 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3: DIMM-PIM Integrated Architecture and Coordination for Scalable Long-Context LLM Inference
Apr 24, 2025Large Language Models (LLMs) increasingly require processing long text sequences, but GPU memory limitations force difficult trade-offs between memory capacity and bandwidth. While HBM-based acceleration offers high bandwidth, its capacity remains constrained. Offloading data to host-side DIMMs improves capacity but introduces costly data swapping overhead. We identify that the critical memory bottleneck lies in the decoding phase of multi-head attention (MHA) exclusively, which demands substantial capacity for storing KV caches and high bandwidth for attention computation. Our key insight reveals this operation uniquely aligns with modern DIMM-based processing-in-memory (PIM) architectures, which offers scalability of both capacity and bandwidth. Based on this observation and insight, we propose L3, a hardware-software co-designed system integrating DIMM-PIM and GPU devices. L3 introduces three innovations: First, hardware redesigns resolve data layout mismatches and computational element mismatches in DIMM-PIM, enhancing LLM inference utilization. Second, communication optimization enables hiding the data transfer overhead with the computation. Third, an adaptive scheduler coordinates GPU-DIMM-PIM operations to maximize parallelism between devices. Evaluations using real-world traces show L3 achieves up to 6.1$\times$ speedup over state-of-the-art HBM-PIM solutions while significantly improving batch sizes.
ActiveGAMER: Active GAussian Mapping through Efficient Rendering
Jan 12, 2025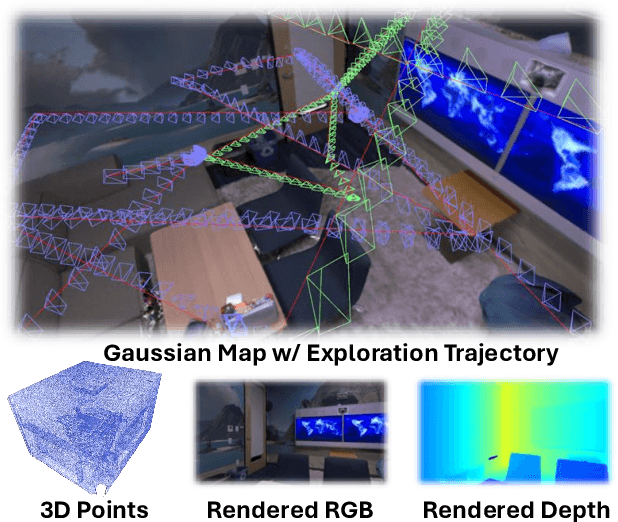
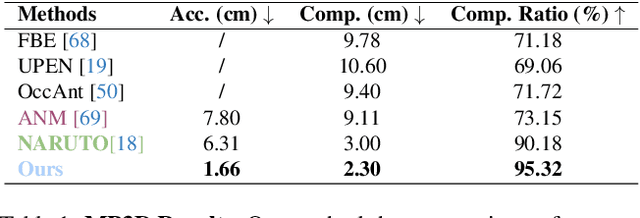

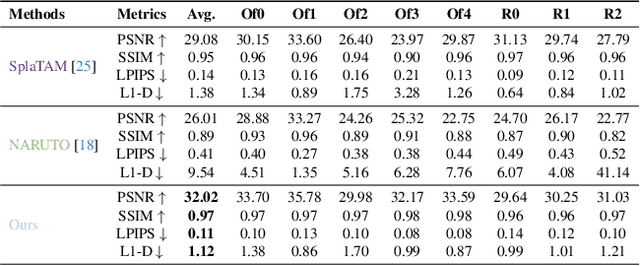
We introduce ActiveGAMER, an active mapping system that utilizes 3D Gaussian Splatting (3DGS) to achieve high-quality, real-time scene mapping and exploration. Unlike traditional NeRF-based methods, which are computationally demanding and restrict active mapping performance, our approach leverages the efficient rendering capabilities of 3DGS, allowing effective and efficient exploration in complex environments. The core of our system is a rendering-based information gain module that dynamically identifies the most informative viewpoints for next-best-view planning, enhancing both geometric and photometric reconstruction accuracy. ActiveGAMER also integrates a carefully balanced framework, combining coarse-to-fine exploration, post-refinement, and a global-local keyframe selection strategy to maximize reconstruction completeness and fidelity. Our system autonomously explores and reconstructs environments with state-of-the-art geometric and photometric accuracy and completeness, significantly surpassing existing approaches in both aspects. Extensive evaluations on benchmark datasets such as Replica and MP3D highlight ActiveGAMER's effectiveness in active mapping tasks.
Dialogue Director: Bridging the Gap in Dialogue Visualization for Multimodal Storytelling
Dec 30, 2024



Recent advances in AI-driven storytelling have enhanced video generation and story visualization. However, translating dialogue-centric scripts into coherent storyboards remains a significant challenge due to limited script detail, inadequate physical context understanding, and the complexity of integrating cinematic principles. To address these challenges, we propose Dialogue Visualization, a novel task that transforms dialogue scripts into dynamic, multi-view storyboards. We introduce Dialogue Director, a training-free multimodal framework comprising a Script Director, Cinematographer, and Storyboard Maker. This framework leverages large multimodal models and diffusion-based architectures, employing techniques such as Chain-of-Thought reasoning, Retrieval-Augmented Generation, and multi-view synthesis to improve script understanding, physical context comprehension, and cinematic knowledge integration. Experimental results demonstrate that Dialogue Director outperforms state-of-the-art methods in script interpretation, physical world understanding, and cinematic principle application, significantly advancing the quality and controllability of dialogue-based story visualization.
Flash3D: Super-scaling Point Transformers through Joint Hardware-Geometry Locality
Dec 21, 2024Recent efforts recognize the power of scale in 3D learning (e.g. PTv3) and attention mechanisms (e.g. FlashAttention). However, current point cloud backbones fail to holistically unify geometric locality, attention mechanisms, and GPU architectures in one view. In this paper, we introduce Flash3D Transformer, which aligns geometric locality and GPU tiling through a principled locality mechanism based on Perfect Spatial Hashing (PSH). The common alignment with GPU tiling naturally fuses our PSH locality mechanism with FlashAttention at negligible extra cost. This mechanism affords flexible design choices throughout the backbone that result in superior downstream task results. Flash3D outperforms state-of-the-art PTv3 results on benchmark datasets, delivering a 2.25x speed increase and 2.4x memory efficiency boost. This efficiency enables scaling to wider attention scopes and larger models without additional overhead. Such scaling allows Flash3D to achieve even higher task accuracies than PTv3 under the same compute budget.
Audio-driven High-resolution Seamless Talking Head Video Editing via StyleGAN
Jul 08, 2024



The existing methods for audio-driven talking head video editing have the limitations of poor visual effects. This paper tries to tackle this problem through editing talking face images seamless with different emotions based on two modules: (1) an audio-to-landmark module, consisting of the CrossReconstructed Emotion Disentanglement and an alignment network module. It bridges the gap between speech and facial motions by predicting corresponding emotional landmarks from speech; (2) a landmark-based editing module edits face videos via StyleGAN. It aims to generate the seamless edited video consisting of the emotion and content components from the input audio. Extensive experiments confirm that compared with state-of-the-arts methods, our method provides high-resolution videos with high visual quality.
4DRecons: 4D Neural Implicit Deformable Objects Reconstruction from a single RGB-D Camera with Geometrical and Topological Regularizations
Jun 14, 2024



This paper presents a novel approach 4DRecons that takes a single camera RGB-D sequence of a dynamic subject as input and outputs a complete textured deforming 3D model over time. 4DRecons encodes the output as a 4D neural implicit surface and presents an optimization procedure that combines a data term and two regularization terms. The data term fits the 4D implicit surface to the input partial observations. We address fundamental challenges in fitting a complete implicit surface to partial observations. The first regularization term enforces that the deformation among adjacent frames is as rigid as possible (ARAP). To this end, we introduce a novel approach to compute correspondences between adjacent textured implicit surfaces, which are used to define the ARAP regularization term. The second regularization term enforces that the topology of the underlying object remains fixed over time. This regularization is critical for avoiding self-intersections that are typical in implicit-based reconstructions. We have evaluated the performance of 4DRecons on a variety of datasets. Experimental results show that 4DRecons can handle large deformations and complex inter-part interactions and outperform state-of-the-art approaches considerably.
DNPM: A Neural Parametric Model for the Synthesis of Facial Geometric Details
May 30, 2024



Parametric 3D models have enabled a wide variety of computer vision and graphics tasks, such as modeling human faces, bodies and hands. In 3D face modeling, 3DMM is the most widely used parametric model, but can't generate fine geometric details solely from identity and expression inputs. To tackle this limitation, we propose a neural parametric model named DNPM for the facial geometric details, which utilizes deep neural network to extract latent codes from facial displacement maps encoding details and wrinkles. Built upon DNPM, a novel 3DMM named Detailed3DMM is proposed, which augments traditional 3DMMs by including the synthesis of facial details only from the identity and expression inputs. Moreover, we show that DNPM and Detailed3DMM can facilitate two downstream applications: speech-driven detailed 3D facial animation and 3D face reconstruction from a degraded image. Extensive experiments have shown the usefulness of DNPM and Detailed3DMM, and the progressiveness of two proposed applications.
Learning the Distribution of Errors in Stereo Matching for Joint Disparity and Uncertainty Estimation
Mar 31, 2023



We present a new loss function for joint disparity and uncertainty estimation in deep stereo matching. Our work is motivated by the need for precise uncertainty estimates and the observation that multi-task learning often leads to improved performance in all tasks. We show that this can be achieved by requiring the distribution of uncertainty to match the distribution of disparity errors via a KL divergence term in the network's loss function. A differentiable soft-histogramming technique is used to approximate the distributions so that they can be used in the loss. We experimentally assess the effectiveness of our approach and observe significant improvements in both disparity and uncertainty prediction on large datasets.
How likely is a random graph shift-enabled?
Aug 28, 2021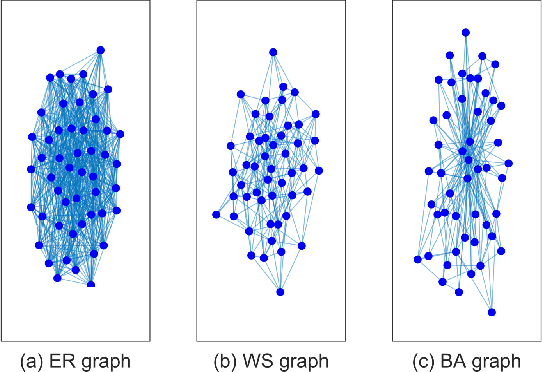
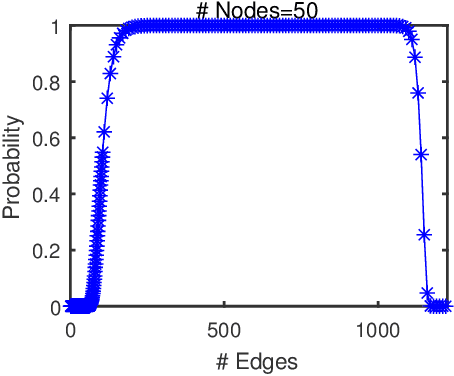
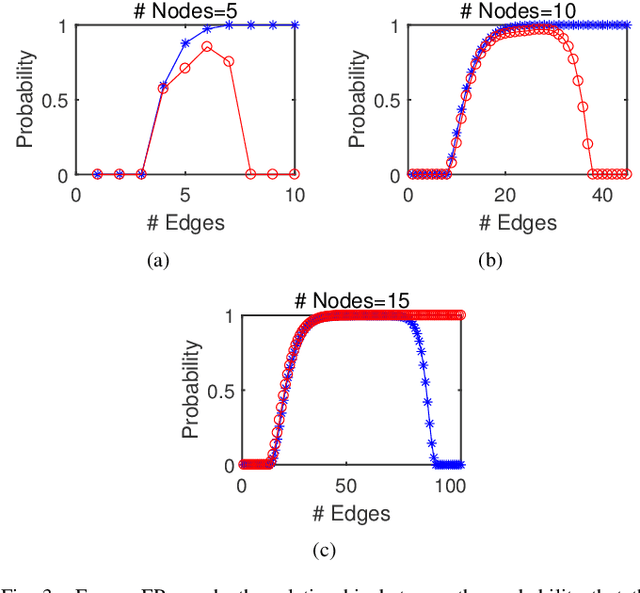
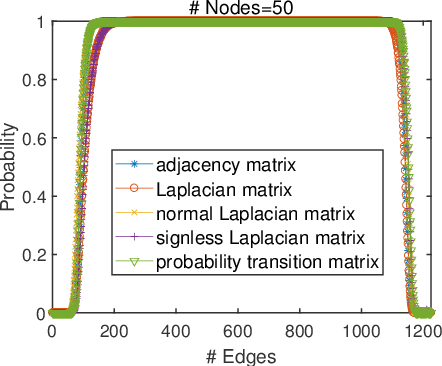
The shift-enabled property of an underlying graph is essential in designing distributed filters. This article discusses when a random graph is shift-enabled. In particular, popular graph models ER, WS, BA random graph are used, weighted and unweighted, as well as signed graphs. Our results show that the considered unweighted connected random graphs are shift-enabled with high probability when the number of edges is moderately high. However, very dense graphs, as well as fully connected graphs, are not shift-enabled. Interestingly, this behaviour is not observed for weighted connected graphs, which are always shift-enabled unless the number of edges in the graph is very low.
Improving VQA and its Explanations \\ by Comparing Competing Explanations
Jun 28, 2020
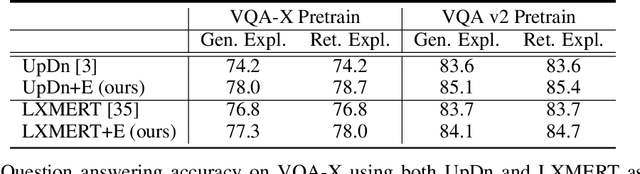
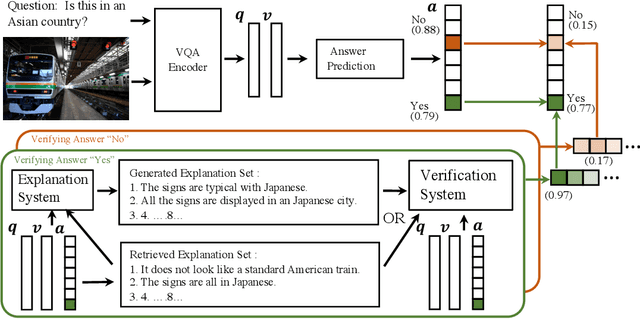

Most recent state-of-the-art Visual Question Answering (VQA) systems are opaque black boxes that are only trained to fit the answer distribution given the question and visual content. As a result, these systems frequently take shortcuts, focusing on simple visual concepts or question priors. This phenomenon becomes more problematic as the questions become complex that requires more reasoning and commonsense knowledge. To address this issue, we present a novel framework that uses explanations for competing answers to help VQA systems select the correct answer. By training on human textual explanations, our framework builds better representations for the questions and visual content, and then reweights confidences in the answer candidates using either generated or retrieved explanations from the training set. We evaluate our framework on the VQA-X dataset, which has more difficult questions with human explanations, achieving new state-of-the-art results on both VQA and its explanations.