 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Expert Sharing: Decoupling Memory from Parallelism in Mixture-of-Experts Diffusion LLMs
Jan 31, 2026Among parallel decoding paradigms, diffusion large language models (dLLMs) have emerged as a promising candidate that balances generation quality and throughput. However, their integration with Mixture-of-Experts (MoE) architectures is constrained by an expert explosion: as the number of tokens generated in parallel increases, the number of distinct experts activated grows nearly linearly. This results in substantial memory traffic that pushes inference into a memory-bound regime, negating the efficiency gains of both MoE and parallel decoding. To address this challenge, we propose Dynamic Expert Sharing (DES), a novel technique that shifts MoE optimization from token-centric pruning and conventional expert skipping methods to sequence-level coreset selection. To maximize expert reuse, DES identifies a compact, high-utility set of experts to satisfy the requirements of an entire parallel decoding block. We introduce two innovative selection strategies: (1) Intra-Sequence Sharing (DES-Seq), which adapts optimal allocation to the sequence level, and (2) Saliency-Aware Voting (DES-Vote), a novel mechanism that allows tokens to collectively elect a coreset based on aggregated router weights. Extensive experiments on MoE dLLMs demonstrate that DES reduces unique expert activations by over 55% and latency by up to 38%, while retaining 99% of vanilla accuracy, effectively decoupling memory overhead from the degree of parallelism.
Accelerating 3D Gaussian Splatting with Neural Sorting and Axis-Oriented Rasterization
Jun 08, 2025



3D Gaussian Splatting (3DGS) has recently gained significant attention for high-quality and efficient view synthesis, making it widely adopted in fields such as AR/VR, robotics, and autonomous driving. Despite its impressive algorithmic performance, real-time rendering on resource-constrained devices remains a major challenge due to tight power and area budgets. This paper presents an architecture-algorithm co-design to address these inefficiencies. First, we reveal substantial redundancy caused by repeated computation of common terms/expressions during the conventional rasterization. To resolve this, we propose axis-oriented rasterization, which pre-computes and reuses shared terms along both the X and Y axes through a dedicated hardware design, effectively reducing multiply-and-add (MAC) operations by up to 63%. Second, by identifying the resource and performance inefficiency of the sorting process, we introduce a novel neural sorting approach that predicts order-independent blending weights using an efficient neural network, eliminating the need for costly hardware sorters. A dedicated training framework is also proposed to improve its algorithmic stability. Third, to uniformly support rasterization and neural network inference, we design an efficient reconfigurable processing array that maximizes hardware utilization and throughput. Furthermore, we introduce a $\pi$-trajectory tile schedule, inspired by Morton encoding and Hilbert curve, to optimize Gaussian reuse and reduce memory access overhead. Comprehensive experiments demonstrate that the proposed design preserves rendering quality while achieving a speedup of $23.4\sim27.8\times$ and energy savings of $28.8\sim51.4\times$ compared to edge GPUs for real-world scenes. We plan to open-source our design to foster further development in this field.
FW-Merging: Scaling Model Merging with Frank-Wolfe Optimization
Mar 16, 2025Model merging has emerged as a promising approach for multi-task learning (MTL), offering a data-efficient alternative to conventional fine-tuning. However, with the rapid development of the open-source AI ecosystem and the increasing availability of fine-tuned foundation models, existing model merging methods face two key limitations: (i) They are primarily designed for in-house fine-tuned models, making them less adaptable to diverse model sources with partially unknown model and task information, (ii) They struggle to scale effectively when merging numerous model checkpoints. To address these challenges, we formulate model merging as a constrained optimization problem and introduce a novel approach: Frank-Wolfe Merging (FW-Merging). Inspired by Frank-Wolfe optimization, our approach iteratively selects the most relevant model in the pool to minimize a linear approximation of the objective function and then executes a local merging similar to the Frank-Wolfe update. The objective function is designed to capture the desired behavior of the target-merged model, while the fine-tuned candidate models define the constraint set. More importantly, FW-Merging serves as an orthogonal technique for existing merging methods, seamlessly integrating with them to further enhance accuracy performance. Our experiments show that FW-Merging scales across diverse model sources, remaining stable with 16 irrelevant models and improving by 15.3% with 16 relevant models on 20 CV tasks, while maintaining constant memory overhead, unlike the linear overhead of data-informed merging methods. Compared with the state-of-the-art approaches, FW-Merging surpasses the data-free merging method by 32.8% and outperforms the data-informed Adamerging by 8.39% when merging 20 ViT models.
MobileQuant: Mobile-friendly Quantization for On-device Language Models
Aug 25, 2024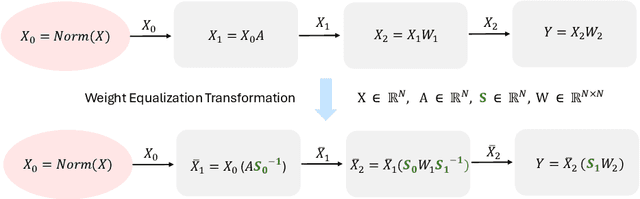
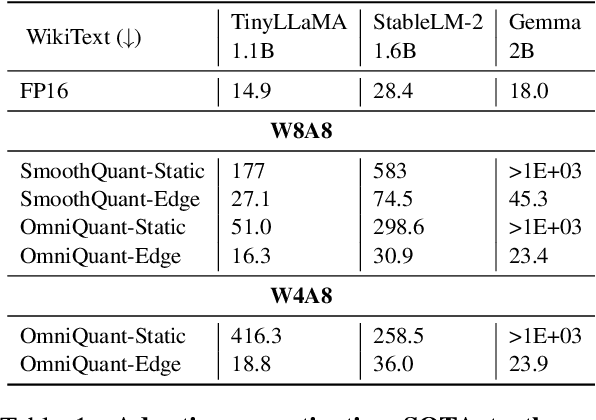

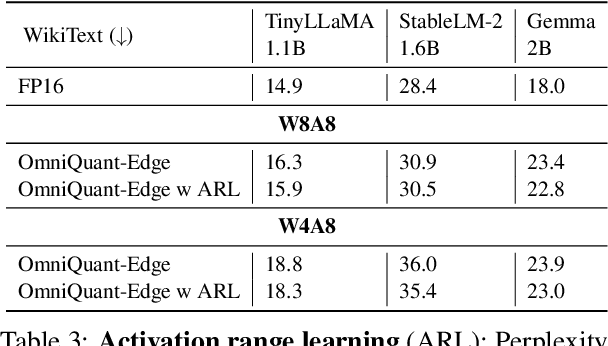
Large language models (LLMs) have revolutionized language processing, delivering outstanding results across multiple applications. However, deploying LLMs on edge devices poses several challenges with respect to memory, energy, and compute costs, limiting their widespread use in devices such as mobile phones. A promising solution is to reduce the number of bits used to represent weights and activations. While existing works have found partial success at quantizing LLMs to lower bitwidths, e.g. 4-bit weights, quantizing activations beyond 16 bits often leads to large computational overheads due to poor on-device quantization support, or a considerable accuracy drop. Yet, 8-bit activations are very attractive for on-device deployment as they would enable LLMs to fully exploit mobile-friendly hardware, e.g. Neural Processing Units (NPUs). In this work, we make a first attempt to facilitate the on-device deployment of LLMs using integer-only quantization. We first investigate the limitations of existing quantization methods for on-device deployment, with a special focus on activation quantization. We then address these limitations by introducing a simple post-training quantization method, named MobileQuant, that extends previous weight equivalent transformation works by jointly optimizing the weight transformation and activation range parameters in an end-to-end manner. MobileQuant demonstrates superior capabilities over existing methods by 1) achieving near-lossless quantization on a wide range of LLM benchmarks, 2) reducing latency and energy consumption by 20\%-50\% compared to current on-device quantization strategies, 3) requiring limited compute budget, 4) being compatible with mobile-friendly compute units, e.g. NPU.
BioKGBench: A Knowledge Graph Checking Benchmark of AI Agent for Biomedical Science
Jun 29, 2024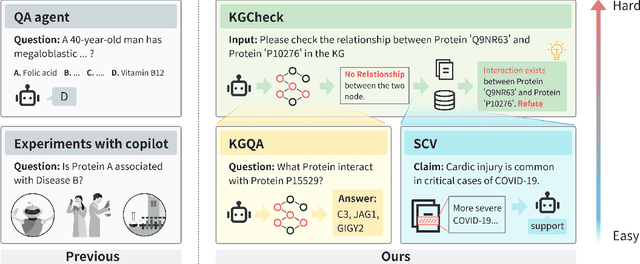
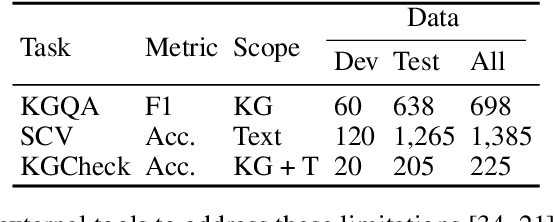
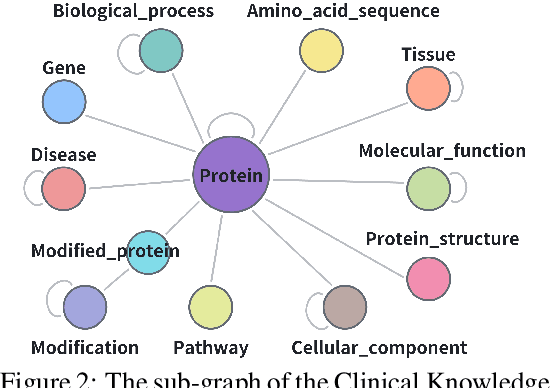
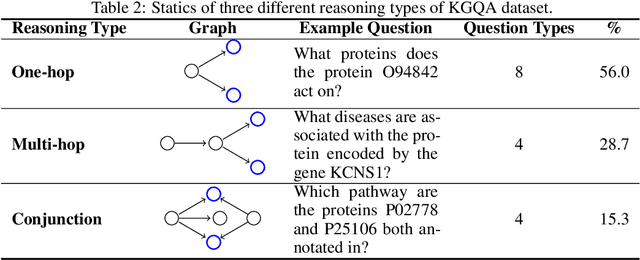
Pursuing artificial intelligence for biomedical science, a.k.a. AI Scientist, draws increasing attention, where one common approach is to build a copilot agent driven by Large Language Models (LLMs). However, to evaluate such systems, people either rely on direct Question-Answering (QA) to the LLM itself, or in a biomedical experimental manner. How to precisely benchmark biomedical agents from an AI Scientist perspective remains largely unexplored. To this end, we draw inspiration from one most important abilities of scientists, understanding the literature, and introduce BioKGBench. In contrast to traditional evaluation benchmark that only focuses on factual QA, where the LLMs are known to have hallucination issues, we first disentangle "Understanding Literature" into two atomic abilities, i) "Understanding" the unstructured text from research papers by performing scientific claim verification, and ii) Ability to interact with structured Knowledge-Graph Question-Answering (KGQA) as a form of "Literature" grounding. We then formulate a novel agent task, dubbed KGCheck, using KGQA and domain-based Retrieval-Augmented Generation (RAG) to identify the factual errors of existing large-scale knowledge graph databases. We collect over two thousand data for two atomic tasks and 225 high-quality annotated data for the agent task. Surprisingly, we discover that state-of-the-art agents, both daily scenarios and biomedical ones, have either failed or inferior performance on our benchmark. We then introduce a simple yet effective baseline, dubbed BKGAgent. On the widely used popular knowledge graph, we discover over 90 factual errors which provide scenarios for agents to make discoveries and demonstrate the effectiveness of our approach. The code and data are available at https://github.com/westlake-autolab/BioKGBench.
Recurrent Early Exits for Federated Learning with Heterogeneous Clients
May 23, 2024Federated learning (FL) has enabled distributed learning of a model across multiple clients in a privacy-preserving manner. One of the main challenges of FL is to accommodate clients with varying hardware capacities; clients have differing compute and memory requirements. To tackle this challenge, recent state-of-the-art approaches leverage the use of early exits. Nonetheless, these approaches fall short of mitigating the challenges of joint learning multiple exit classifiers, often relying on hand-picked heuristic solutions for knowledge distillation among classifiers and/or utilizing additional layers for weaker classifiers. In this work, instead of utilizing multiple classifiers, we propose a recurrent early exit approach named ReeFL that fuses features from different sub-models into a single shared classifier. Specifically, we use a transformer-based early-exit module shared among sub-models to i) better exploit multi-layer feature representations for task-specific prediction and ii) modulate the feature representation of the backbone model for subsequent predictions. We additionally present a per-client self-distillation approach where the best sub-model is automatically selected as the teacher of the other sub-models at each client. Our experiments on standard image and speech classification benchmarks across various emerging federated fine-tuning baselines demonstrate ReeFL's effectiveness over previous works.
EditVal: Benchmarking Diffusion Based Text-Guided Image Editing Methods
Oct 03, 2023
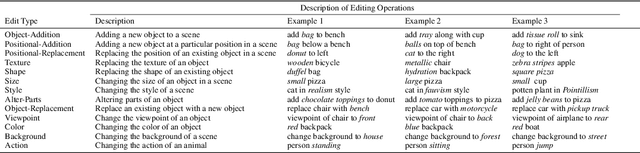
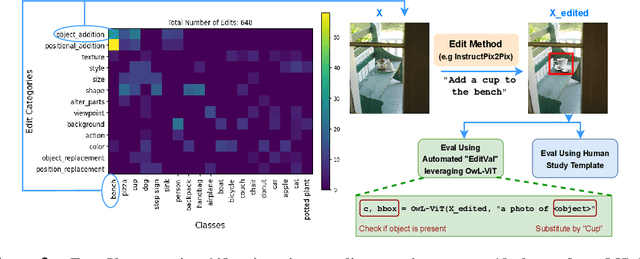
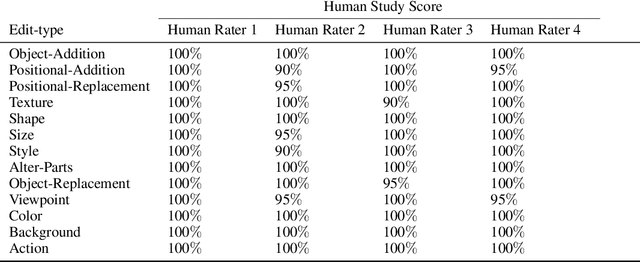
A plethora of text-guided image editing methods have recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models such as Imagen and Stable Diffusion. A standardized evaluation protocol, however, does not exist to compare methods across different types of fine-grained edits. To address this gap, we introduce EditVal, a standardized benchmark for quantitatively evaluating text-guided image editing methods. EditVal consists of a curated dataset of images, a set of editable attributes for each image drawn from 13 possible edit types, and an automated evaluation pipeline that uses pre-trained vision-language models to assess the fidelity of generated images for each edit type. We use EditVal to benchmark 8 cutting-edge diffusion-based editing methods including SINE, Imagic and Instruct-Pix2Pix. We complement this with a large-scale human study where we show that EditVall's automated evaluation pipeline is strongly correlated with human-preferences for the edit types we considered. From both the human study and automated evaluation, we find that: (i) Instruct-Pix2Pix, Null-Text and SINE are the top-performing methods averaged across different edit types, however {\it only} Instruct-Pix2Pix and Null-Text are able to preserve original image properties; (ii) Most of the editing methods fail at edits involving spatial operations (e.g., changing the position of an object). (iii) There is no `winner' method which ranks the best individually across a range of different edit types. We hope that our benchmark can pave the way to developing more reliable text-guided image editing tools in the future. We will publicly release EditVal, and all associated code and human-study templates to support these research directions in https://deep-ml-research.github.io/editval/.
Augmenting CLIP with Improved Visio-Linguistic Reasoning
Jul 27, 2023Image-text contrastive models such as CLIP are useful for a variety of downstream applications including zero-shot classification, image-text retrieval and transfer learning. However, these contrastively trained vision-language models often fail on compositional visio-linguistic tasks such as Winoground with performance equivalent to random chance. In our paper, we address this issue and propose a sample-efficient light-weight method called SDS-CLIP to improve the compositional visio-linguistic reasoning capabilities of CLIP. The core idea of our method is to use differentiable image parameterizations to fine-tune CLIP with a distillation objective from large text-to-image generative models such as Stable-Diffusion which are relatively good at visio-linguistic reasoning tasks. On the challenging Winoground compositional reasoning benchmark, our method improves the absolute visio-linguistic performance of different CLIP models by up to 7%, while on the ARO dataset, our method improves the visio-linguistic performance by upto 3%. As a byproduct of inducing visio-linguistic reasoning into CLIP, we also find that the zero-shot performance improves marginally on a variety of downstream datasets. Our method reinforces that carefully designed distillation objectives from generative models can be leveraged to extend existing contrastive image-text models with improved visio-linguistic reasoning capabilities.
Strong Baselines for Parameter Efficient Few-Shot Fine-tuning
Apr 04, 2023Few-shot classification (FSC) entails learning novel classes given only a few examples per class after a pre-training (or meta-training) phase on a set of base classes. Recent works have shown that simply fine-tuning a pre-trained Vision Transformer (ViT) on new test classes is a strong approach for FSC. Fine-tuning ViTs, however, is expensive in time, compute and storage. This has motivated the design of parameter efficient fine-tuning (PEFT) methods which fine-tune only a fraction of the Transformer's parameters. While these methods have shown promise, inconsistencies in experimental conditions make it difficult to disentangle their advantage from other experimental factors including the feature extractor architecture, pre-trained initialization and fine-tuning algorithm, amongst others. In our paper, we conduct a large-scale, experimentally consistent, empirical analysis to study PEFTs for few-shot image classification. Through a battery of over 1.8k controlled experiments on large-scale few-shot benchmarks including Meta-Dataset (MD) and ORBIT, we uncover novel insights on PEFTs that cast light on their efficacy in fine-tuning ViTs for few-shot classification. Through our controlled empirical study, we have two main findings: (i) Fine-tuning just the LayerNorm parameters (which we call LN-Tune) during few-shot adaptation is an extremely strong baseline across ViTs pre-trained with both self-supervised and supervised objectives, (ii) For self-supervised ViTs, we find that simply learning a set of scaling parameters for each attention matrix (which we call AttnScale) along with a domain-residual adapter (DRA) module leads to state-of-the-art performance (while being $\sim\!$ 9$\times$ more parameter-efficient) on MD. Our extensive empirical findings set strong baselines and call for rethinking the current design of PEFT methods for FSC.
Federated Learning for Inference at Anytime and Anywhere
Dec 08, 2022



Federated learning has been predominantly concerned with collaborative training of deep networks from scratch, and especially the many challenges that arise, such as communication cost, robustness to heterogeneous data, and support for diverse device capabilities. However, there is no unified framework that addresses all these problems together. This paper studies the challenges and opportunities of exploiting pre-trained Transformer models in FL. In particular, we propose to efficiently adapt such pre-trained models by injecting a novel attention-based adapter module at each transformer block that both modulates the forward pass and makes an early prediction. Training only the lightweight adapter by FL leads to fast and communication-efficient learning even in the presence of heterogeneous data and devices. Extensive experiments on standard FL benchmarks, including CIFAR-100, FEMNIST and SpeechCommandsv2 demonstrate that this simple framework provides fast and accurate FL while supporting heterogenous device capabilities, efficient personalization, and scalable-cost anytime inference.