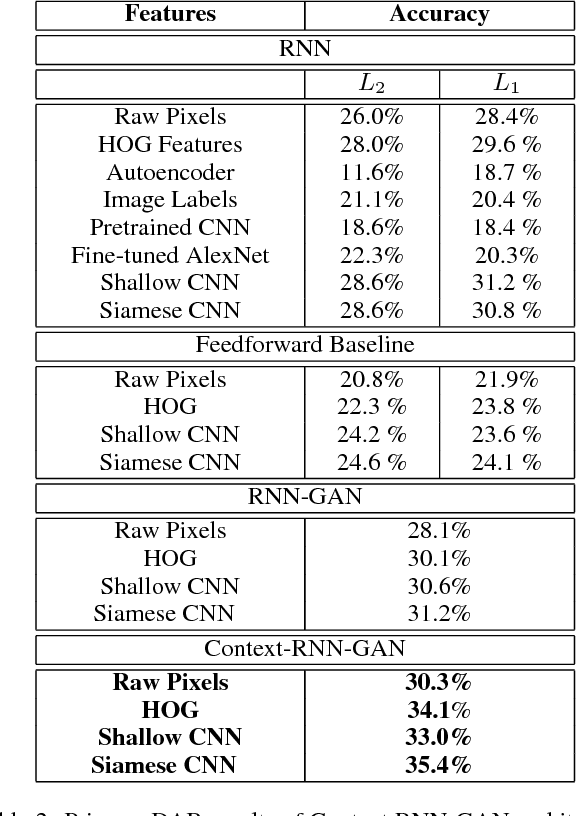
Understanding, predicting, and generating object motions and transformations is a core problem in artificial intelligence. Modeling sequences of evolving images may provide better representations and models of motion and may ultimately be used for forecasting, simulation, or video generation. Diagrammatic Abstract Reasoning is an avenue in which diagrams evolve in complex patterns and one needs to infer the underlying pattern sequence and generate the next image in the sequence. For this, we develop a novel Contextual Generative Adversarial Network based on Recurrent Neural Networks (Context-RNN-GANs), where both the generator and the discriminator modules are based on contextual history (modeled as RNNs) and the adversarial discriminator guides the generator to produce realistic images for the particular time step in the image sequence. We evaluate the Context-RNN-GAN model (and its variants) on a novel dataset of Diagrammatic Abstract Reasoning, where it performs competitively with 10th-grade human performance but there is still scope for interesting improvements as compared to college-grade human performance. We also evaluate our model on a standard video next-frame prediction task, achieving improved performance over comparable state-of-the-art.
Message Passing Multi-Agent GANs
Dec 05, 2016
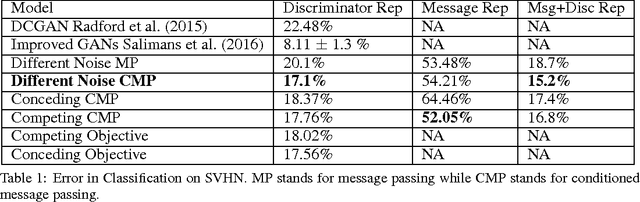


Communicating and sharing intelligence among agents is an important facet of achieving Artificial General Intelligence. As a first step towards this challenge, we introduce a novel framework for image generation: Message Passing Multi-Agent Generative Adversarial Networks (MPM GANs). While GANs have recently been shown to be very effective for image generation and other tasks, these networks have been limited to mostly single generator-discriminator networks. We show that we can obtain multi-agent GANs that communicate through message passing to achieve better image generation. The objectives of the individual agents in this framework are two fold: a co-operation objective and a competing objective. The co-operation objective ensures that the message sharing mechanism guides the other generator to generate better than itself while the competing objective encourages each generator to generate better than its counterpart. We analyze and visualize the messages that these GANs share among themselves in various scenarios. We quantitatively show that the message sharing formulation serves as a regularizer for the adversarial training. Qualitatively, we show that the different generators capture different traits of the underlying data distribution.