 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCriticality-Based Dynamic Topology Optimization for Enhancing Aerial-Marine Swarm Resilience
Aug 01, 2025Heterogeneous marine-aerial swarm networks encounter substantial difficulties due to targeted communication disruptions and structural weaknesses in adversarial environments. This paper proposes a two-step framework to strengthen the network's resilience. Specifically, our framework combines the node prioritization based on criticality with multi-objective topology optimization. First, we design a three-layer architecture to represent structural, communication, and task dependencies of the swarm networks. Then, we introduce the SurBi-Ranking method, which utilizes graph convolutional networks, to dynamically evaluate and rank the criticality of nodes and edges in real time. Next, we apply the NSGA-III algorithm to optimize the network topology, aiming to balance communication efficiency, global connectivity, and mission success rate. Experiments demonstrate that compared to traditional methods like K-Shell, our SurBi-Ranking method identifies critical nodes and edges with greater accuracy, as deliberate attacks on these components cause more significant connectivity degradation. Furthermore, our optimization approach, when prioritizing SurBi-Ranked critical components under attack, reduces the natural connectivity degradation by around 30%, achieves higher mission success rates, and incurs lower communication reconfiguration costs, ensuring sustained connectivity and mission effectiveness across multi-phase operations.
DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition
Apr 30, 2025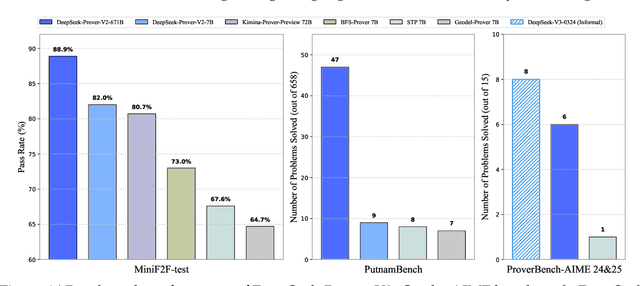
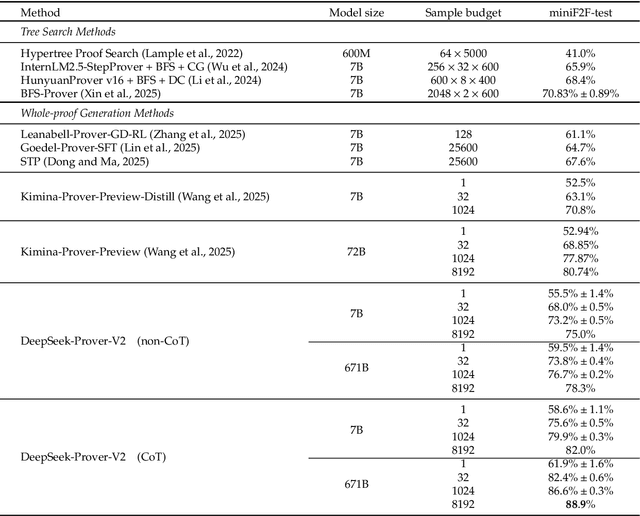

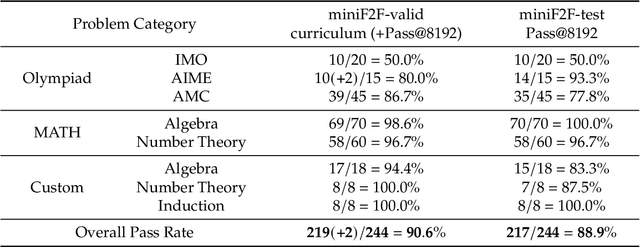
We introduce DeepSeek-Prover-V2, an open-source large language model designed for formal theorem proving in Lean 4, with initialization data collected through a recursive theorem proving pipeline powered by DeepSeek-V3. The cold-start training procedure begins by prompting DeepSeek-V3 to decompose complex problems into a series of subgoals. The proofs of resolved subgoals are synthesized into a chain-of-thought process, combined with DeepSeek-V3's step-by-step reasoning, to create an initial cold start for reinforcement learning. This process enables us to integrate both informal and formal mathematical reasoning into a unified model. The resulting model, DeepSeek-Prover-V2-671B, achieves state-of-the-art performance in neural theorem proving, reaching 88.9% pass ratio on the MiniF2F-test and solving 49 out of 658 problems from PutnamBench. In addition to standard benchmarks, we introduce ProverBench, a collection of 325 formalized problems, to enrich our evaluation, including 15 selected problems from the recent AIME competitions (years 24-25). Further evaluation on these 15 AIME problems shows that the model successfully solves 6 of them. In comparison, DeepSeek-V3 solves 8 of these problems using majority voting, highlighting that the gap between formal and informal mathematical reasoning in large language models is substantially narrowing.
L3: DIMM-PIM Integrated Architecture and Coordination for Scalable Long-Context LLM Inference
Apr 24, 2025Large Language Models (LLMs) increasingly require processing long text sequences, but GPU memory limitations force difficult trade-offs between memory capacity and bandwidth. While HBM-based acceleration offers high bandwidth, its capacity remains constrained. Offloading data to host-side DIMMs improves capacity but introduces costly data swapping overhead. We identify that the critical memory bottleneck lies in the decoding phase of multi-head attention (MHA) exclusively, which demands substantial capacity for storing KV caches and high bandwidth for attention computation. Our key insight reveals this operation uniquely aligns with modern DIMM-based processing-in-memory (PIM) architectures, which offers scalability of both capacity and bandwidth. Based on this observation and insight, we propose L3, a hardware-software co-designed system integrating DIMM-PIM and GPU devices. L3 introduces three innovations: First, hardware redesigns resolve data layout mismatches and computational element mismatches in DIMM-PIM, enhancing LLM inference utilization. Second, communication optimization enables hiding the data transfer overhead with the computation. Third, an adaptive scheduler coordinates GPU-DIMM-PIM operations to maximize parallelism between devices. Evaluations using real-world traces show L3 achieves up to 6.1$\times$ speedup over state-of-the-art HBM-PIM solutions while significantly improving batch sizes.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search
Aug 15, 2024



We introduce DeepSeek-Prover-V1.5, an open-source language model designed for theorem proving in Lean 4, which enhances DeepSeek-Prover-V1 by optimizing both training and inference processes. Pre-trained on DeepSeekMath-Base with specialization in formal mathematical languages, the model undergoes supervised fine-tuning using an enhanced formal theorem proving dataset derived from DeepSeek-Prover-V1. Further refinement is achieved through reinforcement learning from proof assistant feedback (RLPAF). Beyond the single-pass whole-proof generation approach of DeepSeek-Prover-V1, we propose RMaxTS, a variant of Monte-Carlo tree search that employs an intrinsic-reward-driven exploration strategy to generate diverse proof paths. DeepSeek-Prover-V1.5 demonstrates significant improvements over DeepSeek-Prover-V1, achieving new state-of-the-art results on the test set of the high school level miniF2F benchmark ($63.5\%$) and the undergraduate level ProofNet benchmark ($25.3\%$).