 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Object Re-Identification via Visual In-Context Prompting
Aug 28, 2025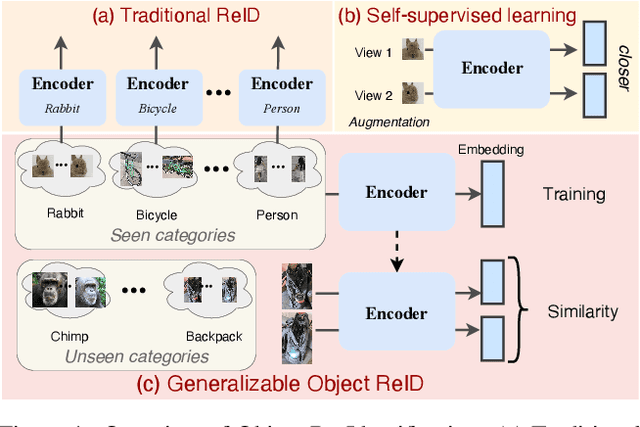
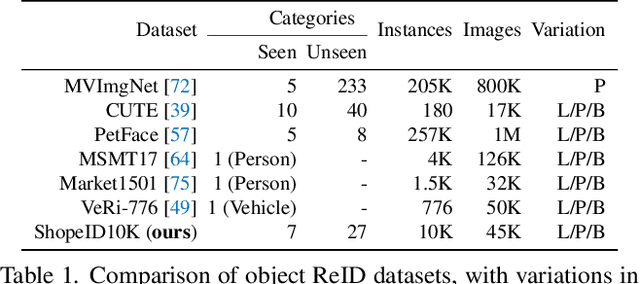
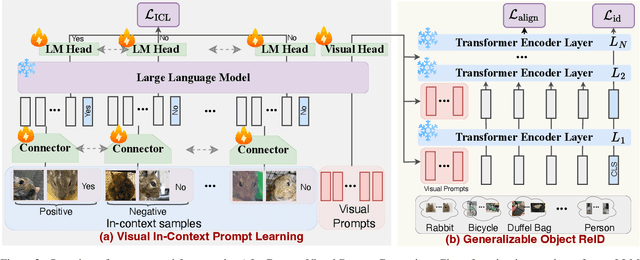
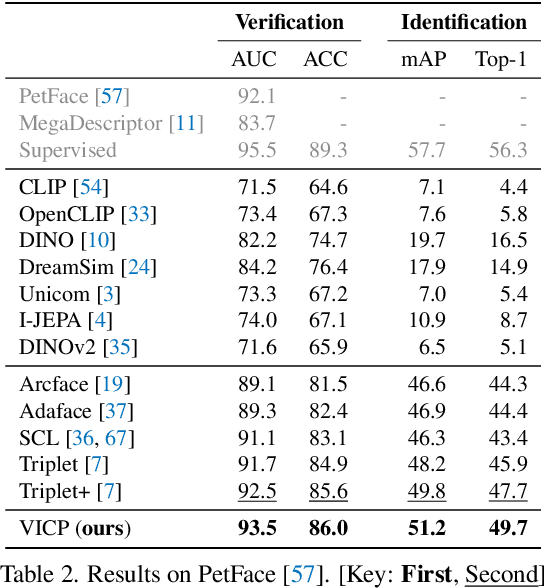
Current object re-identification (ReID) methods train domain-specific models (e.g., for persons or vehicles), which lack generalization and demand costly labeled data for new categories. While self-supervised learning reduces annotation needs by learning instance-wise invariance, it struggles to capture \textit{identity-sensitive} features critical for ReID. This paper proposes Visual In-Context Prompting~(VICP), a novel framework where models trained on seen categories can directly generalize to unseen novel categories using only \textit{in-context examples} as prompts, without requiring parameter adaptation. VICP synergizes LLMs and vision foundation models~(VFM): LLMs infer semantic identity rules from few-shot positive/negative pairs through task-specific prompting, which then guides a VFM (\eg, DINO) to extract ID-discriminative features via \textit{dynamic visual prompts}. By aligning LLM-derived semantic concepts with the VFM's pre-trained prior, VICP enables generalization to novel categories, eliminating the need for dataset-specific retraining. To support evaluation, we introduce ShopID10K, a dataset of 10K object instances from e-commerce platforms, featuring multi-view images and cross-domain testing. Experiments on ShopID10K and diverse ReID benchmarks demonstrate that VICP outperforms baselines by a clear margin on unseen categories. Code is available at https://github.com/Hzzone/VICP.
DreamVideo-2: Zero-Shot Subject-Driven Video Customization with Precise Motion Control
Oct 17, 2024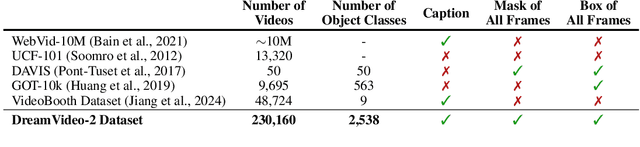
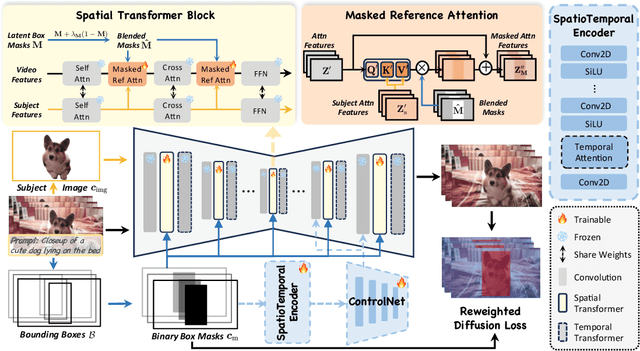


Recent advances in customized video generation have enabled users to create videos tailored to both specific subjects and motion trajectories. However, existing methods often require complicated test-time fine-tuning and struggle with balancing subject learning and motion control, limiting their real-world applications. In this paper, we present DreamVideo-2, a zero-shot video customization framework capable of generating videos with a specific subject and motion trajectory, guided by a single image and a bounding box sequence, respectively, and without the need for test-time fine-tuning. Specifically, we introduce reference attention, which leverages the model's inherent capabilities for subject learning, and devise a mask-guided motion module to achieve precise motion control by fully utilizing the robust motion signal of box masks derived from bounding boxes. While these two components achieve their intended functions, we empirically observe that motion control tends to dominate over subject learning. To address this, we propose two key designs: 1) the masked reference attention, which integrates a blended latent mask modeling scheme into reference attention to enhance subject representations at the desired positions, and 2) a reweighted diffusion loss, which differentiates the contributions of regions inside and outside the bounding boxes to ensure a balance between subject and motion control. Extensive experimental results on a newly curated dataset demonstrate that DreamVideo-2 outperforms state-of-the-art methods in both subject customization and motion control. The dataset, code, and models will be made publicly available.
FLDM-VTON: Faithful Latent Diffusion Model for Virtual Try-on
Apr 22, 2024Despite their impressive generative performance, latent diffusion model-based virtual try-on (VTON) methods lack faithfulness to crucial details of the clothes, such as style, pattern, and text. To alleviate these issues caused by the diffusion stochastic nature and latent supervision, we propose a novel Faithful Latent Diffusion Model for VTON, termed FLDM-VTON. FLDM-VTON improves the conventional latent diffusion process in three major aspects. First, we propose incorporating warped clothes as both the starting point and local condition, supplying the model with faithful clothes priors. Second, we introduce a novel clothes flattening network to constrain generated try-on images, providing clothes-consistent faithful supervision. Third, we devise a clothes-posterior sampling for faithful inference, further enhancing the model performance over conventional clothes-agnostic Gaussian sampling. Extensive experimental results on the benchmark VITON-HD and Dress Code datasets demonstrate that our FLDM-VTON outperforms state-of-the-art baselines and is able to generate photo-realistic try-on images with faithful clothing details.
Point, Segment and Count: A Generalized Framework for Object Counting
Nov 27, 2023Class-agnostic object counting aims to count all objects in an image with respect to example boxes or class names, \emph{a.k.a} few-shot and zero-shot counting. Current state-of-the-art methods highly rely on density maps to predict object counts, which lacks model interpretability. In this paper, we propose a generalized framework for both few-shot and zero-shot object counting based on detection. Our framework combines the superior advantages of two foundation models without compromising their zero-shot capability: (\textbf{i}) SAM to segment all possible objects as mask proposals, and (\textbf{ii}) CLIP to classify proposals to obtain accurate object counts. However, this strategy meets the obstacles of efficiency overhead and the small crowded objects that cannot be localized and distinguished. To address these issues, our framework, termed PseCo, follows three steps: point, segment, and count. Specifically, we first propose a class-agnostic object localization to provide accurate but least point prompts for SAM, which consequently not only reduces computation costs but also avoids missing small objects. Furthermore, we propose a generalized object classification that leverages CLIP image/text embeddings as the classifier, following a hierarchical knowledge distillation to obtain discriminative classifications among hierarchical mask proposals. Extensive experimental results on FSC-147 dataset demonstrate that PseCo achieves state-of-the-art performance in both few-shot/zero-shot object counting/detection, with additional results on large-scale COCO and LVIS datasets. The source code is available at \url{https://github.com/Hzzone/PseCo}.
Semantic Latent Decomposition with Normalizing Flows for Face Editing
Sep 11, 2023Navigating in the latent space of StyleGAN has shown effectiveness for face editing. However, the resulting methods usually encounter challenges in complicated navigation due to the entanglement among different attributes in the latent space. To address this issue, this paper proposes a novel framework, termed SDFlow, with a semantic decomposition in original latent space using continuous conditional normalizing flows. Specifically, SDFlow decomposes the original latent code into different irrelevant variables by jointly optimizing two components: (i) a semantic encoder to estimate semantic variables from input faces and (ii) a flow-based transformation module to map the latent code into a semantic-irrelevant variable in Gaussian distribution, conditioned on the learned semantic variables. To eliminate the entanglement between variables, we employ a disentangled learning strategy under a mutual information framework, thereby providing precise manipulation controls. Experimental results demonstrate that SDFlow outperforms existing state-of-the-art face editing methods both qualitatively and quantitatively. The source code is made available at https://github.com/phil329/SDFlow.
Emo-DNA: Emotion Decoupling and Alignment Learning for Cross-Corpus Speech Emotion Recognition
Aug 04, 2023



Cross-corpus speech emotion recognition (SER) seeks to generalize the ability of inferring speech emotion from a well-labeled corpus to an unlabeled one, which is a rather challenging task due to the significant discrepancy between two corpora. Existing methods, typically based on unsupervised domain adaptation (UDA), struggle to learn corpus-invariant features by global distribution alignment, but unfortunately, the resulting features are mixed with corpus-specific features or not class-discriminative. To tackle these challenges, we propose a novel Emotion Decoupling aNd Alignment learning framework (EMO-DNA) for cross-corpus SER, a novel UDA method to learn emotion-relevant corpus-invariant features. The novelties of EMO-DNA are two-fold: contrastive emotion decoupling and dual-level emotion alignment. On one hand, our contrastive emotion decoupling achieves decoupling learning via a contrastive decoupling loss to strengthen the separability of emotion-relevant features from corpus-specific ones. On the other hand, our dual-level emotion alignment introduces an adaptive threshold pseudo-labeling to select confident target samples for class-level alignment, and performs corpus-level alignment to jointly guide model for learning class-discriminative corpus-invariant features across corpora. Extensive experimental results demonstrate the superior performance of EMO-DNA over the state-of-the-art methods in several cross-corpus scenarios. Source code is available at https://github.com/Jiaxin-Ye/Emo-DNA.
Online Prototype Learning for Online Continual Learning
Aug 01, 2023Online continual learning (CL) studies the problem of learning continuously from a single-pass data stream while adapting to new data and mitigating catastrophic forgetting. Recently, by storing a small subset of old data, replay-based methods have shown promising performance. Unlike previous methods that focus on sample storage or knowledge distillation against catastrophic forgetting, this paper aims to understand why the online learning models fail to generalize well from a new perspective of shortcut learning. We identify shortcut learning as the key limiting factor for online CL, where the learned features may be biased, not generalizable to new tasks, and may have an adverse impact on knowledge distillation. To tackle this issue, we present the online prototype learning (OnPro) framework for online CL. First, we propose online prototype equilibrium to learn representative features against shortcut learning and discriminative features to avoid class confusion, ultimately achieving an equilibrium status that separates all seen classes well while learning new classes. Second, with the feedback of online prototypes, we devise a novel adaptive prototypical feedback mechanism to sense the classes that are easily misclassified and then enhance their boundaries. Extensive experimental results on widely-used benchmark datasets demonstrate the superior performance of OnPro over the state-of-the-art baseline methods. Source code is available at https://github.com/weilllllls/OnPro.
Adaptive Nonlinear Latent Transformation for Conditional Face Editing
Jul 15, 2023Recent works for face editing usually manipulate the latent space of StyleGAN via the linear semantic directions. However, they usually suffer from the entanglement of facial attributes, need to tune the optimal editing strength, and are limited to binary attributes with strong supervision signals. This paper proposes a novel adaptive nonlinear latent transformation for disentangled and conditional face editing, termed AdaTrans. Specifically, our AdaTrans divides the manipulation process into several finer steps; i.e., the direction and size at each step are conditioned on both the facial attributes and the latent codes. In this way, AdaTrans describes an adaptive nonlinear transformation trajectory to manipulate the faces into target attributes while keeping other attributes unchanged. Then, AdaTrans leverages a predefined density model to constrain the learned trajectory in the distribution of latent codes by maximizing the likelihood of transformed latent code. Moreover, we also propose a disentangled learning strategy under a mutual information framework to eliminate the entanglement among attributes, which can further relax the need for labeled data. Consequently, AdaTrans enables a controllable face editing with the advantages of disentanglement, flexibility with non-binary attributes, and high fidelity. Extensive experimental results on various facial attributes demonstrate the qualitative and quantitative effectiveness of the proposed AdaTrans over existing state-of-the-art methods, especially in the most challenging scenarios with a large age gap and few labeled examples. The source code is available at https://github.com/Hzzone/AdaTrans.
Cross-head Supervision for Crowd Counting with Noisy Annotations
Mar 16, 2023
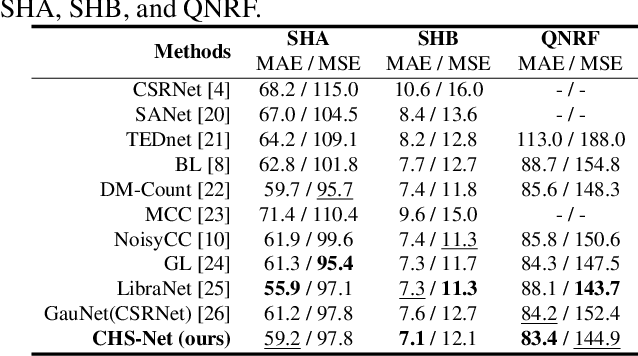
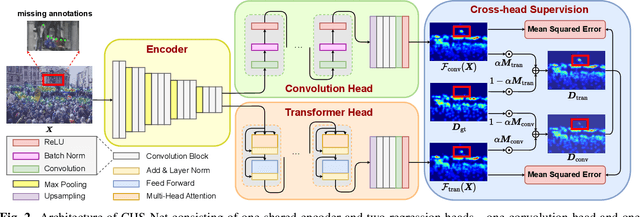

Noisy annotations such as missing annotations and location shifts often exist in crowd counting datasets due to multi-scale head sizes, high occlusion, etc. These noisy annotations severely affect the model training, especially for density map-based methods. To alleviate the negative impact of noisy annotations, we propose a novel crowd counting model with one convolution head and one transformer head, in which these two heads can supervise each other in noisy areas, called Cross-Head Supervision. The resultant model, CHS-Net, can synergize different types of inductive biases for better counting. In addition, we develop a progressive cross-head supervision learning strategy to stabilize the training process and provide more reliable supervision. Extensive experimental results on ShanghaiTech and QNRF datasets demonstrate superior performance over state-of-the-art methods. Code is available at https://github.com/RaccoonDML/CHSNet.
Twin Contrastive Learning with Noisy Labels
Mar 13, 2023Learning from noisy data is a challenging task that significantly degenerates the model performance. In this paper, we present TCL, a novel twin contrastive learning model to learn robust representations and handle noisy labels for classification. Specifically, we construct a Gaussian mixture model (GMM) over the representations by injecting the supervised model predictions into GMM to link label-free latent variables in GMM with label-noisy annotations. Then, TCL detects the examples with wrong labels as the out-of-distribution examples by another two-component GMM, taking into account the data distribution. We further propose a cross-supervision with an entropy regularization loss that bootstraps the true targets from model predictions to handle the noisy labels. As a result, TCL can learn discriminative representations aligned with estimated labels through mixup and contrastive learning. Extensive experimental results on several standard benchmarks and real-world datasets demonstrate the superior performance of TCL. In particular, TCL achieves 7.5\% improvements on CIFAR-10 with 90\% noisy label -- an extremely noisy scenario. The source code is available at \url{https://github.com/Hzzone/TCL}.