 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexSim2Real$^{2}$: Building Explicit World Model for Precise Articulated Object Dexterous Manipulation
Sep 13, 2024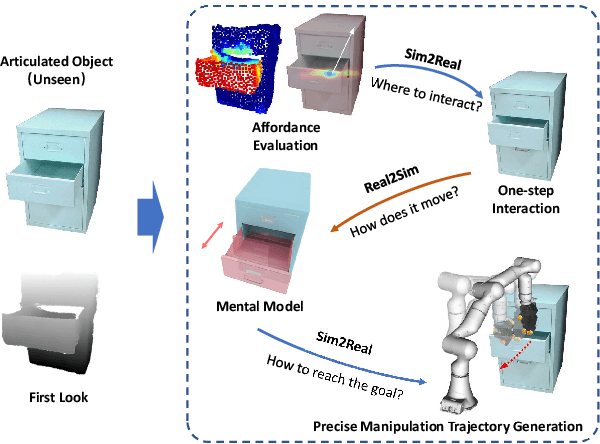

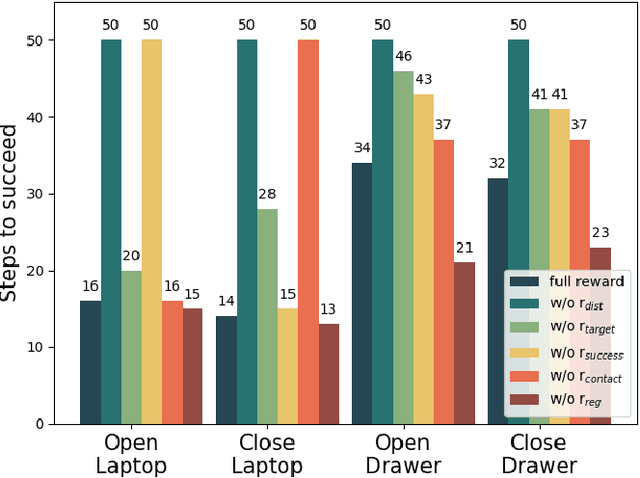
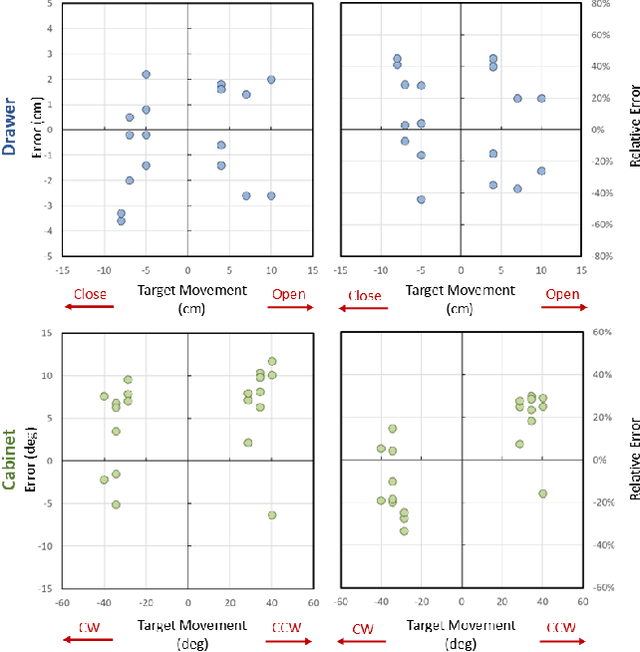
Articulated object manipulation is ubiquitous in daily life. In this paper, we present DexSim2Real$^{2}$, a novel robot learning framework for goal-conditioned articulated object manipulation using both two-finger grippers and multi-finger dexterous hands. The key of our framework is constructing an explicit world model of unseen articulated objects through active one-step interactions. This explicit world model enables sampling-based model predictive control to plan trajectories achieving different manipulation goals without needing human demonstrations or reinforcement learning. It first predicts an interaction motion using an affordance estimation network trained on self-supervised interaction data or videos of human manipulation from the internet. After executing this interaction on the real robot, the framework constructs a digital twin of the articulated object in simulation based on the two point clouds before and after the interaction. For dexterous multi-finger manipulation, we propose to utilize eigengrasp to reduce the high-dimensional action space, enabling more efficient trajectory searching. Extensive experiments validate the framework's effectiveness for precise articulated object manipulation in both simulation and the real world using a two-finger gripper and a 16-DoF dexterous hand. The robust generalizability of the explicit world model also enables advanced manipulation strategies, such as manipulating with different tools.
FLDM-VTON: Faithful Latent Diffusion Model for Virtual Try-on
Apr 22, 2024Despite their impressive generative performance, latent diffusion model-based virtual try-on (VTON) methods lack faithfulness to crucial details of the clothes, such as style, pattern, and text. To alleviate these issues caused by the diffusion stochastic nature and latent supervision, we propose a novel Faithful Latent Diffusion Model for VTON, termed FLDM-VTON. FLDM-VTON improves the conventional latent diffusion process in three major aspects. First, we propose incorporating warped clothes as both the starting point and local condition, supplying the model with faithful clothes priors. Second, we introduce a novel clothes flattening network to constrain generated try-on images, providing clothes-consistent faithful supervision. Third, we devise a clothes-posterior sampling for faithful inference, further enhancing the model performance over conventional clothes-agnostic Gaussian sampling. Extensive experimental results on the benchmark VITON-HD and Dress Code datasets demonstrate that our FLDM-VTON outperforms state-of-the-art baselines and is able to generate photo-realistic try-on images with faithful clothing details.
We Choose to Go to Space: Agent-driven Human and Multi-Robot Collaboration in Microgravity
Feb 22, 2024



We present SpaceAgents-1, a system for learning human and multi-robot collaboration (HMRC) strategies under microgravity conditions. Future space exploration requires humans to work together with robots. However, acquiring proficient robot skills and adept collaboration under microgravity conditions poses significant challenges within ground laboratories. To address this issue, we develop a microgravity simulation environment and present three typical configurations of intra-cabin robots. We propose a hierarchical heterogeneous multi-agent collaboration architecture: guided by foundation models, a Decision-Making Agent serves as a task planner for human-robot collaboration, while individual Skill-Expert Agents manage the embodied control of robots. This mechanism empowers the SpaceAgents-1 system to execute a range of intricate long-horizon HMRC tasks.