 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditVal: Benchmarking Diffusion Based Text-Guided Image Editing Methods
Paper and Code

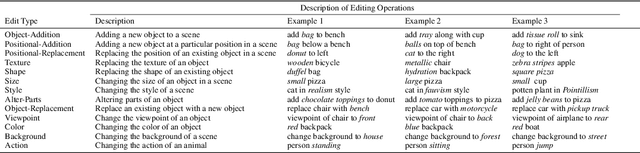
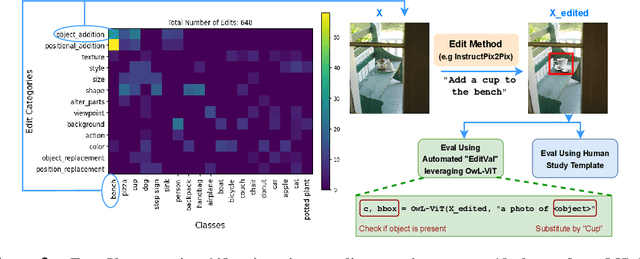
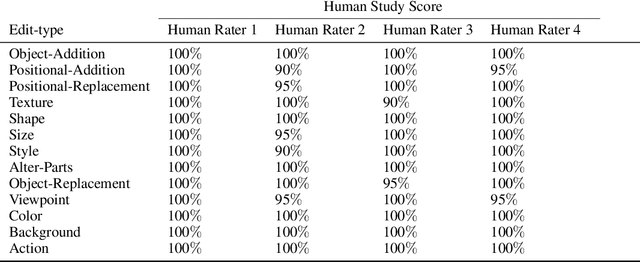
A plethora of text-guided image editing methods have recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models such as Imagen and Stable Diffusion. A standardized evaluation protocol, however, does not exist to compare methods across different types of fine-grained edits. To address this gap, we introduce EditVal, a standardized benchmark for quantitatively evaluating text-guided image editing methods. EditVal consists of a curated dataset of images, a set of editable attributes for each image drawn from 13 possible edit types, and an automated evaluation pipeline that uses pre-trained vision-language models to assess the fidelity of generated images for each edit type. We use EditVal to benchmark 8 cutting-edge diffusion-based editing methods including SINE, Imagic and Instruct-Pix2Pix. We complement this with a large-scale human study where we show that EditVall's automated evaluation pipeline is strongly correlated with human-preferences for the edit types we considered. From both the human study and automated evaluation, we find that: (i) Instruct-Pix2Pix, Null-Text and SINE are the top-performing methods averaged across different edit types, however {\it only} Instruct-Pix2Pix and Null-Text are able to preserve original image properties; (ii) Most of the editing methods fail at edits involving spatial operations (e.g., changing the position of an object). (iii) There is no `winner' method which ranks the best individually across a range of different edit types. We hope that our benchmark can pave the way to developing more reliable text-guided image editing tools in the future. We will publicly release EditVal, and all associated code and human-study templates to support these research directions in https://deep-ml-research.github.io/editval/.