 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
Oct 29, 2025Visual effects (VFX) are crucial to the expressive power of digital media, yet their creation remains a major challenge for generative AI. Prevailing methods often rely on the one-LoRA-per-effect paradigm, which is resource-intensive and fundamentally incapable of generalizing to unseen effects, thus limiting scalability and creation. To address this challenge, we introduce VFXMaster, the first unified, reference-based framework for VFX video generation. It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content. In addition, it demonstrates remarkable generalization to unseen effect categories. Specifically, we design an in-context conditioning strategy that prompts the model with a reference example. An in-context attention mask is designed to precisely decouple and inject the essential effect attributes, allowing a single unified model to master the effect imitation without information leakage. In addition, we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly. Extensive experiments demonstrate that our method effectively imitates various categories of effect information and exhibits outstanding generalization to out-of-domain effects. To foster future research, we will release our code, models, and a comprehensive dataset to the community.
CCL-LGS: Contrastive Codebook Learning for 3D Language Gaussian Splatting
May 26, 2025



Recent advances in 3D reconstruction techniques and vision-language models have fueled significant progress in 3D semantic understanding, a capability critical to robotics, autonomous driving, and virtual/augmented reality. However, methods that rely on 2D priors are prone to a critical challenge: cross-view semantic inconsistencies induced by occlusion, image blur, and view-dependent variations. These inconsistencies, when propagated via projection supervision, deteriorate the quality of 3D Gaussian semantic fields and introduce artifacts in the rendered outputs. To mitigate this limitation, we propose CCL-LGS, a novel framework that enforces view-consistent semantic supervision by integrating multi-view semantic cues. Specifically, our approach first employs a zero-shot tracker to align a set of SAM-generated 2D masks and reliably identify their corresponding categories. Next, we utilize CLIP to extract robust semantic encodings across views. Finally, our Contrastive Codebook Learning (CCL) module distills discriminative semantic features by enforcing intra-class compactness and inter-class distinctiveness. In contrast to previous methods that directly apply CLIP to imperfect masks, our framework explicitly resolves semantic conflicts while preserving category discriminability. Extensive experiments demonstrate that CCL-LGS outperforms previous state-of-the-art methods. Our project page is available at https://epsilontl.github.io/CCL-LGS/.
Towards Physically Plausible Video Generation via VLM Planning
Mar 30, 2025Video diffusion models (VDMs) have advanced significantly in recent years, enabling the generation of highly realistic videos and drawing the attention of the community in their potential as world simulators. However, despite their capabilities, VDMs often fail to produce physically plausible videos due to an inherent lack of understanding of physics, resulting in incorrect dynamics and event sequences. To address this limitation, we propose a novel two-stage image-to-video generation framework that explicitly incorporates physics. In the first stage, we employ a Vision Language Model (VLM) as a coarse-grained motion planner, integrating chain-of-thought and physics-aware reasoning to predict a rough motion trajectories/changes that approximate real-world physical dynamics while ensuring the inter-frame consistency. In the second stage, we use the predicted motion trajectories/changes to guide the video generation of a VDM. As the predicted motion trajectories/changes are rough, noise is added during inference to provide freedom to the VDM in generating motion with more fine details. Extensive experimental results demonstrate that our framework can produce physically plausible motion, and comparative evaluations highlight the notable superiority of our approach over existing methods. More video results are available on our Project Page: https://madaoer.github.io/projects/physically_plausible_video_generation.
Bootstraping Clustering of Gaussians for View-consistent 3D Scene Understanding
Nov 29, 2024Injecting semantics into 3D Gaussian Splatting (3DGS) has recently garnered significant attention. While current approaches typically distill 3D semantic features from 2D foundational models (e.g., CLIP and SAM) to facilitate novel view segmentation and semantic understanding, their heavy reliance on 2D supervision can undermine cross-view semantic consistency and necessitate complex data preparation processes, therefore hindering view-consistent scene understanding. In this work, we present FreeGS, an unsupervised semantic-embedded 3DGS framework that achieves view-consistent 3D scene understanding without the need for 2D labels. Instead of directly learning semantic features, we introduce the IDentity-coupled Semantic Field (IDSF) into 3DGS, which captures both semantic representations and view-consistent instance indices for each Gaussian. We optimize IDSF with a two-step alternating strategy: semantics help to extract coherent instances in 3D space, while the resulting instances regularize the injection of stable semantics from 2D space. Additionally, we adopt a 2D-3D joint contrastive loss to enhance the complementarity between view-consistent 3D geometry and rich semantics during the bootstrapping process, enabling FreeGS to uniformly perform tasks such as novel-view semantic segmentation, object selection, and 3D object detection. Extensive experiments on LERF-Mask, 3D-OVS, and ScanNet datasets demonstrate that FreeGS performs comparably to state-of-the-art methods while avoiding the complex data preprocessing workload.
DreamMix: Decoupling Object Attributes for Enhanced Editability in Customized Image Inpainting
Nov 26, 2024Subject-driven image inpainting has emerged as a popular task in image editing alongside recent advancements in diffusion models. Previous methods primarily focus on identity preservation but struggle to maintain the editability of inserted objects. In response, this paper introduces DreamMix, a diffusion-based generative model adept at inserting target objects into given scenes at user-specified locations while concurrently enabling arbitrary text-driven modifications to their attributes. In particular, we leverage advanced foundational inpainting models and introduce a disentangled local-global inpainting framework to balance precise local object insertion with effective global visual coherence. Additionally, we propose an Attribute Decoupling Mechanism (ADM) and a Textual Attribute Substitution (TAS) module to improve the diversity and discriminative capability of the text-based attribute guidance, respectively. Extensive experiments demonstrate that DreamMix effectively balances identity preservation and attribute editability across various application scenarios, including object insertion, attribute editing, and small object inpainting. Our code is publicly available at https://github.com/mycfhs/DreamMix.
DexSim2Real$^{2}$: Building Explicit World Model for Precise Articulated Object Dexterous Manipulation
Sep 13, 2024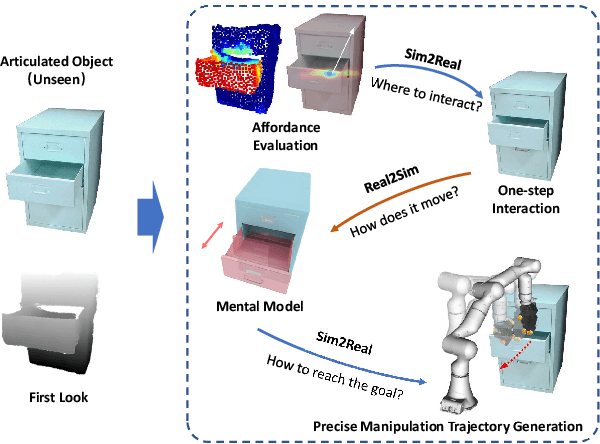

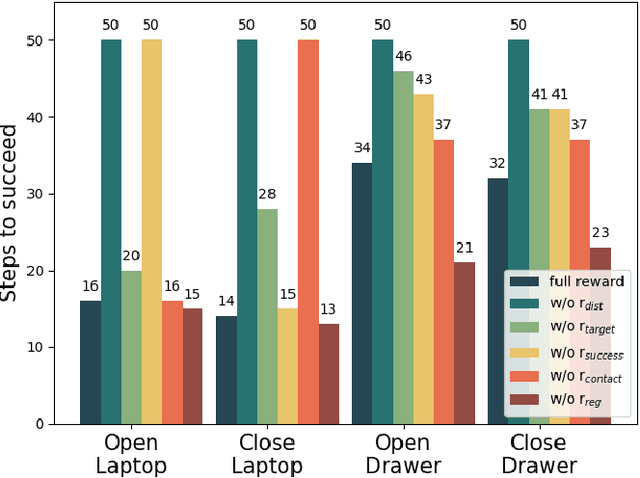
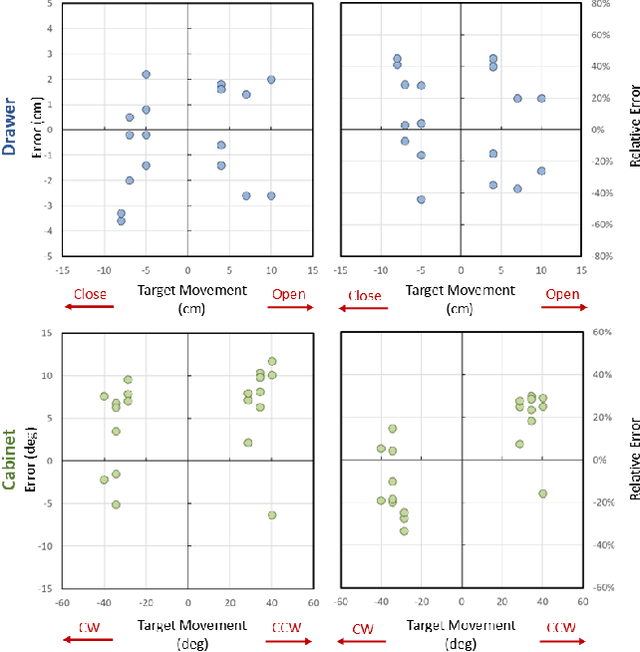
Articulated object manipulation is ubiquitous in daily life. In this paper, we present DexSim2Real$^{2}$, a novel robot learning framework for goal-conditioned articulated object manipulation using both two-finger grippers and multi-finger dexterous hands. The key of our framework is constructing an explicit world model of unseen articulated objects through active one-step interactions. This explicit world model enables sampling-based model predictive control to plan trajectories achieving different manipulation goals without needing human demonstrations or reinforcement learning. It first predicts an interaction motion using an affordance estimation network trained on self-supervised interaction data or videos of human manipulation from the internet. After executing this interaction on the real robot, the framework constructs a digital twin of the articulated object in simulation based on the two point clouds before and after the interaction. For dexterous multi-finger manipulation, we propose to utilize eigengrasp to reduce the high-dimensional action space, enabling more efficient trajectory searching. Extensive experiments validate the framework's effectiveness for precise articulated object manipulation in both simulation and the real world using a two-finger gripper and a 16-DoF dexterous hand. The robust generalizability of the explicit world model also enables advanced manipulation strategies, such as manipulating with different tools.
Meta-Control: Automatic Model-based Control Synthesis for Heterogeneous Robot Skills
May 18, 2024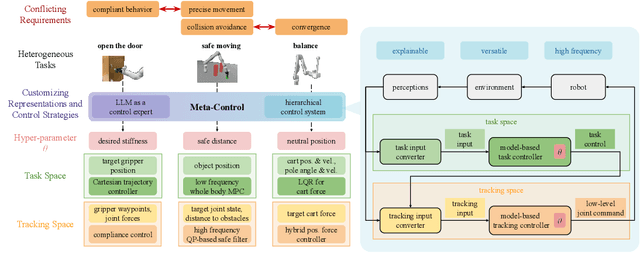
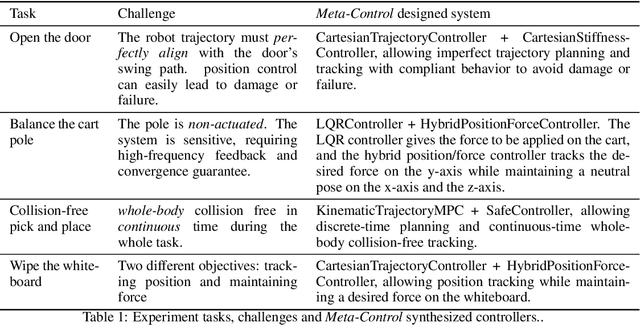
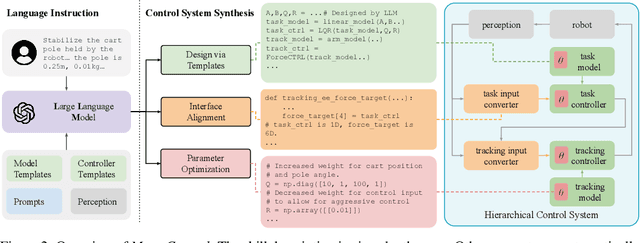
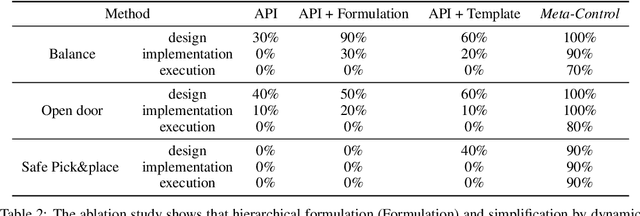
The requirements for real-world manipulation tasks are diverse and often conflicting; some tasks necessitate force constraints or collision avoidance, while others demand high-frequency feedback. Satisfying these varied requirements with a fixed state-action representation and control strategy is challenging, impeding the development of a universal robotic foundation model. In this work, we propose Meta-Control, the first LLM-enabled automatic control synthesis approach that creates customized state representations and control strategies tailored to specific tasks. Meta-Control leverages a generic hierarchical control framework to address a wide range of heterogeneous tasks. Our core insight is the decomposition of the state space into an abstract task space and a concrete tracking space. By harnessing LLM's extensive common sense and control knowledge, we enable the LLM to design these spaces, including states, dynamic models, and controllers, using pre-defined but abstract templates. Meta-Control stands out for its fully model-based nature, allowing for rigorous analysis, efficient parameter tuning, and reliable execution. It not only utilizes decades of control expertise encapsulated within LLMs to facilitate heterogeneous control but also ensures formal guarantees such as safety and stability. Our method is validated both in real-world scenarios and simulations across diverse tasks with conflicting requirements, such as collision avoidance versus convergence and compliance versus high precision. Videos and additional results are at meta-control-paper.github.io
CharacterFactory: Sampling Consistent Characters with GANs for Diffusion Models
Apr 27, 2024



Recent advances in text-to-image models have opened new frontiers in human-centric generation. However, these models cannot be directly employed to generate images with consistent newly coined identities. In this work, we propose CharacterFactory, a framework that allows sampling new characters with consistent identities in the latent space of GANs for diffusion models. More specifically, we consider the word embeddings of celeb names as ground truths for the identity-consistent generation task and train a GAN model to learn the mapping from a latent space to the celeb embedding space. In addition, we design a context-consistent loss to ensure that the generated identity embeddings can produce identity-consistent images in various contexts. Remarkably, the whole model only takes 10 minutes for training, and can sample infinite characters end-to-end during inference. Extensive experiments demonstrate excellent performance of the proposed CharacterFactory on character creation in terms of identity consistency and editability. Furthermore, the generated characters can be seamlessly combined with the off-the-shelf image/video/3D diffusion models. We believe that the proposed CharacterFactory is an important step for identity-consistent character generation. Project page is available at: https://qinghew.github.io/CharacterFactory/.
StableIdentity: Inserting Anybody into Anywhere at First Sight
Jan 29, 2024Recent advances in large pretrained text-to-image models have shown unprecedented capabilities for high-quality human-centric generation, however, customizing face identity is still an intractable problem. Existing methods cannot ensure stable identity preservation and flexible editability, even with several images for each subject during training. In this work, we propose StableIdentity, which allows identity-consistent recontextualization with just one face image. More specifically, we employ a face encoder with an identity prior to encode the input face, and then land the face representation into a space with an editable prior, which is constructed from celeb names. By incorporating identity prior and editability prior, the learned identity can be injected anywhere with various contexts. In addition, we design a masked two-phase diffusion loss to boost the pixel-level perception of the input face and maintain the diversity of generation. Extensive experiments demonstrate our method outperforms previous customization methods. In addition, the learned identity can be flexibly combined with the off-the-shelf modules such as ControlNet. Notably, to the best knowledge, we are the first to directly inject the identity learned from a single image into video/3D generation without finetuning. We believe that the proposed StableIdentity is an important step to unify image, video, and 3D customized generation models.
Magicremover: Tuning-free Text-guided Image inpainting with Diffusion Models
Oct 04, 2023Image inpainting aims to fill in the missing pixels with visually coherent and semantically plausible content. Despite the great progress brought from deep generative models, this task still suffers from i. the difficulties in large-scale realistic data collection and costly model training; and ii. the intrinsic limitations in the traditionally user-defined binary masks on objects with unclear boundaries or transparent texture. In this paper, we propose MagicRemover, a tuning-free method that leverages the powerful diffusion models for text-guided image inpainting. We introduce an attention guidance strategy to constrain the sampling process of diffusion models, enabling the erasing of instructed areas and the restoration of occluded content. We further propose a classifier optimization algorithm to facilitate the denoising stability within less sampling steps. Extensive comparisons are conducted among our MagicRemover and state-of-the-art methods including quantitative evaluation and user study, demonstrating the significant improvement of MagicRemover on high-quality image inpainting. We will release our code at https://github.com/exisas/Magicremover.