 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Information Storage and Transfer in Multi-modal Large Language Models
Jun 06, 2024Understanding the mechanisms of information storage and transfer in Transformer-based models is important for driving model understanding progress. Recent work has studied these mechanisms for Large Language Models (LLMs), revealing insights on how information is stored in a model's parameters and how information flows to and from these parameters in response to specific prompts. However, these studies have not yet been extended to Multi-modal Large Language Models (MLLMs). Given their expanding capabilities and real-world use, we start by studying one aspect of these models -- how MLLMs process information in a factual visual question answering task. We use a constraint-based formulation which views a visual question as having a set of visual or textual constraints that the model's generated answer must satisfy to be correct (e.g. What movie directed by the director in this photo has won a Golden Globe?). Under this setting, we contribute i) a method that extends causal information tracing from pure language to the multi-modal setting, and ii) VQA-Constraints, a test-bed of 9.7K visual questions annotated with constraints. We use these tools to study two open-source MLLMs, LLaVa and multi-modal Phi-2. Our key findings show that these MLLMs rely on MLP and self-attention blocks in much earlier layers for information storage, compared to LLMs whose mid-layer MLPs are more important. We also show that a consistent small subset of visual tokens output by the vision encoder are responsible for transferring information from the image to these causal blocks. We validate these mechanisms by introducing MultEdit, a model-editing algorithm that can correct errors and insert new long-tailed information into MLLMs by targeting these causal blocks.
Explaining CLIP's performance disparities on data from blind/low vision users
Dec 01, 2023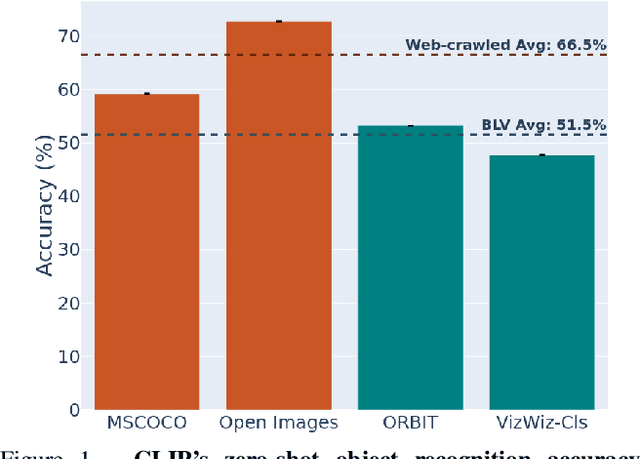
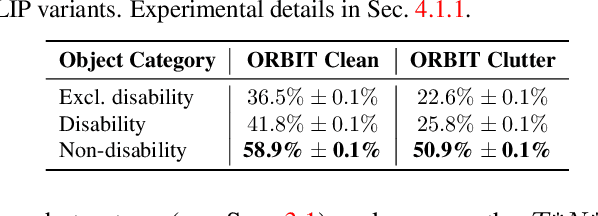
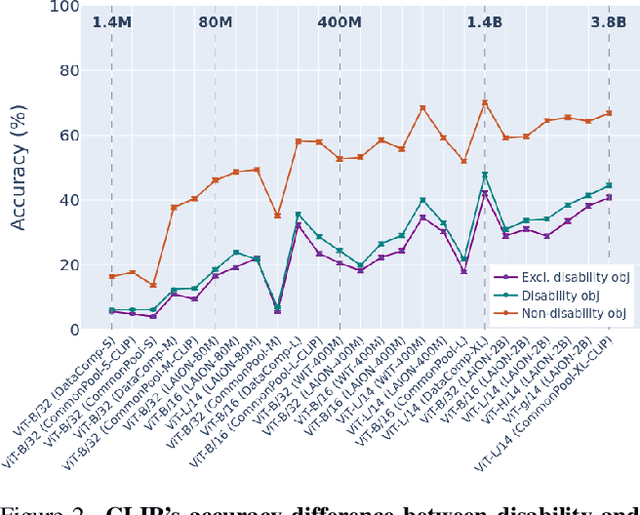
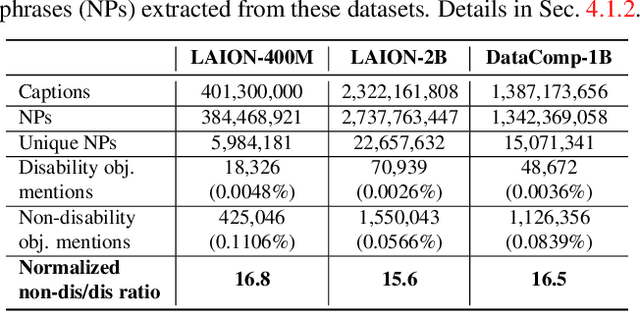
Large multi-modal models (LMMs) hold the potential to usher in a new era of automated visual assistance for people who are blind or low vision (BLV). Yet, these models have not been systematically evaluated on data captured by BLV users. We address this by empirically assessing CLIP, a widely-used LMM likely to underpin many assistive technologies. Testing 25 CLIP variants in a zero-shot classification task, we find that their accuracy is 15 percentage points lower on average for images captured by BLV users than web-crawled images. This disparity stems from CLIP's sensitivities to 1) image content (e.g. not recognizing disability objects as well as other objects); 2) image quality (e.g. not being robust to lighting variation); and 3) text content (e.g. not recognizing objects described by tactile adjectives as well as visual ones). We delve deeper with a textual analysis of three common pre-training datasets: LAION-400M, LAION-2B and DataComp-1B, showing that disability content is rarely mentioned. We then provide three examples that illustrate how the performance disparities extend to three downstream models underpinned by CLIP: OWL-ViT, CLIPSeg and DALL-E2. We find that few-shot learning with as few as 5 images can mitigate CLIP's quality-of-service disparities for BLV users in some scenarios, which we discuss alongside a set of other possible mitigations.
EditVal: Benchmarking Diffusion Based Text-Guided Image Editing Methods
Oct 03, 2023
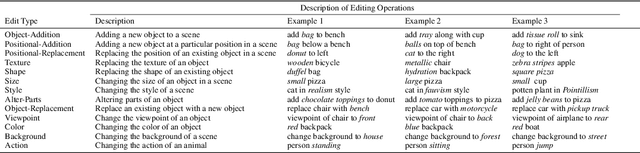
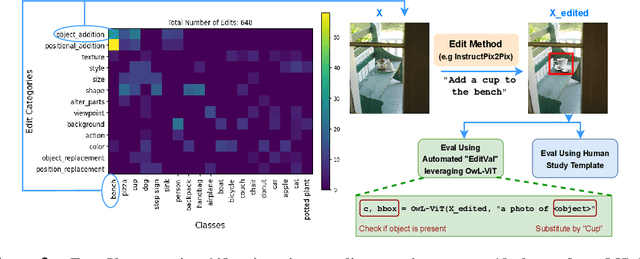
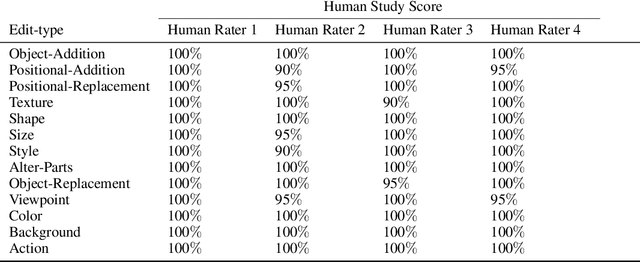
A plethora of text-guided image editing methods have recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models such as Imagen and Stable Diffusion. A standardized evaluation protocol, however, does not exist to compare methods across different types of fine-grained edits. To address this gap, we introduce EditVal, a standardized benchmark for quantitatively evaluating text-guided image editing methods. EditVal consists of a curated dataset of images, a set of editable attributes for each image drawn from 13 possible edit types, and an automated evaluation pipeline that uses pre-trained vision-language models to assess the fidelity of generated images for each edit type. We use EditVal to benchmark 8 cutting-edge diffusion-based editing methods including SINE, Imagic and Instruct-Pix2Pix. We complement this with a large-scale human study where we show that EditVall's automated evaluation pipeline is strongly correlated with human-preferences for the edit types we considered. From both the human study and automated evaluation, we find that: (i) Instruct-Pix2Pix, Null-Text and SINE are the top-performing methods averaged across different edit types, however {\it only} Instruct-Pix2Pix and Null-Text are able to preserve original image properties; (ii) Most of the editing methods fail at edits involving spatial operations (e.g., changing the position of an object). (iii) There is no `winner' method which ranks the best individually across a range of different edit types. We hope that our benchmark can pave the way to developing more reliable text-guided image editing tools in the future. We will publicly release EditVal, and all associated code and human-study templates to support these research directions in https://deep-ml-research.github.io/editval/.
NP-SemiSeg: When Neural Processes meet Semi-Supervised Semantic Segmentation
Aug 05, 2023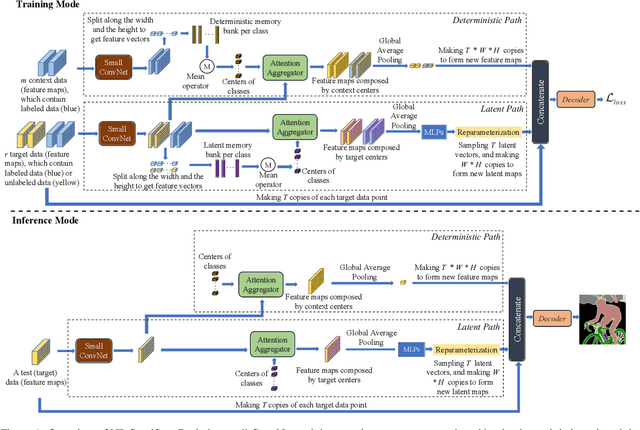



Semi-supervised semantic segmentation involves assigning pixel-wise labels to unlabeled images at training time. This is useful in a wide range of real-world applications where collecting pixel-wise labels is not feasible in time or cost. Current approaches to semi-supervised semantic segmentation work by predicting pseudo-labels for each pixel from a class-wise probability distribution output by a model. If the predicted probability distribution is incorrect, however, this leads to poor segmentation results, which can have knock-on consequences in safety critical systems, like medical images or self-driving cars. It is, therefore, important to understand what a model does not know, which is mainly achieved by uncertainty quantification. Recently, neural processes (NPs) have been explored in semi-supervised image classification, and they have been a computationally efficient and effective method for uncertainty quantification. In this work, we move one step forward by adapting NPs to semi-supervised semantic segmentation, resulting in a new model called NP-SemiSeg. We experimentally evaluated NP-SemiSeg on the public benchmarks PASCAL VOC 2012 and Cityscapes, with different training settings, and the results verify its effectiveness.
Augmenting CLIP with Improved Visio-Linguistic Reasoning
Jul 27, 2023Image-text contrastive models such as CLIP are useful for a variety of downstream applications including zero-shot classification, image-text retrieval and transfer learning. However, these contrastively trained vision-language models often fail on compositional visio-linguistic tasks such as Winoground with performance equivalent to random chance. In our paper, we address this issue and propose a sample-efficient light-weight method called SDS-CLIP to improve the compositional visio-linguistic reasoning capabilities of CLIP. The core idea of our method is to use differentiable image parameterizations to fine-tune CLIP with a distillation objective from large text-to-image generative models such as Stable-Diffusion which are relatively good at visio-linguistic reasoning tasks. On the challenging Winoground compositional reasoning benchmark, our method improves the absolute visio-linguistic performance of different CLIP models by up to 7%, while on the ARO dataset, our method improves the visio-linguistic performance by upto 3%. As a byproduct of inducing visio-linguistic reasoning into CLIP, we also find that the zero-shot performance improves marginally on a variety of downstream datasets. Our method reinforces that carefully designed distillation objectives from generative models can be leveraged to extend existing contrastive image-text models with improved visio-linguistic reasoning capabilities.
Strong Baselines for Parameter Efficient Few-Shot Fine-tuning
Apr 04, 2023Few-shot classification (FSC) entails learning novel classes given only a few examples per class after a pre-training (or meta-training) phase on a set of base classes. Recent works have shown that simply fine-tuning a pre-trained Vision Transformer (ViT) on new test classes is a strong approach for FSC. Fine-tuning ViTs, however, is expensive in time, compute and storage. This has motivated the design of parameter efficient fine-tuning (PEFT) methods which fine-tune only a fraction of the Transformer's parameters. While these methods have shown promise, inconsistencies in experimental conditions make it difficult to disentangle their advantage from other experimental factors including the feature extractor architecture, pre-trained initialization and fine-tuning algorithm, amongst others. In our paper, we conduct a large-scale, experimentally consistent, empirical analysis to study PEFTs for few-shot image classification. Through a battery of over 1.8k controlled experiments on large-scale few-shot benchmarks including Meta-Dataset (MD) and ORBIT, we uncover novel insights on PEFTs that cast light on their efficacy in fine-tuning ViTs for few-shot classification. Through our controlled empirical study, we have two main findings: (i) Fine-tuning just the LayerNorm parameters (which we call LN-Tune) during few-shot adaptation is an extremely strong baseline across ViTs pre-trained with both self-supervised and supervised objectives, (ii) For self-supervised ViTs, we find that simply learning a set of scaling parameters for each attention matrix (which we call AttnScale) along with a domain-residual adapter (DRA) module leads to state-of-the-art performance (while being $\sim\!$ 9$\times$ more parameter-efficient) on MD. Our extensive empirical findings set strong baselines and call for rethinking the current design of PEFT methods for FSC.
NP-Match: When Neural Processes meet Semi-Supervised Learning
Jul 03, 2022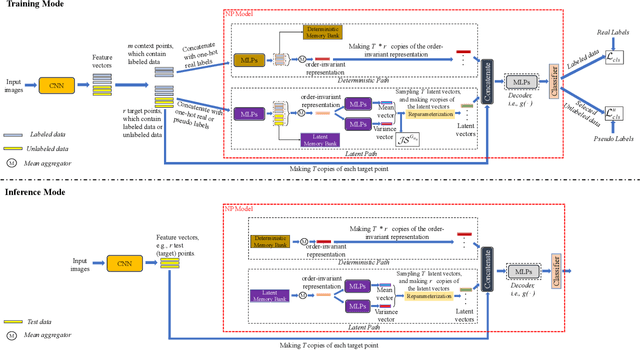
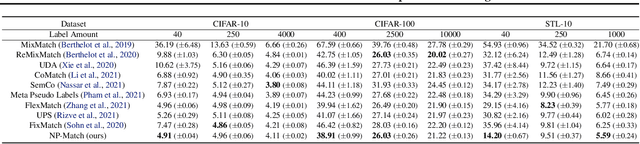
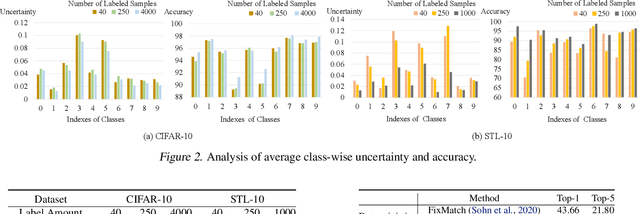
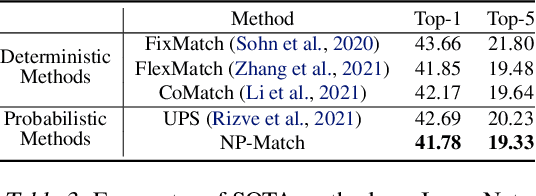
Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on four public datasets, and NP-Match outperforms state-of-the-art (SOTA) results or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL.
Memory Efficient Meta-Learning with Large Images
Jul 02, 2021
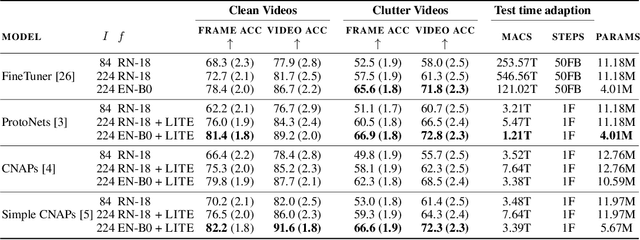
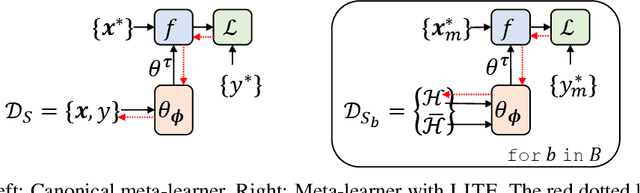
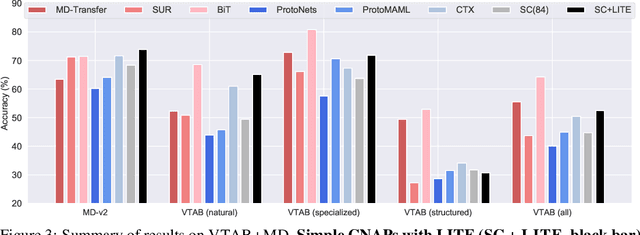
Meta learning approaches to few-shot classification are computationally efficient at test time requiring just a few optimization steps or single forward pass to learn a new task, but they remain highly memory-intensive to train. This limitation arises because a task's entire support set, which can contain up to 1000 images, must be processed before an optimization step can be taken. Harnessing the performance gains offered by large images thus requires either parallelizing the meta-learner across multiple GPUs, which may not be available, or trade-offs between task and image size when memory constraints apply. We improve on both options by proposing LITE, a general and memory efficient episodic training scheme that enables meta-training on large tasks composed of large images on a single GPU. We achieve this by observing that the gradients for a task can be decomposed into a sum of gradients over the task's training images. This enables us to perform a forward pass on a task's entire training set but realize significant memory savings by back-propagating only a random subset of these images which we show is an unbiased approximation of the full gradient. We use LITE to train meta-learners and demonstrate new state-of-the-art accuracy on the real-world ORBIT benchmark and 3 of the 4 parts of the challenging VTAB+MD benchmark relative to leading meta-learners. LITE also enables meta-learners to be competitive with transfer learning approaches but at a fraction of the test-time computational cost, thus serving as a counterpoint to the recent narrative that transfer learning is all you need for few-shot classification.
ORBIT: A Real-World Few-Shot Dataset for Teachable Object Recognition
Apr 09, 2021
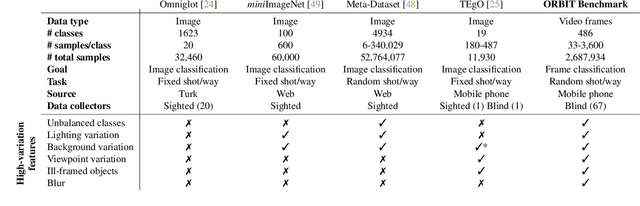
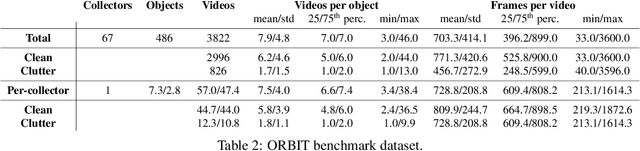
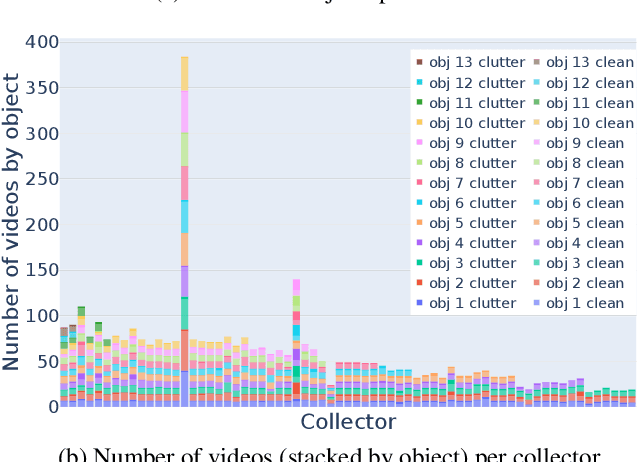
Object recognition has made great advances in the last decade, but predominately still relies on many high-quality training examples per object category. In contrast, learning new objects from only a few examples could enable many impactful applications from robotics to user personalization. Most few-shot learning research, however, has been driven by benchmark datasets that lack the high variation that these applications will face when deployed in the real-world. To close this gap, we present the ORBIT dataset and benchmark, grounded in a real-world application of teachable object recognizers for people who are blind/low vision. The dataset contains 3,822 videos of 486 objects recorded by people who are blind/low-vision on their mobile phones, and the benchmark reflects a realistic, highly challenging recognition problem, providing a rich playground to drive research in robustness to few-shot, high-variation conditions. We set the first state-of-the-art on the benchmark and show that there is massive scope for further innovation, holding the potential to impact a broad range of real-world vision applications including tools for the blind/low-vision community. The dataset is available at https://bit.ly/2OyElCj and the code to run the benchmark at https://bit.ly/39YgiUW.
A Revised Generative Evaluation of Visual Dialogue
Apr 24, 2020
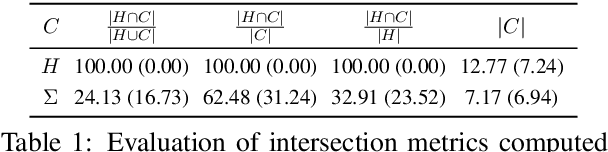
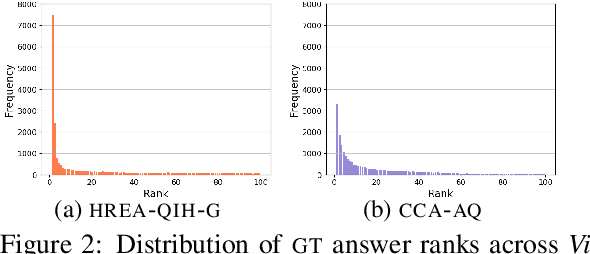
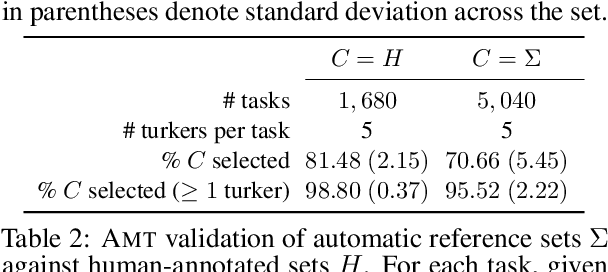
Evaluating Visual Dialogue, the task of answering a sequence of questions relating to a visual input, remains an open research challenge. The current evaluation scheme of the VisDial dataset computes the ranks of ground-truth answers in predefined candidate sets, which Massiceti et al. (2018) show can be susceptible to the exploitation of dataset biases. This scheme also does little to account for the different ways of expressing the same answer--an aspect of language that has been well studied in NLP. We propose a revised evaluation scheme for the VisDial dataset leveraging metrics from the NLP literature to measure consensus between answers generated by the model and a set of relevant answers. We construct these relevant answer sets using a simple and effective semi-supervised method based on correlation, which allows us to automatically extend and scale sparse relevance annotations from humans to the entire dataset. We release these sets and code for the revised evaluation scheme as DenseVisDial, and intend them to be an improvement to the dataset in the face of its existing constraints and design choices.