 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMGenDrive: Bridging Multimodal Understanding and Generative World Modeling for End-to-End Driving
Apr 09, 2026Recent years have seen remarkable progress in autonomous driving, yet generalization to long-tail and open-world scenarios remains a major bottleneck for large-scale deployment. To address this challenge, some works use LLMs and VLMs for vision-language understanding and reasoning, enabling vehicles to interpret rare and safety-critical situations when generating actions. Others study generative world models to capture the spatio-temporal evolution of driving scenes, allowing agents to imagine possible futures before acting. Inspired by human intelligence, which unifies understanding and imagination, we explore a unified model for autonomous driving. We present LMGenDrive, the first framework that combines LLM-based multimodal understanding with generative world models for end-to-end closed-loop driving. Given multi-view camera inputs and natural-language instructions, LMGenDrive generates both future driving videos and control signals. This design provides complementary benefits: video prediction improves spatio-temporal scene modeling, while the LLM contributes strong semantic priors and instruction grounding from large-scale pretraining. We further propose a progressive three-stage training strategy, from vision pretraining to multi-step long-horizon driving, to improve stability and performance. LMGenDrive supports both low-latency online planning and autoregressive offline video generation. Experiments show that it significantly outperforms prior methods on challenging closed-loop benchmarks, with clear gains in instruction following, spatio-temporal understanding, and robustness to rare scenarios. These results suggest that unifying multimodal understanding and generation is a promising direction for more generalizable and robust embodied decision-making systems.
DriveDreamer-Policy: A Geometry-Grounded World-Action Model for Unified Generation and Planning
Apr 02, 2026Recently, world-action models (WAM) have emerged to bridge vision-language-action (VLA) models and world models, unifying their reasoning and instruction-following capabilities and spatio-temporal world modeling. However, existing WAM approaches often focus on modeling 2D appearance or latent representations, with limited geometric grounding-an essential element for embodied systems operating in the physical world. We present DriveDreamer-Policy, a unified driving world-action model that integrates depth generation, future video generation, and motion planning within a single modular architecture. The model employs a large language model to process language instructions, multi-view images, and actions, followed by three lightweight generators that produce depth, future video, and actions. By learning a geometry-aware world representation and using it to guide both future prediction and planning within a unified framework, the proposed model produces more coherent imagined futures and more informed driving actions, while maintaining modularity and controllable latency. Experiments on the Navsim v1 and v2 benchmarks demonstrate that DriveDreamer-Policy achieves strong performance on both closed-loop planning and world generation tasks. In particular, our model reaches 89.2 PDMS on Navsim v1 and 88.7 EPDMS on Navsim v2, outperforming existing world-model-based approaches while producing higher-quality future video and depth predictions. Ablation studies further show that explicit depth learning provides complementary benefits to video imagination and improves planning robustness.
DrivingGen: A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving
Jan 04, 2026Video generation models, as one form of world models, have emerged as one of the most exciting frontiers in AI, promising agents the ability to imagine the future by modeling the temporal evolution of complex scenes. In autonomous driving, this vision gives rise to driving world models: generative simulators that imagine ego and agent futures, enabling scalable simulation, safe testing of corner cases, and rich synthetic data generation. Yet, despite fast-growing research activity, the field lacks a rigorous benchmark to measure progress and guide priorities. Existing evaluations remain limited: generic video metrics overlook safety-critical imaging factors; trajectory plausibility is rarely quantified; temporal and agent-level consistency is neglected; and controllability with respect to ego conditioning is ignored. Moreover, current datasets fail to cover the diversity of conditions required for real-world deployment. To address these gaps, we present DrivingGen, the first comprehensive benchmark for generative driving world models. DrivingGen combines a diverse evaluation dataset curated from both driving datasets and internet-scale video sources, spanning varied weather, time of day, geographic regions, and complex maneuvers, with a suite of new metrics that jointly assess visual realism, trajectory plausibility, temporal coherence, and controllability. Benchmarking 14 state-of-the-art models reveals clear trade-offs: general models look better but break physics, while driving-specific ones capture motion realistically but lag in visual quality. DrivingGen offers a unified evaluation framework to foster reliable, controllable, and deployable driving world models, enabling scalable simulation, planning, and data-driven decision-making.
Deployable and Generalizable Motion Prediction: Taxonomy, Open Challenges and Future Directions
May 14, 2025



Motion prediction, the anticipation of future agent states or scene evolution, is rooted in human cognition, bridging perception and decision-making. It enables intelligent systems, such as robots and self-driving cars, to act safely in dynamic, human-involved environments, and informs broader time-series reasoning challenges. With advances in methods, representations, and datasets, the field has seen rapid progress, reflected in quickly evolving benchmark results. Yet, when state-of-the-art methods are deployed in the real world, they often struggle to generalize to open-world conditions and fall short of deployment standards. This reveals a gap between research benchmarks, which are often idealized or ill-posed, and real-world complexity. To address this gap, this survey revisits the generalization and deployability of motion prediction models, with an emphasis on the applications of robotics, autonomous driving, and human motion. We first offer a comprehensive taxonomy of motion prediction methods, covering representations, modeling strategies, application domains, and evaluation protocols. We then study two key challenges: (1) how to push motion prediction models to be deployable to realistic deployment standards, where motion prediction does not act in a vacuum, but functions as one module of closed-loop autonomy stacks - it takes input from the localization and perception, and informs downstream planning and control. 2) how to generalize motion prediction models from limited seen scenarios/datasets to the open-world settings. Throughout the paper, we highlight critical open challenges to guide future work, aiming to recalibrate the community's efforts, fostering progress that is not only measurable but also meaningful for real-world applications.
Adaptive Markup Language Generation for Contextually-Grounded Visual Document Understanding
May 08, 2025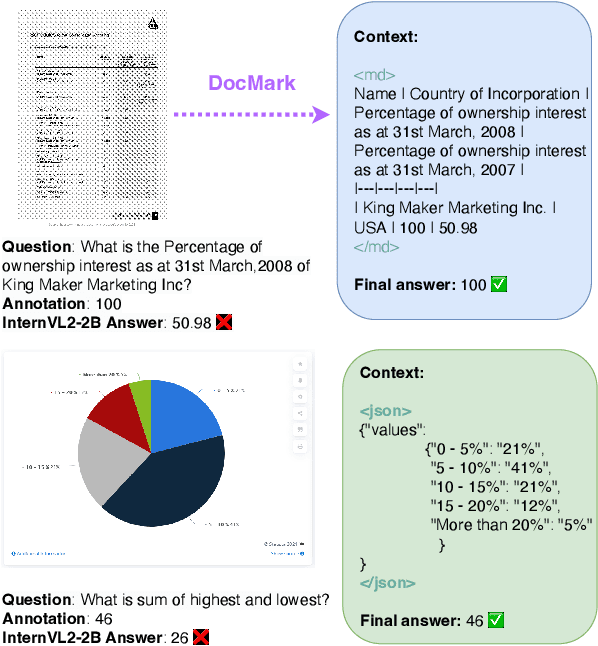
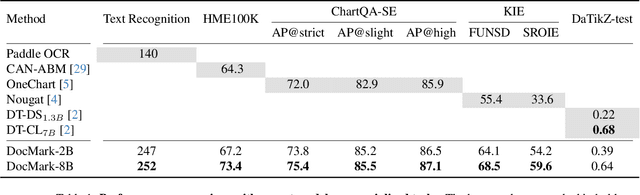
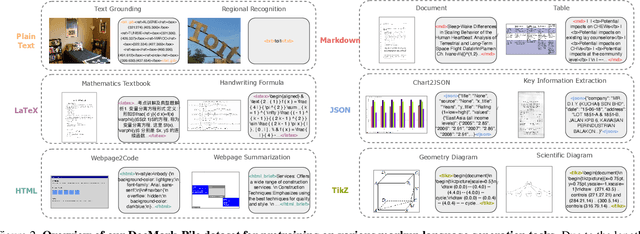
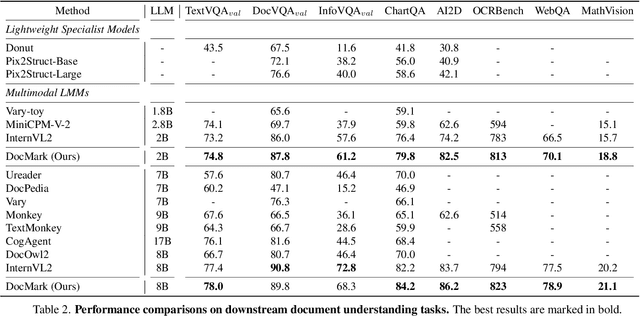
Visual Document Understanding has become essential with the increase of text-rich visual content. This field poses significant challenges due to the need for effective integration of visual perception and textual comprehension, particularly across diverse document types with complex layouts. Moreover, existing fine-tuning datasets for this domain often fall short in providing the detailed contextual information for robust understanding, leading to hallucinations and limited comprehension of spatial relationships among visual elements. To address these challenges, we propose an innovative pipeline that utilizes adaptive generation of markup languages, such as Markdown, JSON, HTML, and TiKZ, to build highly structured document representations and deliver contextually-grounded responses. We introduce two fine-grained structured datasets: DocMark-Pile, comprising approximately 3.8M pretraining data pairs for document parsing, and DocMark-Instruct, featuring 624k fine-tuning data annotations for grounded instruction following. Extensive experiments demonstrate that our proposed model significantly outperforms existing state-of-theart MLLMs across a range of visual document understanding benchmarks, facilitating advanced reasoning and comprehension capabilities in complex visual scenarios. Our code and models are released at https://github. com/Euphoria16/DocMark.
High-Fidelity Diffusion Face Swapping with ID-Constrained Facial Conditioning
Mar 28, 2025Face swapping aims to seamlessly transfer a source facial identity onto a target while preserving target attributes such as pose and expression. Diffusion models, known for their superior generative capabilities, have recently shown promise in advancing face-swapping quality. This paper addresses two key challenges in diffusion-based face swapping: the prioritized preservation of identity over target attributes and the inherent conflict between identity and attribute conditioning. To tackle these issues, we introduce an identity-constrained attribute-tuning framework for face swapping that first ensures identity preservation and then fine-tunes for attribute alignment, achieved through a decoupled condition injection. We further enhance fidelity by incorporating identity and adversarial losses in a post-training refinement stage. Our proposed identity-constrained diffusion-based face-swapping model outperforms existing methods in both qualitative and quantitative evaluations, demonstrating superior identity similarity and attribute consistency, achieving a new state-of-the-art performance in high-fidelity face swapping.
VividFace: A Diffusion-Based Hybrid Framework for High-Fidelity Video Face Swapping
Dec 15, 2024



Video face swapping is becoming increasingly popular across various applications, yet existing methods primarily focus on static images and struggle with video face swapping because of temporal consistency and complex scenarios. In this paper, we present the first diffusion-based framework specifically designed for video face swapping. Our approach introduces a novel image-video hybrid training framework that leverages both abundant static image data and temporal video sequences, addressing the inherent limitations of video-only training. The framework incorporates a specially designed diffusion model coupled with a VidFaceVAE that effectively processes both types of data to better maintain temporal coherence of the generated videos. To further disentangle identity and pose features, we construct the Attribute-Identity Disentanglement Triplet (AIDT) Dataset, where each triplet has three face images, with two images sharing the same pose and two sharing the same identity. Enhanced with a comprehensive occlusion augmentation, this dataset also improves robustness against occlusions. Additionally, we integrate 3D reconstruction techniques as input conditioning to our network for handling large pose variations. Extensive experiments demonstrate that our framework achieves superior performance in identity preservation, temporal consistency, and visual quality compared to existing methods, while requiring fewer inference steps. Our approach effectively mitigates key challenges in video face swapping, including temporal flickering, identity preservation, and robustness to occlusions and pose variations.
EasyRef: Omni-Generalized Group Image Reference for Diffusion Models via Multimodal LLM
Dec 12, 2024



Significant achievements in personalization of diffusion models have been witnessed. Conventional tuning-free methods mostly encode multiple reference images by averaging their image embeddings as the injection condition, but such an image-independent operation cannot perform interaction among images to capture consistent visual elements within multiple references. Although the tuning-based Low-Rank Adaptation (LoRA) can effectively extract consistent elements within multiple images through the training process, it necessitates specific finetuning for each distinct image group. This paper introduces EasyRef, a novel plug-and-play adaptation method that enables diffusion models to be conditioned on multiple reference images and the text prompt. To effectively exploit consistent visual elements within multiple images, we leverage the multi-image comprehension and instruction-following capabilities of the multimodal large language model (MLLM), prompting it to capture consistent visual elements based on the instruction. Besides, injecting the MLLM's representations into the diffusion process through adapters can easily generalize to unseen domains, mining the consistent visual elements within unseen data. To mitigate computational costs and enhance fine-grained detail preservation, we introduce an efficient reference aggregation strategy and a progressive training scheme. Finally, we introduce MRBench, a new multi-reference image generation benchmark. Experimental results demonstrate EasyRef surpasses both tuning-free methods like IP-Adapter and tuning-based methods like LoRA, achieving superior aesthetic quality and robust zero-shot generalization across diverse domains.
SmartPretrain: Model-Agnostic and Dataset-Agnostic Representation Learning for Motion Prediction
Oct 11, 2024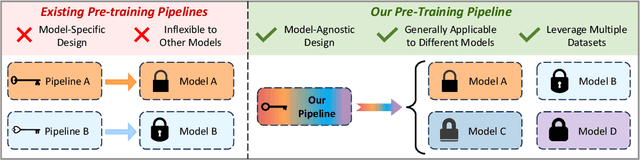
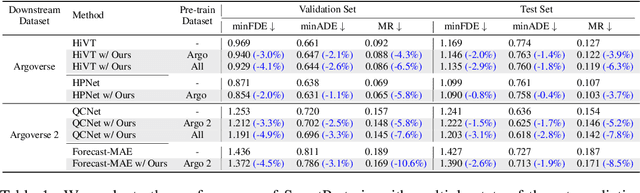
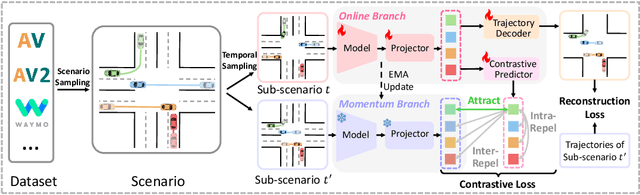

Predicting the future motion of surrounding agents is essential for autonomous vehicles (AVs) to operate safely in dynamic, human-robot-mixed environments. However, the scarcity of large-scale driving datasets has hindered the development of robust and generalizable motion prediction models, limiting their ability to capture complex interactions and road geometries. Inspired by recent advances in natural language processing (NLP) and computer vision (CV), self-supervised learning (SSL) has gained significant attention in the motion prediction community for learning rich and transferable scene representations. Nonetheless, existing pre-training methods for motion prediction have largely focused on specific model architectures and single dataset, limiting their scalability and generalizability. To address these challenges, we propose SmartPretrain, a general and scalable SSL framework for motion prediction that is both model-agnostic and dataset-agnostic. Our approach integrates contrastive and reconstructive SSL, leveraging the strengths of both generative and discriminative paradigms to effectively represent spatiotemporal evolution and interactions without imposing architectural constraints. Additionally, SmartPretrain employs a dataset-agnostic scenario sampling strategy that integrates multiple datasets, enhancing data volume, diversity, and robustness. Extensive experiments on multiple datasets demonstrate that SmartPretrain consistently improves the performance of state-of-the-art prediction models across datasets, data splits and main metrics. For instance, SmartPretrain significantly reduces the MissRate of Forecast-MAE by 10.6%. These results highlight SmartPretrain's effectiveness as a unified, scalable solution for motion prediction, breaking free from the limitations of the small-data regime. Codes are available at https://github.com/youngzhou1999/SmartPretrain
MoVA: Adapting Mixture of Vision Experts to Multimodal Context
Apr 19, 2024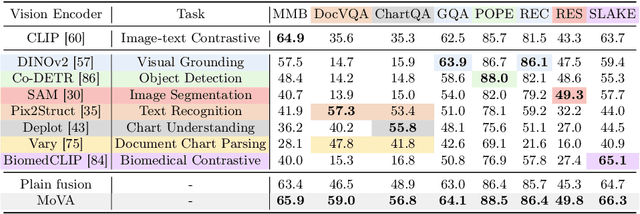
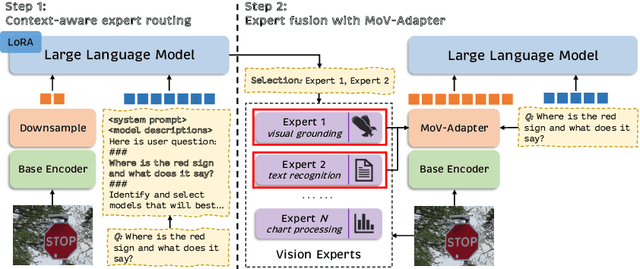

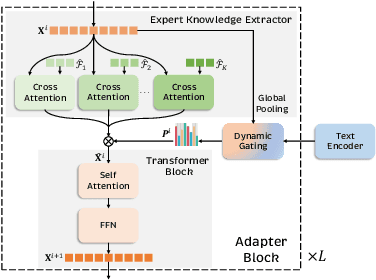
As the key component in multimodal large language models (MLLMs), the ability of the visual encoder greatly affects MLLM's understanding on diverse image content. Although some large-scale pretrained vision encoders such as vision encoders in CLIP and DINOv2 have brought promising performance, we found that there is still no single vision encoder that can dominate various image content understanding, e.g., the CLIP vision encoder leads to outstanding results on general image understanding but poor performance on document or chart content. To alleviate the bias of CLIP vision encoder, we first delve into the inherent behavior of different pre-trained vision encoders and then propose the MoVA, a powerful and novel MLLM, adaptively routing and fusing task-specific vision experts with a coarse-to-fine mechanism. In the coarse-grained stage, we design a context-aware expert routing strategy to dynamically select the most suitable vision experts according to the user instruction, input image, and expertise of vision experts. This benefits from the powerful model function understanding ability of the large language model (LLM) equipped with expert-routing low-rank adaptation (LoRA). In the fine-grained stage, we elaborately conduct the mixture-of-vision-expert adapter (MoV-Adapter) to extract and fuse task-specific knowledge from various experts. This coarse-to-fine paradigm effectively leverages representations from experts based on multimodal context and model expertise, further enhancing the generalization ability. We conduct extensive experiments to evaluate the effectiveness of the proposed approach. Without any bells and whistles, MoVA can achieve significant performance gains over current state-of-the-art methods in a wide range of challenging multimodal benchmarks. Codes and models will be available at https://github.com/TempleX98/MoVA.