 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbsolute State-wise Constrained Policy Optimization: High-Probability State-wise Constraints Satisfaction
Paper and Code
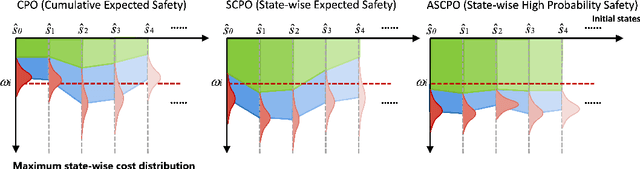


Enforcing state-wise safety constraints is critical for the application of reinforcement learning (RL) in real-world problems, such as autonomous driving and robot manipulation. However, existing safe RL methods only enforce state-wise constraints in expectation or enforce hard state-wise constraints with strong assumptions. The former does not exclude the probability of safety violations, while the latter is impractical. Our insight is that although it is intractable to guarantee hard state-wise constraints in a model-free setting, we can enforce state-wise safety with high probability while excluding strong assumptions. To accomplish the goal, we propose Absolute State-wise Constrained Policy Optimization (ASCPO), a novel general-purpose policy search algorithm that guarantees high-probability state-wise constraint satisfaction for stochastic systems. We demonstrate the effectiveness of our approach by training neural network policies for extensive robot locomotion tasks, where the agent must adhere to various state-wise safety constraints. Our results show that ASCPO significantly outperforms existing methods in handling state-wise constraints across challenging continuous control tasks, highlighting its potential for real-world applications.