 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole-Body Safe Control of Robotic Systems with Koopman Neural Dynamics
Mar 05, 2026Controlling robots with strongly nonlinear, high-dimensional dynamics remains challenging, as direct nonlinear optimization with safety constraints is often intractable in real time. The Koopman operator offers a way to represent nonlinear systems linearly in a lifted space, enabling the use of efficient linear control. We propose a data-driven framework that learns a Koopman embedding and operator from data, and integrates the resulting linear model with the Safe Set Algorithm (SSA). This allows the tracking and safety constraints to be solved in a single quadratic program (QP), ensuring feasibility and optimality without a separate safety filter. We validate the method on a Kinova Gen3 manipulator and a Go2 quadruped, showing accurate tracking and obstacle avoidance.
Scaling Law of Neural Koopman Operators
Feb 23, 2026Data-driven neural Koopman operator theory has emerged as a powerful tool for linearizing and controlling nonlinear robotic systems. However, the performance of these data-driven models fundamentally depends on the trade-off between sample size and model dimensions, a relationship for which the scaling laws have remained unclear. This paper establishes a rigorous framework to address this challenge by deriving and empirically validating scaling laws that connect sample size, latent space dimension, and downstream control quality. We derive a theoretical upper bound on the Koopman approximation error, explicitly decomposing it into sampling error and projection error. We show that these terms decay at specific rates relative to dataset size and latent dimension, providing a rigorous basis for the scaling law. Based on the theoretical results, we introduce two lightweight regularizers for the neural Koopman operator: a covariance loss to help stabilize the learned latent features and an inverse control loss to ensure the model aligns with physical actuation. The results from systematic experiments across six robotic environments confirm that model fitting error follows the derived scaling laws, and the regularizers improve dynamic model fitting fidelity, with enhanced closed-loop control performance. Together, our results provide a simple recipe for allocating effort between data collection and model capacity when learning Koopman dynamics for control.
Deployable and Generalizable Motion Prediction: Taxonomy, Open Challenges and Future Directions
May 14, 2025



Motion prediction, the anticipation of future agent states or scene evolution, is rooted in human cognition, bridging perception and decision-making. It enables intelligent systems, such as robots and self-driving cars, to act safely in dynamic, human-involved environments, and informs broader time-series reasoning challenges. With advances in methods, representations, and datasets, the field has seen rapid progress, reflected in quickly evolving benchmark results. Yet, when state-of-the-art methods are deployed in the real world, they often struggle to generalize to open-world conditions and fall short of deployment standards. This reveals a gap between research benchmarks, which are often idealized or ill-posed, and real-world complexity. To address this gap, this survey revisits the generalization and deployability of motion prediction models, with an emphasis on the applications of robotics, autonomous driving, and human motion. We first offer a comprehensive taxonomy of motion prediction methods, covering representations, modeling strategies, application domains, and evaluation protocols. We then study two key challenges: (1) how to push motion prediction models to be deployable to realistic deployment standards, where motion prediction does not act in a vacuum, but functions as one module of closed-loop autonomy stacks - it takes input from the localization and perception, and informs downstream planning and control. 2) how to generalize motion prediction models from limited seen scenarios/datasets to the open-world settings. Throughout the paper, we highlight critical open challenges to guide future work, aiming to recalibrate the community's efforts, fostering progress that is not only measurable but also meaningful for real-world applications.
Enhancing Sample Generation of Diffusion Models using Noise Level Correction
Dec 07, 2024

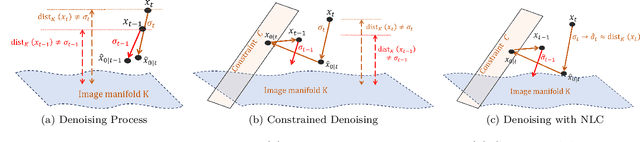
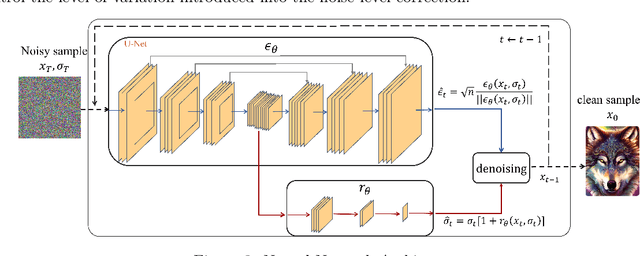
The denoising process of diffusion models can be interpreted as a projection of noisy samples onto the data manifold. Moreover, the noise level in these samples approximates their distance to the underlying manifold. Building on this insight, we propose a novel method to enhance sample generation by aligning the estimated noise level with the true distance of noisy samples to the manifold. Specifically, we introduce a noise level correction network, leveraging a pre-trained denoising network, to refine noise level estimates during the denoising process. Additionally, we extend this approach to various image restoration tasks by integrating task-specific constraints, including inpainting, deblurring, super-resolution, colorization, and compressed sensing. Experimental results demonstrate that our method significantly improves sample quality in both unconstrained and constrained generation scenarios. Notably, the proposed noise level correction framework is compatible with existing denoising schedulers (e.g., DDIM), offering additional performance improvements.
Revisiting the Initial Steps in Adaptive Gradient Descent Optimization
Dec 03, 2024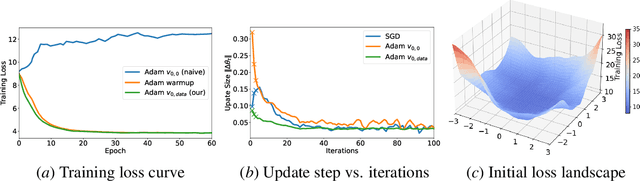

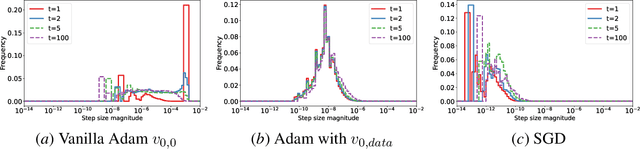

Adaptive gradient optimization methods, such as Adam, are prevalent in training deep neural networks across diverse machine learning tasks due to their ability to achieve faster convergence. However, these methods often suffer from suboptimal generalization compared to stochastic gradient descent (SGD) and exhibit instability, particularly when training Transformer models. In this work, we show the standard initialization of the second-order moment estimation ($v_0 =0$) as a significant factor contributing to these limitations. We introduce simple yet effective solutions: initializing the second-order moment estimation with non-zero values, using either data-driven or random initialization strategies. Empirical evaluations demonstrate that our approach not only stabilizes convergence but also enhances the final performance of adaptive gradient optimizers. Furthermore, by adopting the proposed initialization strategies, Adam achieves performance comparable to many recently proposed variants of adaptive gradient optimization methods, highlighting the practical impact of this straightforward modification.
Robustifying Long-term Human-Robot Collaboration through a Hierarchical and Multimodal Framework
Nov 24, 2024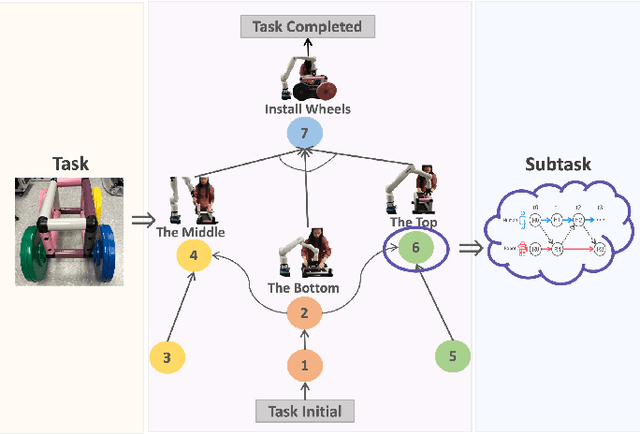
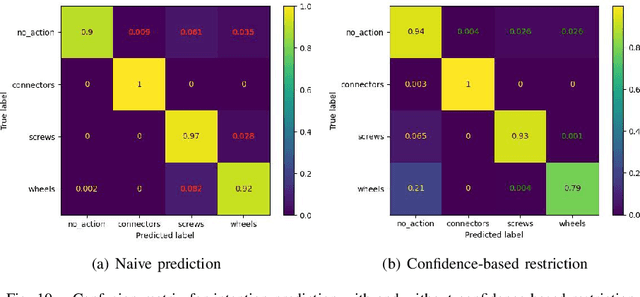
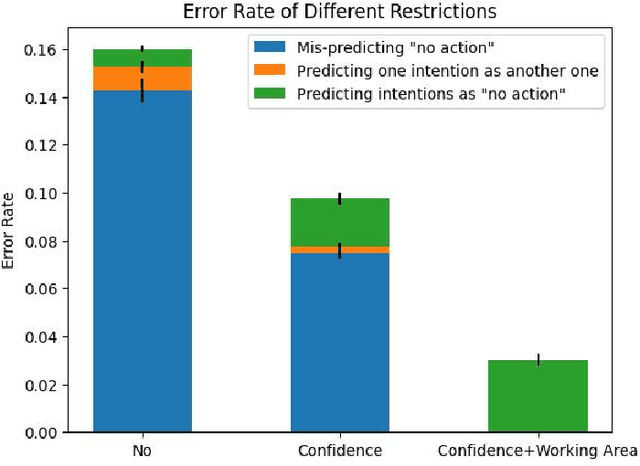
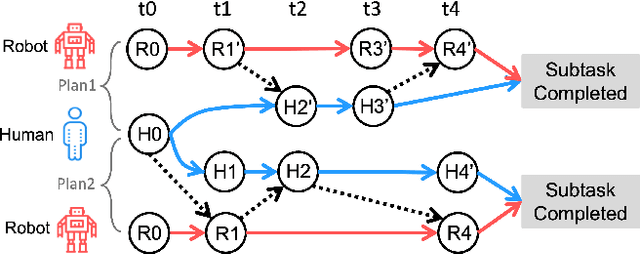
Long-term Human-Robot Collaboration (HRC) is crucial for developing flexible manufacturing systems and for integrating companion robots into daily human environments over extended periods. However, sustaining such collaborations requires overcoming challenges such as accurately understanding human intentions, maintaining robustness in noisy and dynamic environments, and adapting to diverse user behaviors. This paper presents a novel multimodal and hierarchical framework to address these challenges, facilitating efficient and robust long-term HRC. In particular, the proposed multimodal framework integrates visual observations with speech commands, which enables intuitive, natural, and flexible interactions between humans and robots. Additionally, our hierarchical approach for human detection and intention prediction significantly enhances the system's robustness, allowing robots to better understand human behaviors. The proactive understanding enables robots to take timely and appropriate actions based on predicted human intentions. We deploy the proposed multimodal hierarchical framework to the KINOVA GEN3 robot and conduct extensive user studies on real-world long-term HRC experiments. The results demonstrate that our approach effectively improves the system efficiency, flexibility, and adaptability in long-term HRC, showcasing the framework's potential to significantly improve the way humans and robots work together.
Continual Learning and Lifting of Koopman Dynamics for Linear Control of Legged Robots
Nov 21, 2024The control of legged robots, particularly humanoid and quadruped robots, presents significant challenges due to their high-dimensional and nonlinear dynamics. While linear systems can be effectively controlled using methods like Model Predictive Control (MPC), the control of nonlinear systems remains complex. One promising solution is the Koopman Operator, which approximates nonlinear dynamics with a linear model, enabling the use of proven linear control techniques. However, achieving accurate linearization through data-driven methods is difficult due to issues like approximation error, domain shifts, and the limitations of fixed linear state-space representations. These challenges restrict the scalability of Koopman-based approaches. This paper addresses these challenges by proposing a continual learning algorithm designed to iteratively refine Koopman dynamics for high-dimensional legged robots. The key idea is to progressively expand the dataset and latent space dimension, enabling the learned Koopman dynamics to converge towards accurate approximations of the true system dynamics. Theoretical analysis shows that the linear approximation error of our method converges monotonically. Experimental results demonstrate that our method achieves high control performance on robots like Unitree G1/H1/A1/Go2 and ANYmal D, across various terrains using simple linear MPC controllers. This work is the first to successfully apply linearized Koopman dynamics for locomotion control of high-dimensional legged robots, enabling a scalable model-based control solution.
Estimating Neural Network Robustness via Lipschitz Constant and Architecture Sensitivity
Oct 30, 2024Ensuring neural network robustness is essential for the safe and reliable operation of robotic learning systems, especially in perception and decision-making tasks within real-world environments. This paper investigates the robustness of neural networks in perception systems, specifically examining their sensitivity to targeted, small-scale perturbations. We identify the Lipschitz constant as a key metric for quantifying and enhancing network robustness. We derive an analytical expression to compute the Lipschitz constant based on neural network architecture, providing a theoretical basis for estimating and improving robustness. Several experiments reveal the relationship between network design, the Lipschitz constant, and robustness, offering practical insights for developing safer, more robust robot learning systems.
WeHelp: A Shared Autonomy System for Wheelchair Users
Sep 19, 2024

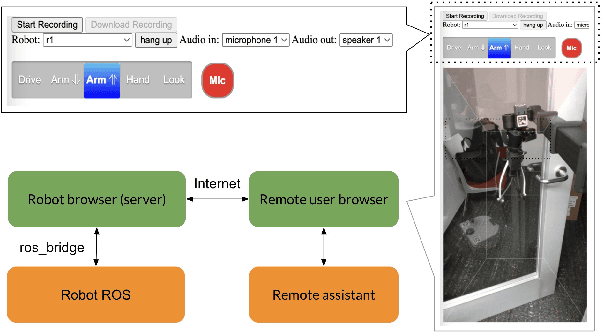

There is a large population of wheelchair users. Most of the wheelchair users need help with daily tasks. However, according to recent reports, their needs are not properly satisfied due to the lack of caregivers. Therefore, in this project, we develop WeHelp, a shared autonomy system aimed for wheelchair users. A robot with a WeHelp system has three modes, following mode, remote control mode and tele-operation mode. In the following mode, the robot follows the wheelchair user automatically via visual tracking. The wheelchair user can ask the robot to follow them from behind, by the left or by the right. When the wheelchair user asks for help, the robot will recognize the command via speech recognition, and then switch to the teleoperation mode or remote control mode. In the teleoperation mode, the wheelchair user takes over the robot with a joy stick and controls the robot to complete some complex tasks for their needs, such as opening doors, moving obstacles on the way, reaching objects on a high shelf or on the low ground, etc. In the remote control mode, a remote assistant takes over the robot and helps the wheelchair user complete some complex tasks for their needs. Our evaluation shows that the pipeline is useful and practical for wheelchair users. Source code and demo of the paper are available at \url{https://github.com/Walleclipse/WeHelp}.
KOROL: Learning Visualizable Object Feature with Koopman Operator Rollout for Manipulation
Jun 29, 2024Learning dexterous manipulation skills presents significant challenges due to complex nonlinear dynamics that underlie the interactions between objects and multi-fingered hands. Koopman operators have emerged as a robust method for modeling such nonlinear dynamics within a linear framework. However, current methods rely on runtime access to ground-truth (GT) object states, making them unsuitable for vision-based practical applications. Unlike image-to-action policies that implicitly learn visual features for control, we use a dynamics model, specifically the Koopman operator, to learn visually interpretable object features critical for robotic manipulation within a scene. We construct a Koopman operator using object features predicted by a feature extractor and utilize it to auto-regressively advance system states. We train the feature extractor to embed scene information into object features, thereby enabling the accurate propagation of robot trajectories. We evaluate our approach on simulated and real-world robot tasks, with results showing that it outperformed the model-based imitation learning NDP by 1.08$\times$ and the image-to-action Diffusion Policy by 1.16$\times$. The results suggest that our method maintains task success rates with learned features and extends applicability to real-world manipulation without GT object states.