 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALI: A Workload-Aware Offloading Framework for Efficient MoE Inference on Local PCs
Feb 03, 2026Mixture of Experts (MoE) architectures significantly enhance the capacity of LLMs without proportional increases in computation, but at the cost of a vast parameter size. Offloading MoE expert parameters to host memory and leveraging both CPU and GPU computation has recently emerged as a promising direction to support such models on resourceconstrained local PC platforms. While promising, we notice that existing approaches mismatch the dynamic nature of expert workloads, which leads to three fundamental inefficiencies: (1) Static expert assignment causes severe CPUGPU load imbalance, underutilizing CPU and GPU resources; (2) Existing prefetching techniques fail to accurately predict high-workload experts, leading to costly inaccurate prefetches; (3) GPU cache policies neglect workload dynamics, resulting in poor hit rates and limited effectiveness. To address these challenges, we propose DALI, a workloaDAware offLoadIng framework for efficient MoE inference on local PCs. To fully utilize hardware resources, DALI first dynamically assigns experts to CPU or GPU by modeling assignment as a 0-1 integer optimization problem and solving it efficiently using a Greedy Assignment strategy at runtime. To improve prefetching accuracy, we develop a Residual-Based Prefetching method leveraging inter-layer residual information to accurately predict high-workload experts. Additionally, we introduce a Workload-Aware Cache Replacement policy that exploits temporal correlation in expert activations to improve GPU cache efficiency. By evaluating across various MoE models and settings, DALI achieves significant speedups in the both prefill and decoding phases over the state-of-the-art offloading frameworks.
Accelerating 3D Gaussian Splatting with Neural Sorting and Axis-Oriented Rasterization
Jun 08, 2025



3D Gaussian Splatting (3DGS) has recently gained significant attention for high-quality and efficient view synthesis, making it widely adopted in fields such as AR/VR, robotics, and autonomous driving. Despite its impressive algorithmic performance, real-time rendering on resource-constrained devices remains a major challenge due to tight power and area budgets. This paper presents an architecture-algorithm co-design to address these inefficiencies. First, we reveal substantial redundancy caused by repeated computation of common terms/expressions during the conventional rasterization. To resolve this, we propose axis-oriented rasterization, which pre-computes and reuses shared terms along both the X and Y axes through a dedicated hardware design, effectively reducing multiply-and-add (MAC) operations by up to 63%. Second, by identifying the resource and performance inefficiency of the sorting process, we introduce a novel neural sorting approach that predicts order-independent blending weights using an efficient neural network, eliminating the need for costly hardware sorters. A dedicated training framework is also proposed to improve its algorithmic stability. Third, to uniformly support rasterization and neural network inference, we design an efficient reconfigurable processing array that maximizes hardware utilization and throughput. Furthermore, we introduce a $\pi$-trajectory tile schedule, inspired by Morton encoding and Hilbert curve, to optimize Gaussian reuse and reduce memory access overhead. Comprehensive experiments demonstrate that the proposed design preserves rendering quality while achieving a speedup of $23.4\sim27.8\times$ and energy savings of $28.8\sim51.4\times$ compared to edge GPUs for real-world scenes. We plan to open-source our design to foster further development in this field.
Accelerating Prefilling for Long-Context LLMs via Sparse Pattern Sharing
May 26, 2025Sparse attention methods exploit the inherent sparsity in attention to speed up the prefilling phase of long-context inference, mitigating the quadratic complexity of full attention computation. While existing sparse attention methods rely on predefined patterns or inaccurate estimations to approximate attention behavior, they often fail to fully capture the true dynamics of attention, resulting in reduced efficiency and compromised accuracy. Instead, we propose a highly accurate sparse attention mechanism that shares similar yet precise attention patterns across heads, enabling a more realistic capture of the dynamic behavior of attention. Our approach is grounded in two key observations: (1) attention patterns demonstrate strong inter-head similarity, and (2) this similarity remains remarkably consistent across diverse inputs. By strategically sharing computed accurate patterns across attention heads, our method effectively captures actual patterns while requiring full attention computation for only a small subset of heads. Comprehensive evaluations demonstrate that our approach achieves superior or comparable speedup relative to state-of-the-art methods while delivering the best overall accuracy.
DNN Training Acceleration via Exploring GPGPU Friendly Sparsity
Mar 11, 2022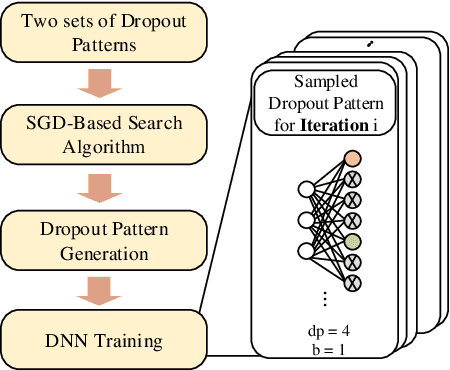
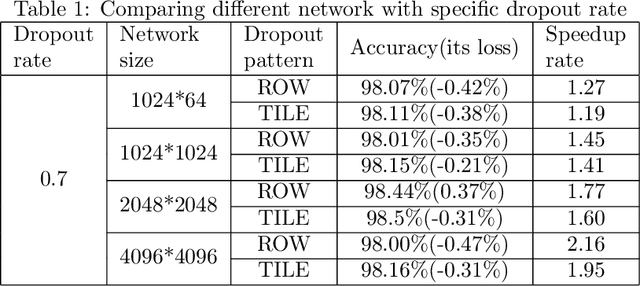
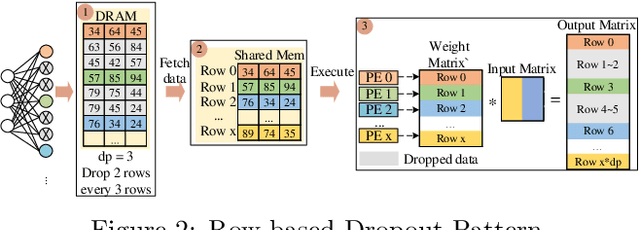
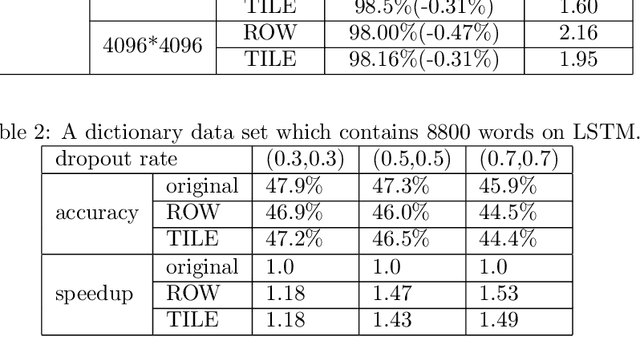
The training phases of Deep neural network~(DNN) consumes enormous processing time and energy. Compression techniques utilizing the sparsity of DNNs can effectively accelerate the inference phase of DNNs. However, it is hardly used in the training phase because the training phase involves dense matrix-multiplication using General-Purpose Computation on Graphics Processors (GPGPU), which endorse the regular and structural data layout. In this paper, we first propose the Approximate Random Dropout that replaces the conventional random dropout of neurons and synapses with a regular and online generated row-based or tile-based dropout patterns to eliminate the unnecessary computation and data access for the multilayer perceptron~(MLP) and long short-term memory~(LSTM). We then develop a SGD-based Search Algorithm that produces the distribution of row-based or tile-based dropout patterns to compensate for the potential accuracy loss. Moreover, aiming at the convolution neural network~(CNN) training acceleration, we first explore the importance and sensitivity of input feature maps; and then propose the sensitivity-aware dropout method to dynamically drop the input feature maps based on their sensitivity so as to achieve greater forward and backward training acceleration while reserving better NN accuracy. To facilitate DNN programming, we build a DNN training computation framework that unifies the proposed techniques in the software stack. As a result, the GPGPU only needs to support the basic operator -- matrix multiplication and can achieve significant performance improvement regardless of DNN model.
CP-ViT: Cascade Vision Transformer Pruning via Progressive Sparsity Prediction
Mar 09, 2022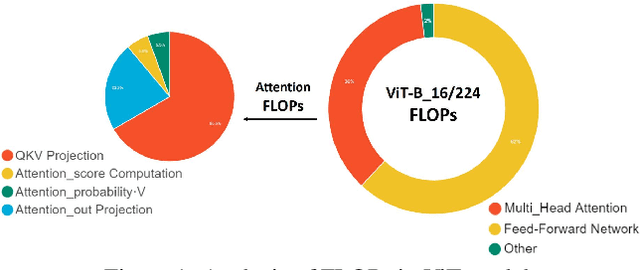
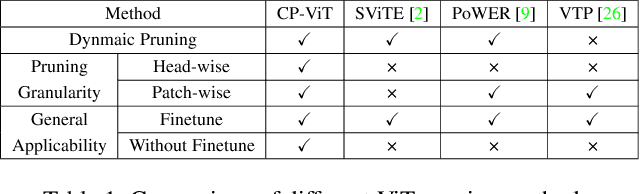
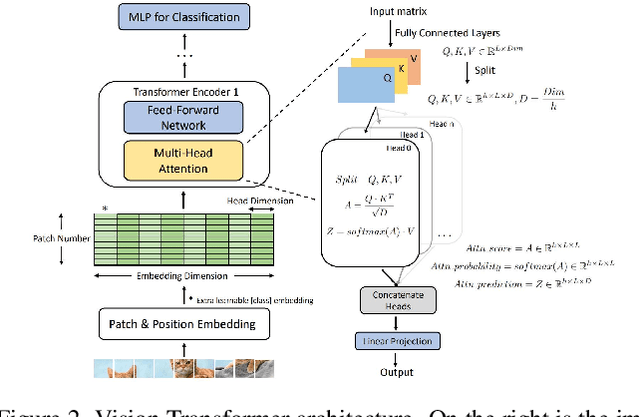
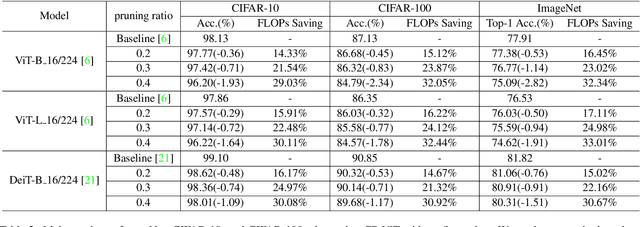
Vision transformer (ViT) has achieved competitive accuracy on a variety of computer vision applications, but its computational cost impedes the deployment on resource-limited mobile devices. We explore the sparsity in ViT and observe that informative patches and heads are sufficient for accurate image recognition. In this paper, we propose a cascade pruning framework named CP-ViT by predicting sparsity in ViT models progressively and dynamically to reduce computational redundancy while minimizing the accuracy loss. Specifically, we define the cumulative score to reserve the informative patches and heads across the ViT model for better accuracy. We also propose the dynamic pruning ratio adjustment technique based on layer-aware attention range. CP-ViT has great general applicability for practical deployment, which can be applied to a wide range of ViT models and can achieve superior accuracy with or without fine-tuning. Extensive experiments on ImageNet, CIFAR-10, and CIFAR-100 with various pre-trained models have demonstrated the effectiveness and efficiency of CP-ViT. By progressively pruning 50\% patches, our CP-ViT method reduces over 40\% FLOPs while maintaining accuracy loss within 1\%.
Invocation-driven Neural Approximate Computing with a Multiclass-Classifier and Multiple Approximators
Oct 19, 2018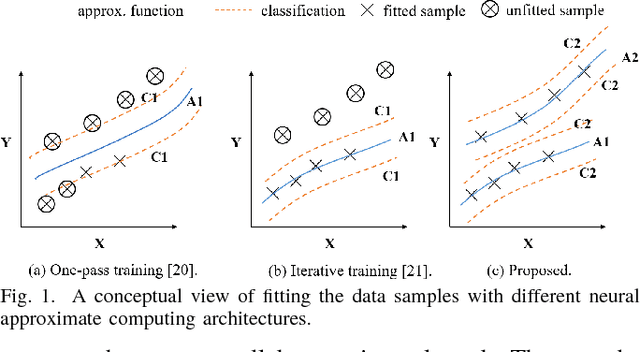
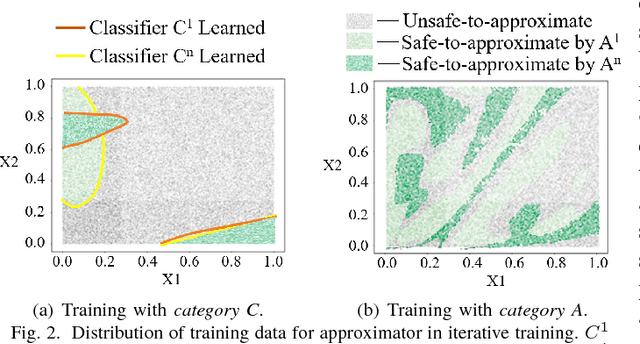
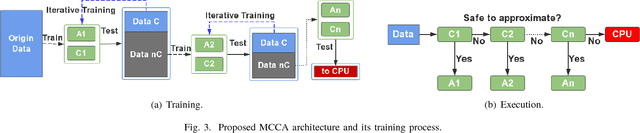
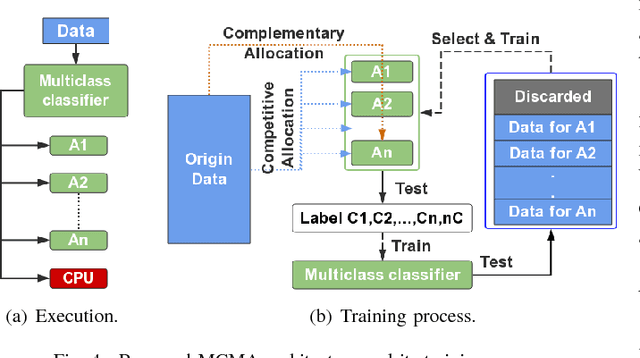
Neural approximate computing gains enormous energy-efficiency at the cost of tolerable quality-loss. A neural approximator can map the input data to output while a classifier determines whether the input data are safe to approximate with quality guarantee. However, existing works cannot maximize the invocation of the approximator, resulting in limited speedup and energy saving. By exploring the mapping space of those target functions, in this paper, we observe a nonuniform distribution of the approximation error incurred by the same approximator. We thus propose a novel approximate computing architecture with a Multiclass-Classifier and Multiple Approximators (MCMA). These approximators have identical network topologies and thus can share the same hardware resource in a neural processing unit(NPU) clip. In the runtime, MCMA can swap in the invoked approximator by merely shipping the synapse weights from the on-chip memory to the buffers near MAC within a cycle. We also propose efficient co-training methods for such MCMA architecture. Experimental results show a more substantial invocation of MCMA as well as the gain of energy-efficiency.
Approximate Random Dropout
May 23, 2018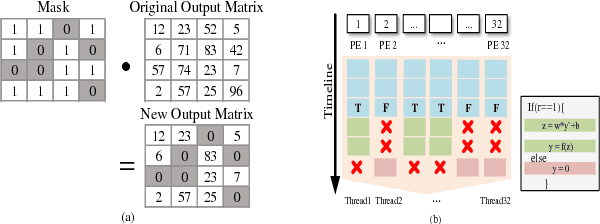
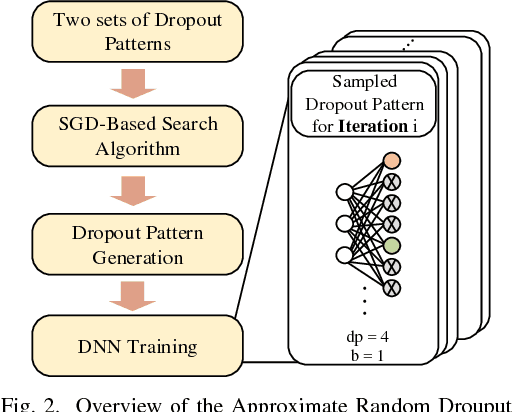
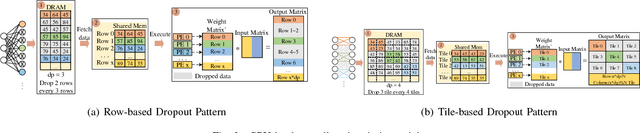
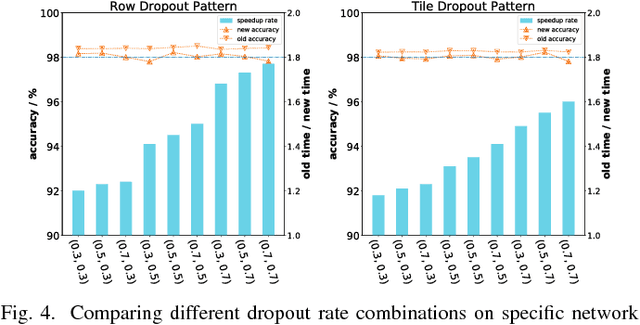
The training phases of Deep neural network (DNN) consume enormous processing time and energy. Compression techniques for inference acceleration leveraging the sparsity of DNNs, however, can be hardly used in the training phase. Because the training involves dense matrix-multiplication using GPGPU, which endorse regular and structural data layout. In this paper, we exploit the sparsity of DNN resulting from the random dropout technique to eliminate the unnecessary computation and data access for those dropped neurons or synapses in the training phase. Experiments results on MLP and LSTM on standard benchmarks show that the proposed Approximate Random Dropout can reduce the training time by half on average with ignorable accuracy loss.