 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3: DIMM-PIM Integrated Architecture and Coordination for Scalable Long-Context LLM Inference
Apr 24, 2025Large Language Models (LLMs) increasingly require processing long text sequences, but GPU memory limitations force difficult trade-offs between memory capacity and bandwidth. While HBM-based acceleration offers high bandwidth, its capacity remains constrained. Offloading data to host-side DIMMs improves capacity but introduces costly data swapping overhead. We identify that the critical memory bottleneck lies in the decoding phase of multi-head attention (MHA) exclusively, which demands substantial capacity for storing KV caches and high bandwidth for attention computation. Our key insight reveals this operation uniquely aligns with modern DIMM-based processing-in-memory (PIM) architectures, which offers scalability of both capacity and bandwidth. Based on this observation and insight, we propose L3, a hardware-software co-designed system integrating DIMM-PIM and GPU devices. L3 introduces three innovations: First, hardware redesigns resolve data layout mismatches and computational element mismatches in DIMM-PIM, enhancing LLM inference utilization. Second, communication optimization enables hiding the data transfer overhead with the computation. Third, an adaptive scheduler coordinates GPU-DIMM-PIM operations to maximize parallelism between devices. Evaluations using real-world traces show L3 achieves up to 6.1$\times$ speedup over state-of-the-art HBM-PIM solutions while significantly improving batch sizes.
LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration
Aug 12, 2024As large language model (LLM) inference demands ever-greater resources, there is a rapid growing trend of using low-bit weights to shrink memory usage and boost inference efficiency. However, these low-bit LLMs introduce the need for mixed-precision matrix multiplication (mpGEMM), which is a crucial yet under-explored operation that involves multiplying lower-precision weights with higher-precision activations. Unfortunately, current hardware does not natively support mpGEMM, resulting in indirect and inefficient dequantization-based implementations. To address the mpGEMM requirements in low-bit LLMs, we explored the lookup table (LUT)-based approach for mpGEMM. However, a conventional LUT implementation falls short of its potential. To fully harness the power of LUT-based mpGEMM, we introduce LUT Tensor Core, a software-hardware co-design optimized for low-bit LLM inference. Specifically, we introduce software-based operator fusion and table symmetrization techniques to optimize table precompute and table storage, respectively. Then, LUT Tensor Core proposes the hardware design featuring an elongated tiling shape design to enhance table reuse and a bit-serial design to support various precision combinations in mpGEMM. Moreover, we design an end-to-end compilation stack with new instructions for LUT-based mpGEMM, enabling efficient LLM compilation and optimizations. The evaluation on low-bit LLMs (e.g., BitNet, LLAMA) shows that LUT Tensor Core achieves more than a magnitude of improvements on both compute density and energy efficiency.
DNN Training Acceleration via Exploring GPGPU Friendly Sparsity
Mar 11, 2022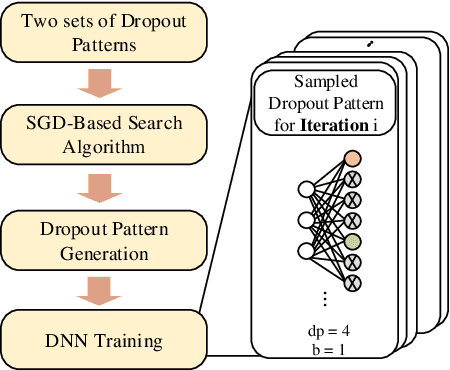
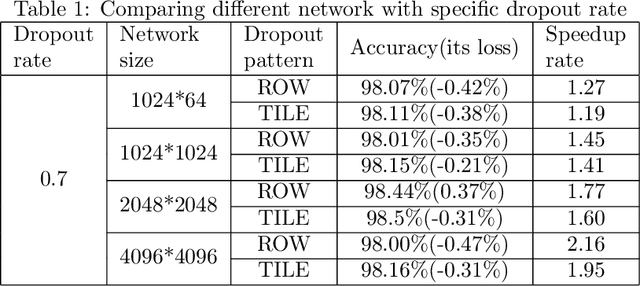
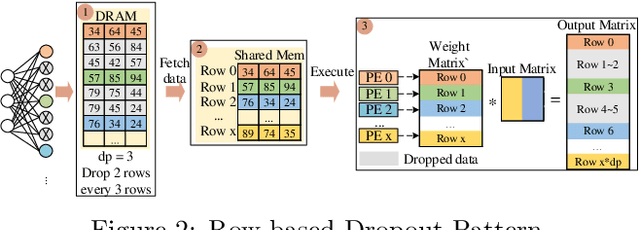
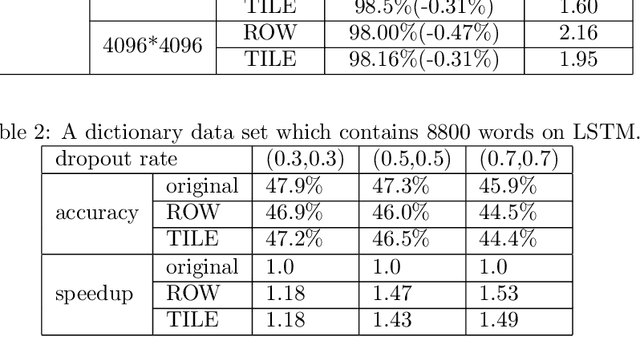
The training phases of Deep neural network~(DNN) consumes enormous processing time and energy. Compression techniques utilizing the sparsity of DNNs can effectively accelerate the inference phase of DNNs. However, it is hardly used in the training phase because the training phase involves dense matrix-multiplication using General-Purpose Computation on Graphics Processors (GPGPU), which endorse the regular and structural data layout. In this paper, we first propose the Approximate Random Dropout that replaces the conventional random dropout of neurons and synapses with a regular and online generated row-based or tile-based dropout patterns to eliminate the unnecessary computation and data access for the multilayer perceptron~(MLP) and long short-term memory~(LSTM). We then develop a SGD-based Search Algorithm that produces the distribution of row-based or tile-based dropout patterns to compensate for the potential accuracy loss. Moreover, aiming at the convolution neural network~(CNN) training acceleration, we first explore the importance and sensitivity of input feature maps; and then propose the sensitivity-aware dropout method to dynamically drop the input feature maps based on their sensitivity so as to achieve greater forward and backward training acceleration while reserving better NN accuracy. To facilitate DNN programming, we build a DNN training computation framework that unifies the proposed techniques in the software stack. As a result, the GPGPU only needs to support the basic operator -- matrix multiplication and can achieve significant performance improvement regardless of DNN model.
CP-ViT: Cascade Vision Transformer Pruning via Progressive Sparsity Prediction
Mar 09, 2022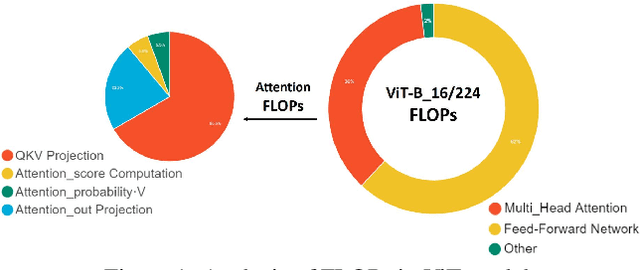
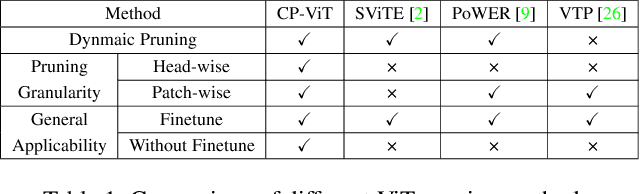
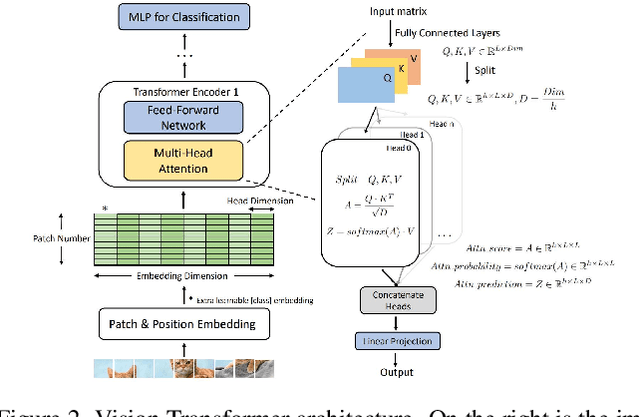
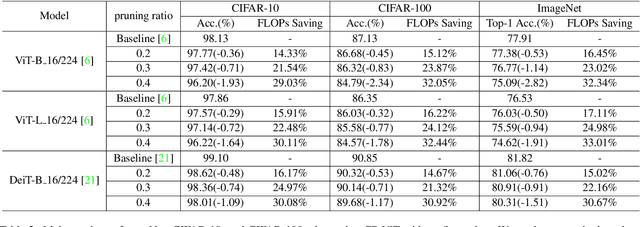
Vision transformer (ViT) has achieved competitive accuracy on a variety of computer vision applications, but its computational cost impedes the deployment on resource-limited mobile devices. We explore the sparsity in ViT and observe that informative patches and heads are sufficient for accurate image recognition. In this paper, we propose a cascade pruning framework named CP-ViT by predicting sparsity in ViT models progressively and dynamically to reduce computational redundancy while minimizing the accuracy loss. Specifically, we define the cumulative score to reserve the informative patches and heads across the ViT model for better accuracy. We also propose the dynamic pruning ratio adjustment technique based on layer-aware attention range. CP-ViT has great general applicability for practical deployment, which can be applied to a wide range of ViT models and can achieve superior accuracy with or without fine-tuning. Extensive experiments on ImageNet, CIFAR-10, and CIFAR-100 with various pre-trained models have demonstrated the effectiveness and efficiency of CP-ViT. By progressively pruning 50\% patches, our CP-ViT method reduces over 40\% FLOPs while maintaining accuracy loss within 1\%.
SME: ReRAM-based Sparse-Multiplication-Engine to Squeeze-Out Bit Sparsity of Neural Network
Mar 02, 2021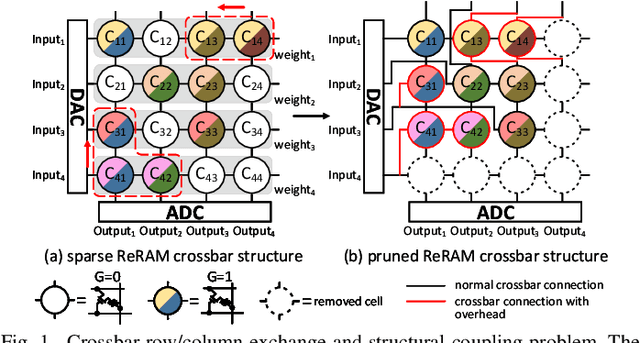
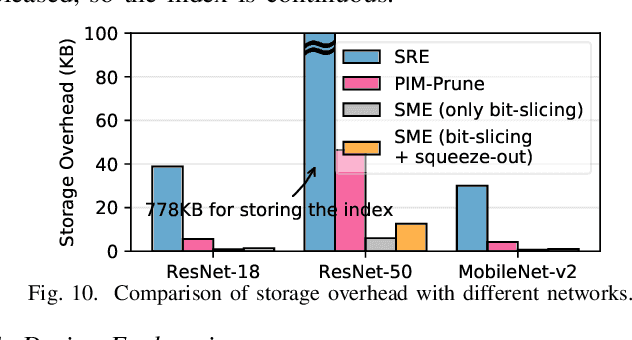
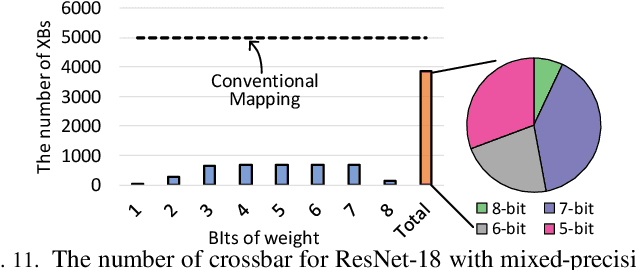
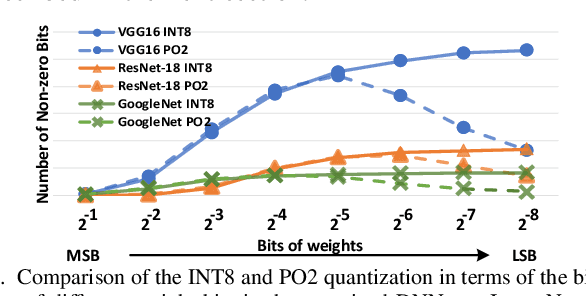
Resistive Random-Access-Memory (ReRAM) crossbar is a promising technique for deep neural network (DNN) accelerators, thanks to its in-memory and in-situ analog computing abilities for Vector-Matrix Multiplication-and-Accumulations (VMMs). However, it is challenging for crossbar architecture to exploit the sparsity in the DNN. It inevitably causes complex and costly control to exploit fine-grained sparsity due to the limitation of tightly-coupled crossbar structure. As the countermeasure, we developed a novel ReRAM-based DNN accelerator, named Sparse-Multiplication-Engine (SME), based on a hardware and software co-design framework. First, we orchestrate the bit-sparse pattern to increase the density of bit-sparsity based on existing quantization methods. Second, we propose a novel weigh mapping mechanism to slice the bits of a weight across the crossbars and splice the activation results in peripheral circuits. This mechanism can decouple the tightly-coupled crossbar structure and cumulate the sparsity in the crossbar. Finally, a superior squeeze-out scheme empties the crossbars mapped with highly-sparse non-zeros from the previous two steps. We design the SME architecture and discuss its use for other quantization methods and different ReRAM cell technologies. Compared with prior state-of-the-art designs, the SME shrinks the use of crossbars up to 8.7x and 2.1x using Resent-50 and MobileNet-v2, respectively, with less than 0.3% accuracy drop on ImageNet.
Invocation-driven Neural Approximate Computing with a Multiclass-Classifier and Multiple Approximators
Oct 19, 2018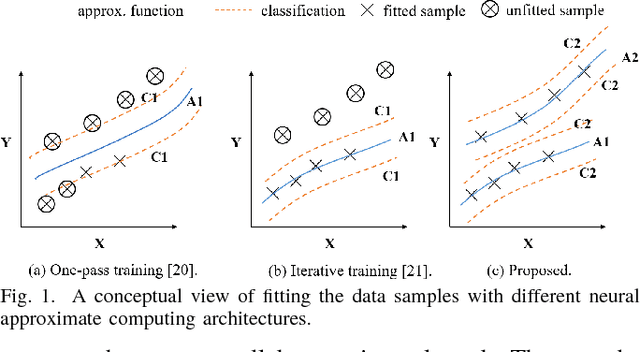
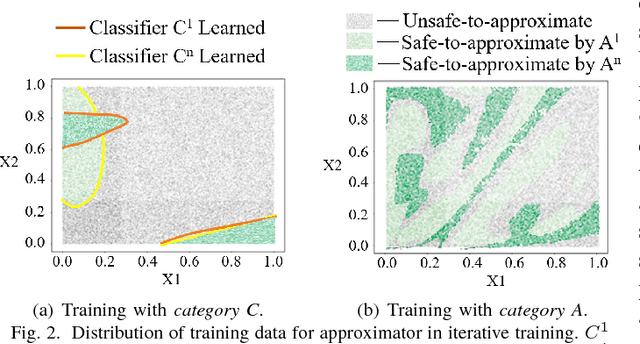
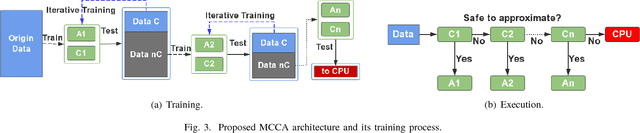
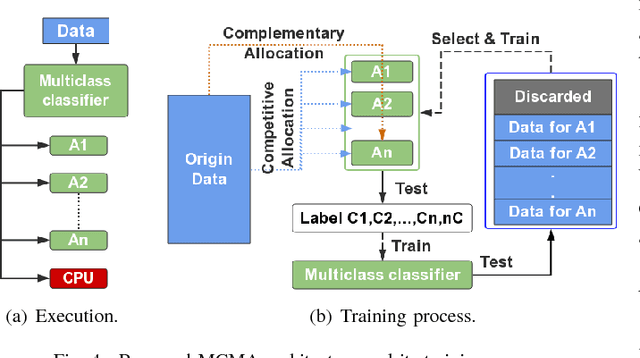
Neural approximate computing gains enormous energy-efficiency at the cost of tolerable quality-loss. A neural approximator can map the input data to output while a classifier determines whether the input data are safe to approximate with quality guarantee. However, existing works cannot maximize the invocation of the approximator, resulting in limited speedup and energy saving. By exploring the mapping space of those target functions, in this paper, we observe a nonuniform distribution of the approximation error incurred by the same approximator. We thus propose a novel approximate computing architecture with a Multiclass-Classifier and Multiple Approximators (MCMA). These approximators have identical network topologies and thus can share the same hardware resource in a neural processing unit(NPU) clip. In the runtime, MCMA can swap in the invoked approximator by merely shipping the synapse weights from the on-chip memory to the buffers near MAC within a cycle. We also propose efficient co-training methods for such MCMA architecture. Experimental results show a more substantial invocation of MCMA as well as the gain of energy-efficiency.
AXNet: ApproXimate computing using an end-to-end trainable neural network
Jul 27, 2018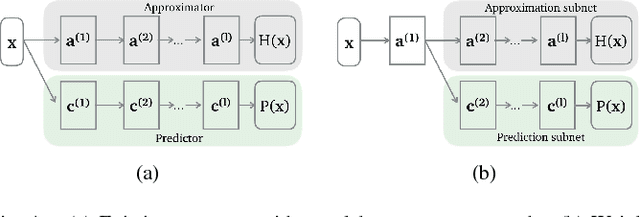
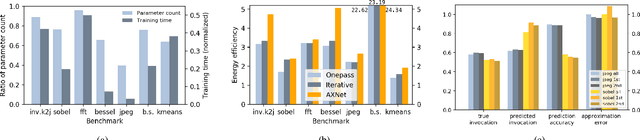
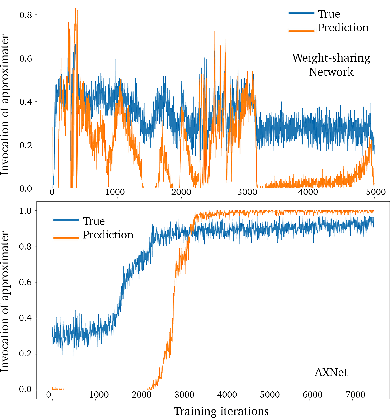
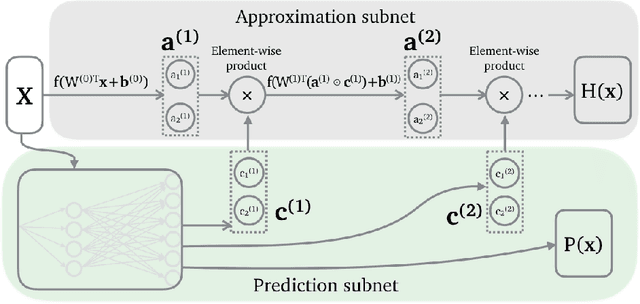
Neural network based approximate computing is a universal architecture promising to gain tremendous energy-efficiency for many error resilient applications. To guarantee the approximation quality, existing works deploy two neural networks (NNs), e.g., an approximator and a predictor. The approximator provides the approximate results, while the predictor predicts whether the input data is safe to approximate with the given quality requirement. However, it is non-trivial and time-consuming to make these two neural network coordinate---they have different optimization objectives---by training them separately. This paper proposes a novel neural network structure---AXNet---to fuse two NNs to a holistic end-to-end trainable NN. Leveraging the philosophy of multi-task learning, AXNet can tremendously improve the invocation (proportion of safe-to-approximate samples) and reduce the approximation error. The training effort also decrease significantly. Experiment results show 50.7% more invocation and substantial cuts of training time when compared to existing neural network based approximate computing framework.