 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl Invariant Sets for Neural Network Dynamical Systems and Recursive Feasibility in Model Predictive Control
May 15, 2025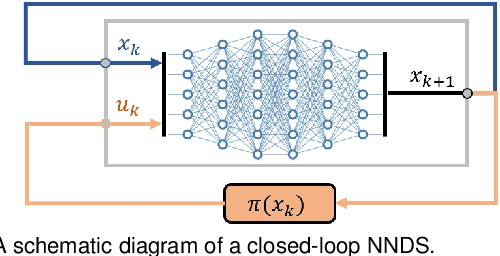
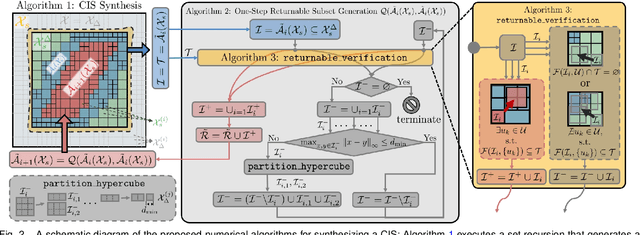
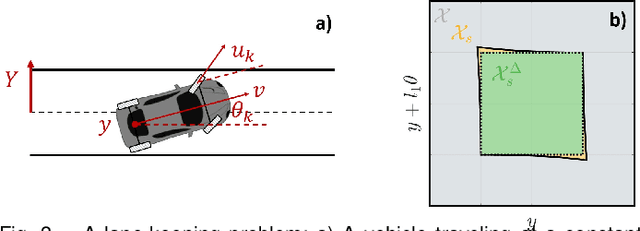
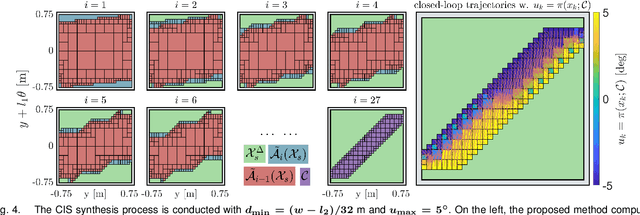
Neural networks are powerful tools for data-driven modeling of complex dynamical systems, enhancing predictive capability for control applications. However, their inherent nonlinearity and black-box nature challenge control designs that prioritize rigorous safety and recursive feasibility guarantees. This paper presents algorithmic methods for synthesizing control invariant sets specifically tailored to neural network based dynamical models. These algorithms employ set recursion, ensuring termination after a finite number of iterations and generating subsets in which closed-loop dynamics are forward invariant, thus guaranteeing perpetual operational safety. Additionally, we propose model predictive control designs that integrate these control invariant sets into mixed-integer optimization, with guaranteed adherence to safety constraints and recursive feasibility at the computational level. We also present a comprehensive theoretical analysis examining the properties and guarantees of the proposed methods. Numerical simulations in an autonomous driving scenario demonstrate the methods' effectiveness in synthesizing control-invariant sets offline and implementing model predictive control online, ensuring safety and recursive feasibility.
Absolute State-wise Constrained Policy Optimization: High-Probability State-wise Constraints Satisfaction
Oct 02, 2024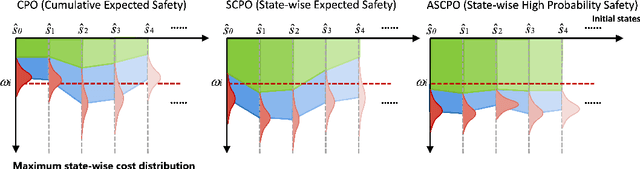


Enforcing state-wise safety constraints is critical for the application of reinforcement learning (RL) in real-world problems, such as autonomous driving and robot manipulation. However, existing safe RL methods only enforce state-wise constraints in expectation or enforce hard state-wise constraints with strong assumptions. The former does not exclude the probability of safety violations, while the latter is impractical. Our insight is that although it is intractable to guarantee hard state-wise constraints in a model-free setting, we can enforce state-wise safety with high probability while excluding strong assumptions. To accomplish the goal, we propose Absolute State-wise Constrained Policy Optimization (ASCPO), a novel general-purpose policy search algorithm that guarantees high-probability state-wise constraint satisfaction for stochastic systems. We demonstrate the effectiveness of our approach by training neural network policies for extensive robot locomotion tasks, where the agent must adhere to various state-wise safety constraints. Our results show that ASCPO significantly outperforms existing methods in handling state-wise constraints across challenging continuous control tasks, highlighting its potential for real-world applications.
WeHelp: A Shared Autonomy System for Wheelchair Users
Sep 19, 2024

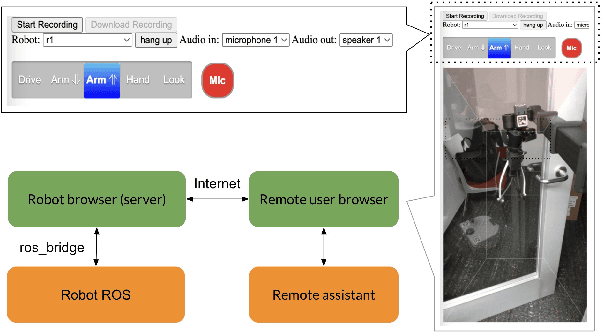

There is a large population of wheelchair users. Most of the wheelchair users need help with daily tasks. However, according to recent reports, their needs are not properly satisfied due to the lack of caregivers. Therefore, in this project, we develop WeHelp, a shared autonomy system aimed for wheelchair users. A robot with a WeHelp system has three modes, following mode, remote control mode and tele-operation mode. In the following mode, the robot follows the wheelchair user automatically via visual tracking. The wheelchair user can ask the robot to follow them from behind, by the left or by the right. When the wheelchair user asks for help, the robot will recognize the command via speech recognition, and then switch to the teleoperation mode or remote control mode. In the teleoperation mode, the wheelchair user takes over the robot with a joy stick and controls the robot to complete some complex tasks for their needs, such as opening doors, moving obstacles on the way, reaching objects on a high shelf or on the low ground, etc. In the remote control mode, a remote assistant takes over the robot and helps the wheelchair user complete some complex tasks for their needs. Our evaluation shows that the pipeline is useful and practical for wheelchair users. Source code and demo of the paper are available at \url{https://github.com/Walleclipse/WeHelp}.
Certifying Robustness of Learning-Based Keypoint Detection and Pose Estimation Methods
Jul 31, 2024



This work addresses the certification of the local robustness of vision-based two-stage 6D object pose estimation. The two-stage method for object pose estimation achieves superior accuracy by first employing deep neural network-driven keypoint regression and then applying a Perspective-n-Point (PnP) technique. Despite advancements, the certification of these methods' robustness remains scarce. This research aims to fill this gap with a focus on their local robustness on the system level--the capacity to maintain robust estimations amidst semantic input perturbations. The core idea is to transform the certification of local robustness into neural network verification for classification tasks. The challenge is to develop model, input, and output specifications that align with off-the-shelf verification tools. To facilitate verification, we modify the keypoint detection model by substituting nonlinear operations with those more amenable to the verification processes. Instead of injecting random noise into images, as is common, we employ a convex hull representation of images as input specifications to more accurately depict semantic perturbations. Furthermore, by conducting a sensitivity analysis, we propagate the robustness criteria from pose to keypoint accuracy, and then formulating an optimal error threshold allocation problem that allows for the setting of a maximally permissible keypoint deviation thresholds. Viewing each pixel as an individual class, these thresholds result in linear, classification-akin output specifications. Under certain conditions, we demonstrate that the main components of our certification framework are both sound and complete, and validate its effects through extensive evaluations on realistic perturbations. To our knowledge, this is the first study to certify the robustness of large-scale, keypoint-based pose estimation given images in real-world scenarios.
ModelVerification.jl: a Comprehensive Toolbox for Formally Verifying Deep Neural Networks
Jun 30, 2024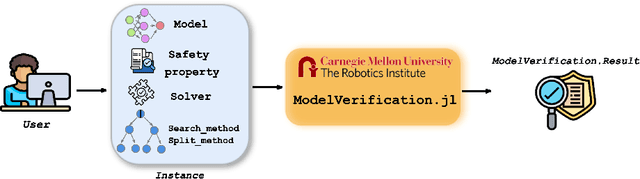

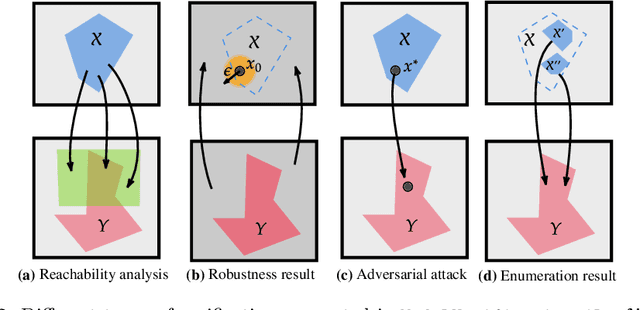
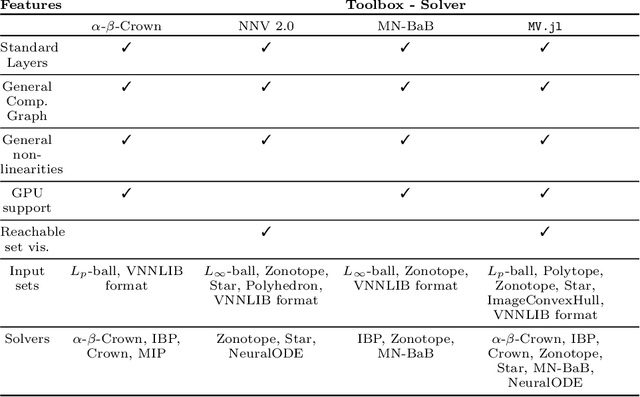
Deep Neural Networks (DNN) are crucial in approximating nonlinear functions across diverse applications, ranging from image classification to control. Verifying specific input-output properties can be a highly challenging task due to the lack of a single, self-contained framework that allows a complete range of verification types. To this end, we present \texttt{ModelVerification.jl (MV)}, the first comprehensive, cutting-edge toolbox that contains a suite of state-of-the-art methods for verifying different types of DNNs and safety specifications. This versatile toolbox is designed to empower developers and machine learning practitioners with robust tools for verifying and ensuring the trustworthiness of their DNN models.
Meta-Control: Automatic Model-based Control Synthesis for Heterogeneous Robot Skills
May 18, 2024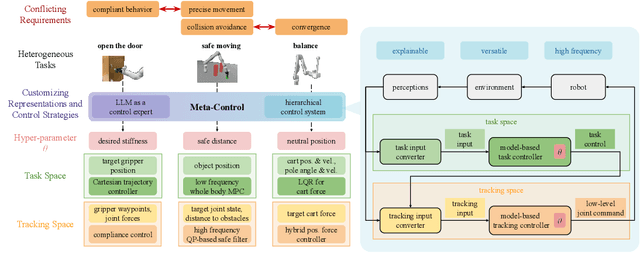
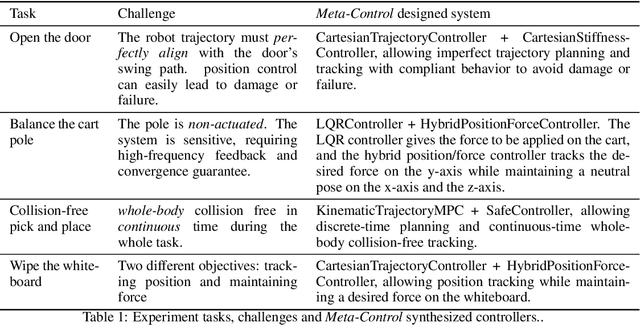
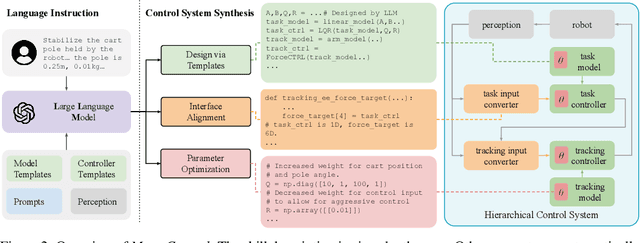
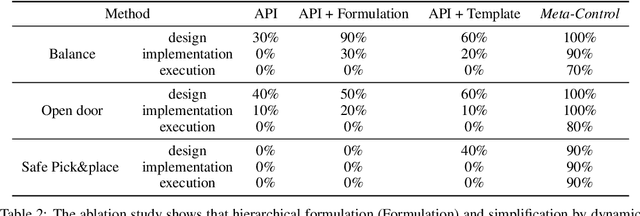
The requirements for real-world manipulation tasks are diverse and often conflicting; some tasks necessitate force constraints or collision avoidance, while others demand high-frequency feedback. Satisfying these varied requirements with a fixed state-action representation and control strategy is challenging, impeding the development of a universal robotic foundation model. In this work, we propose Meta-Control, the first LLM-enabled automatic control synthesis approach that creates customized state representations and control strategies tailored to specific tasks. Meta-Control leverages a generic hierarchical control framework to address a wide range of heterogeneous tasks. Our core insight is the decomposition of the state space into an abstract task space and a concrete tracking space. By harnessing LLM's extensive common sense and control knowledge, we enable the LLM to design these spaces, including states, dynamic models, and controllers, using pre-defined but abstract templates. Meta-Control stands out for its fully model-based nature, allowing for rigorous analysis, efficient parameter tuning, and reliable execution. It not only utilizes decades of control expertise encapsulated within LLMs to facilitate heterogeneous control but also ensures formal guarantees such as safety and stability. Our method is validated both in real-world scenarios and simulations across diverse tasks with conflicting requirements, such as collision avoidance versus convergence and compliance versus high precision. Videos and additional results are at meta-control-paper.github.io
Multimodal Safe Control for Human-Robot Interaction
Nov 20, 2023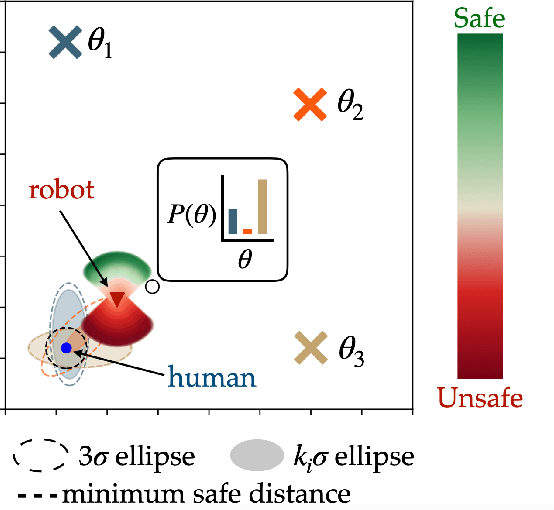
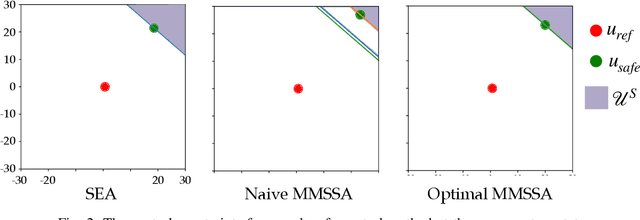
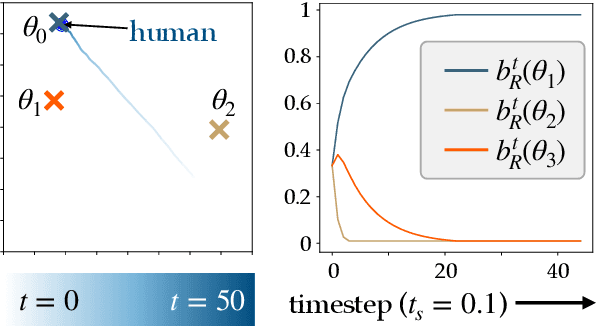
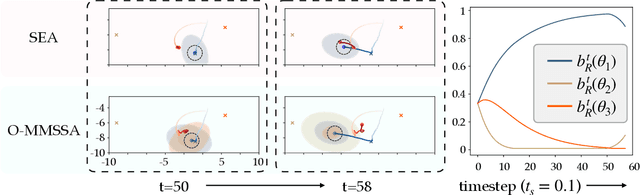
Generating safe behaviors for autonomous systems is important as they continue to be deployed in the real world, especially around people. In this work, we focus on developing a novel safe controller for systems where there are multiple sources of uncertainty. We formulate a novel multimodal safe control method, called the Multimodal Safe Set Algorithm (MMSSA) for the case where the agent has uncertainty over which discrete mode the system is in, and each mode itself contains additional uncertainty. To our knowledge, this is the first energy-function-based safe control method applied to systems with multimodal uncertainty. We apply our controller to a simulated human-robot interaction where the robot is uncertain of the human's true intention and each potential intention has its own additional uncertainty associated with it, since the human is not a perfectly rational actor. We compare our proposed safe controller to existing safe control methods and find that it does not impede the system performance (i.e. efficiency) while also improving the safety of the system.
Absolute Policy Optimization
Oct 20, 2023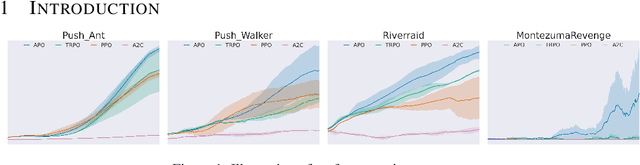

In recent years, trust region on-policy reinforcement learning has achieved impressive results in addressing complex control tasks and gaming scenarios. However, contemporary state-of-the-art algorithms within this category primarily emphasize improvement in expected performance, lacking the ability to control over the worst-case performance outcomes. To address this limitation, we introduce a novel objective function; by optimizing which, it will lead to guaranteed monotonic improvement in the lower bound of near-total performance samples (absolute performance). Considering this groundbreaking theoretical advancement, we then refine this theoretically grounded algorithm through a series of approximations, resulting in a practical solution called Absolute Policy Optimization (APO). Our experiments demonstrate the effectiveness of our approach across challenging continuous control benchmark tasks and extend its applicability to mastering Atari games. Our findings reveal that APO significantly outperforms state-of-the-art policy gradient algorithms, resulting in substantial improvements in both expected performance and worst-case performance.
Robust Safe Control with Multi-Modal Uncertainty
Sep 28, 2023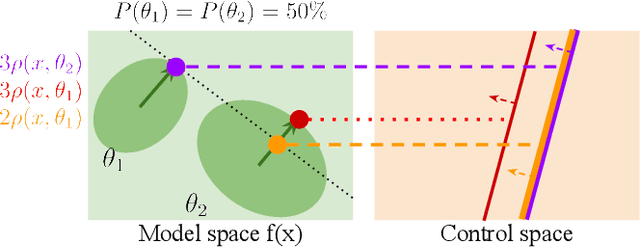
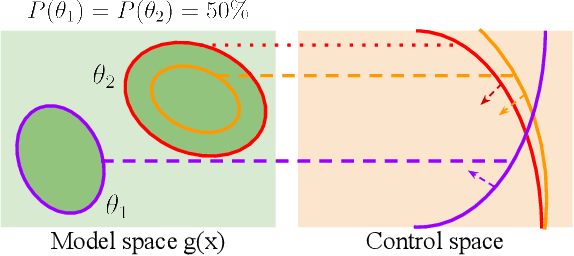
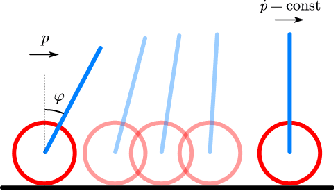
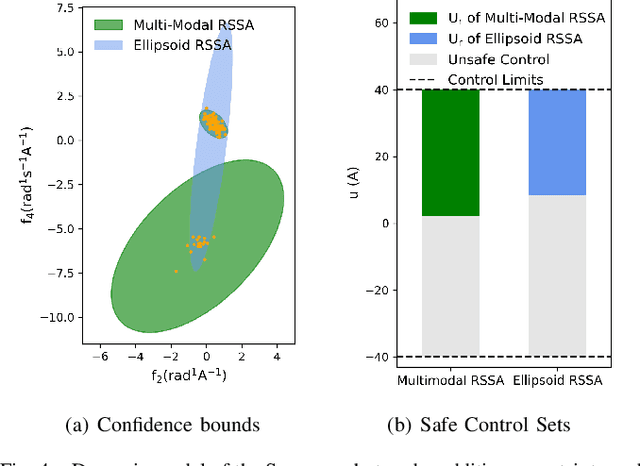
Safety in dynamic systems with prevalent uncertainties is crucial. Current robust safe controllers, designed primarily for uni-modal uncertainties, may be either overly conservative or unsafe when handling multi-modal uncertainties. To address the problem, we introduce a novel framework for robust safe control, tailored to accommodate multi-modal Gaussian dynamics uncertainties and control limits. We first present an innovative method for deriving the least conservative robust safe control under additive multi-modal uncertainties. Next, we propose a strategy to identify a locally least-conservative robust safe control under multiplicative uncertainties. Following these, we introduce a unique safety index synthesis method. This provides the foundation for a robust safe controller that ensures a high probability of realizability under control limits and multi-modal uncertainties. Experiments on a simulated Segway validate our approach, showing consistent realizability and less conservatism than controllers designed using uni-modal uncertainty methods. The framework offers significant potential for enhancing safety and performance in robotic applications.
Learn With Imagination: Safe Set Guided State-wise Constrained Policy Optimization
Aug 25, 2023Deep reinforcement learning (RL) excels in various control tasks, yet the absence of safety guarantees hampers its real-world applicability. In particular, explorations during learning usually results in safety violations, while the RL agent learns from those mistakes. On the other hand, safe control techniques ensure persistent safety satisfaction but demand strong priors on system dynamics, which is usually hard to obtain in practice. To address these problems, we present Safe Set Guided State-wise Constrained Policy Optimization (S-3PO), a pioneering algorithm generating state-wise safe optimal policies with zero training violations, i.e., learning without mistakes. S-3PO first employs a safety-oriented monitor with black-box dynamics to ensure safe exploration. It then enforces a unique cost for the RL agent to converge to optimal behaviors within safety constraints. S-3PO outperforms existing methods in high-dimensional robotics tasks, managing state-wise constraints with zero training violation. This innovation marks a significant stride towards real-world safe RL deployment.