 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Director: Bridging the Gap in Dialogue Visualization for Multimodal Storytelling
Dec 30, 2024



Recent advances in AI-driven storytelling have enhanced video generation and story visualization. However, translating dialogue-centric scripts into coherent storyboards remains a significant challenge due to limited script detail, inadequate physical context understanding, and the complexity of integrating cinematic principles. To address these challenges, we propose Dialogue Visualization, a novel task that transforms dialogue scripts into dynamic, multi-view storyboards. We introduce Dialogue Director, a training-free multimodal framework comprising a Script Director, Cinematographer, and Storyboard Maker. This framework leverages large multimodal models and diffusion-based architectures, employing techniques such as Chain-of-Thought reasoning, Retrieval-Augmented Generation, and multi-view synthesis to improve script understanding, physical context comprehension, and cinematic knowledge integration. Experimental results demonstrate that Dialogue Director outperforms state-of-the-art methods in script interpretation, physical world understanding, and cinematic principle application, significantly advancing the quality and controllability of dialogue-based story visualization.
Audio-driven High-resolution Seamless Talking Head Video Editing via StyleGAN
Jul 08, 2024



The existing methods for audio-driven talking head video editing have the limitations of poor visual effects. This paper tries to tackle this problem through editing talking face images seamless with different emotions based on two modules: (1) an audio-to-landmark module, consisting of the CrossReconstructed Emotion Disentanglement and an alignment network module. It bridges the gap between speech and facial motions by predicting corresponding emotional landmarks from speech; (2) a landmark-based editing module edits face videos via StyleGAN. It aims to generate the seamless edited video consisting of the emotion and content components from the input audio. Extensive experiments confirm that compared with state-of-the-arts methods, our method provides high-resolution videos with high visual quality.
Emo-DNA: Emotion Decoupling and Alignment Learning for Cross-Corpus Speech Emotion Recognition
Aug 04, 2023



Cross-corpus speech emotion recognition (SER) seeks to generalize the ability of inferring speech emotion from a well-labeled corpus to an unlabeled one, which is a rather challenging task due to the significant discrepancy between two corpora. Existing methods, typically based on unsupervised domain adaptation (UDA), struggle to learn corpus-invariant features by global distribution alignment, but unfortunately, the resulting features are mixed with corpus-specific features or not class-discriminative. To tackle these challenges, we propose a novel Emotion Decoupling aNd Alignment learning framework (EMO-DNA) for cross-corpus SER, a novel UDA method to learn emotion-relevant corpus-invariant features. The novelties of EMO-DNA are two-fold: contrastive emotion decoupling and dual-level emotion alignment. On one hand, our contrastive emotion decoupling achieves decoupling learning via a contrastive decoupling loss to strengthen the separability of emotion-relevant features from corpus-specific ones. On the other hand, our dual-level emotion alignment introduces an adaptive threshold pseudo-labeling to select confident target samples for class-level alignment, and performs corpus-level alignment to jointly guide model for learning class-discriminative corpus-invariant features across corpora. Extensive experimental results demonstrate the superior performance of EMO-DNA over the state-of-the-art methods in several cross-corpus scenarios. Source code is available at https://github.com/Jiaxin-Ye/Emo-DNA.
Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition
Nov 14, 2022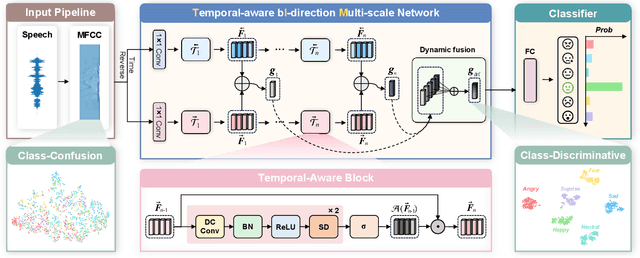
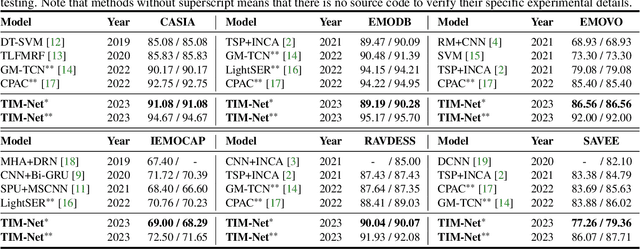
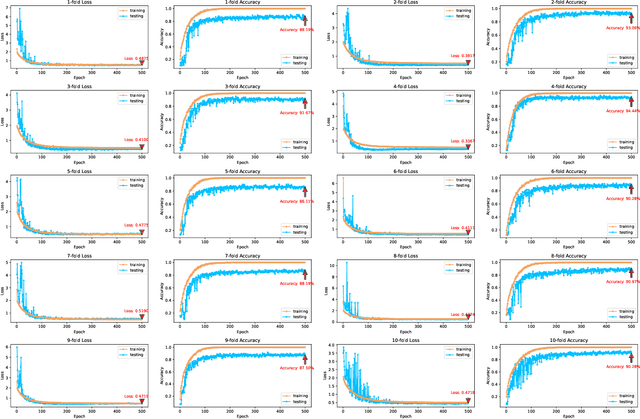

Speech emotion recognition (SER) plays a vital role in improving the interactions between humans and machines by inferring human emotion and affective states from speech signals. Whereas recent works primarily focus on mining spatiotemporal information from hand-crafted features, we explore how to model the temporal patterns of speech emotions from dynamic temporal scales. Towards that goal, we introduce a novel temporal emotional modeling approach for SER, termed Temporal-aware bI-direction Multi-scale Network (TIM-Net), which learns multi-scale contextual affective representations from various time scales. Specifically, TIM-Net first employs temporal-aware blocks to learn temporal affective representation, then integrates complementary information from the past and the future to enrich contextual representations, and finally, fuses multiple time scale features for better adaptation to the emotional variation. Extensive experimental results on six benchmark SER datasets demonstrate the superior performance of TIM-Net, gaining 2.34% and 2.61% improvements of the average UAR and WAR over the second-best on each corpus. Remarkably, TIM-Net outperforms the latest domain-adaptation method on the cross-corpus SER tasks, demonstrating strong generalizability.
A Novel ECOC Algorithm with Centroid Distance Based Soft Coding Scheme
Jun 22, 2018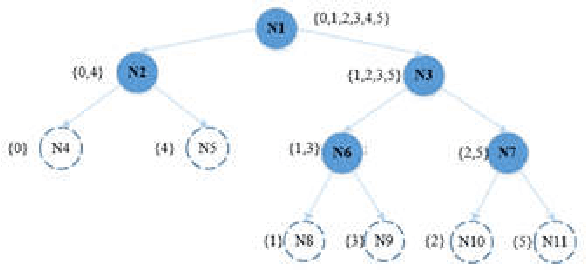
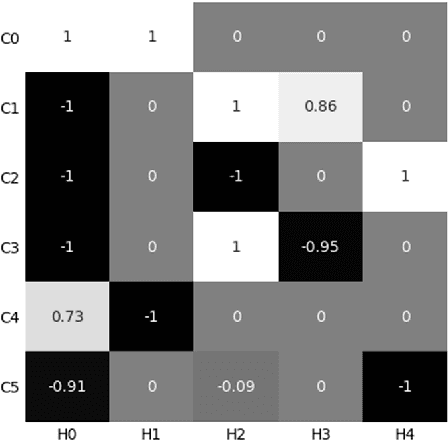
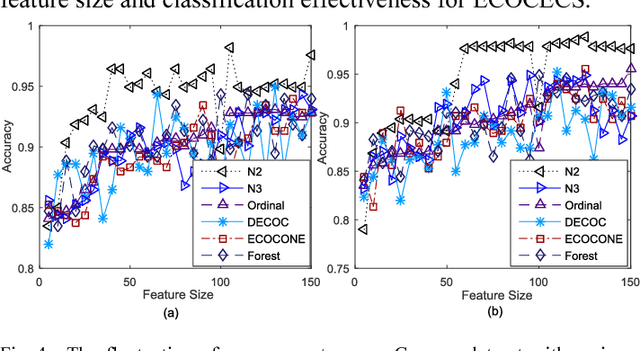
In ECOC framework, the ternary coding strategy is widely deployed in coding process. It relabels classes with {"-1,0,1" }, where -1/1 means to assign the corresponding classes to the negative/positive group, and label 0 leads to ignore the corresponding classes in the training process. However, the application of hard labels may lose some information about the tendency of class distributions. Instead, we propose a Centroid distance-based Soft coding scheme to indicate such tendency, named as CSECOC. In our algorithm, Sequential Forward Floating Selection (SFFS) is applied to search an optimal class assignment by minimizing the ratio of intra-group and inter-group distance. In this way, a hard coding matrix is generated initially. Then we propose a measure, named as coverage, to describe the probability of a sample in a class falling to a correct group. The coverage of a class a group replace the corresponding hard element, so as to form a soft coding matrix. Compared with the hard ones, such soft elements can reflect the tendency of a class belonging to positive or negative group. Instead of classifiers, regressors are used as base learners in this algorithm. To the best of our knowledge, it is the first time that soft coding scheme has been proposed. The results on five UCI datasets show that compared with some state-of-art ECOC algorithms, our algorithm can produce comparable or better classification accuracy with small scale ensembles.
A New ECOC Algorithm for Multiclass Microarray Data Classification
Jun 22, 2018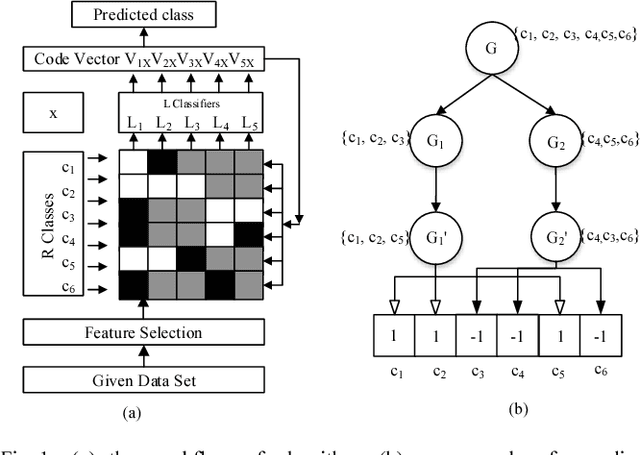

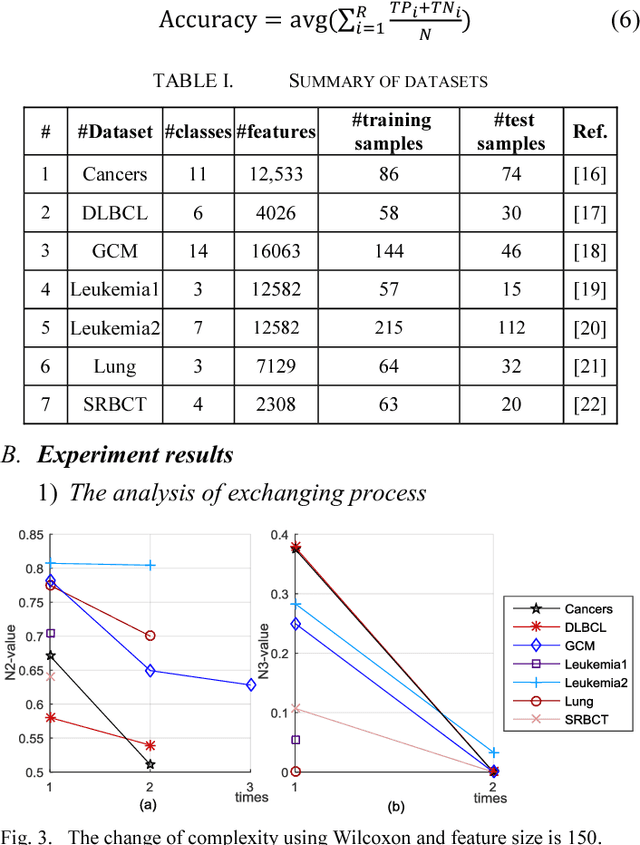
The classification of multi-class microarray datasets is a hard task because of the small samples size in each class and the heavy overlaps among classes. To effectively solve these problems, we propose novel Error Correcting Output Code (ECOC) algorithm by Enhance Class Separability related Data Complexity measures during encoding process, named as ECOCECS. In this algorithm, two nearest neighbor related DC measures are deployed to extract the intrinsic overlapping information from microarray data. Our ECOC algorithm aims to search an optimal class split scheme by minimizing these measures. The class splitting process ends when each class is separated from others, and then the class assignment scheme is mapped as a coding matrix. Experiments are carried out on five microarray datasets, and results demonstrate the effectiveness and robustness of our method in comparison with six state-of-art ECOC methods. In short, our work confirm the probability of applying DC to ECOC framework.