 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADT: Tuning Diffusion Models with Adversarial Supervision
Apr 15, 2025



Diffusion models have achieved outstanding image generation by reversing a forward noising process to approximate true data distributions. During training, these models predict diffusion scores from noised versions of true samples in a single forward pass, while inference requires iterative denoising starting from white noise. This training-inference divergences hinder the alignment between inference and training data distributions, due to potential prediction biases and cumulative error accumulation. To address this problem, we propose an intuitive but effective fine-tuning framework, called Adversarial Diffusion Tuning (ADT), by stimulating the inference process during optimization and aligning the final outputs with training data by adversarial supervision. Specifically, to achieve robust adversarial training, ADT features a siamese-network discriminator with a fixed pre-trained backbone and lightweight trainable parameters, incorporates an image-to-image sampling strategy to smooth discriminative difficulties, and preserves the original diffusion loss to prevent discriminator hacking. In addition, we carefully constrain the backward-flowing path for back-propagating gradients along the inference path without incurring memory overload or gradient explosion. Finally, extensive experiments on Stable Diffusion models (v1.5, XL, and v3), demonstrate that ADT significantly improves both distribution alignment and image quality.
High-Fidelity Diffusion Face Swapping with ID-Constrained Facial Conditioning
Mar 28, 2025Face swapping aims to seamlessly transfer a source facial identity onto a target while preserving target attributes such as pose and expression. Diffusion models, known for their superior generative capabilities, have recently shown promise in advancing face-swapping quality. This paper addresses two key challenges in diffusion-based face swapping: the prioritized preservation of identity over target attributes and the inherent conflict between identity and attribute conditioning. To tackle these issues, we introduce an identity-constrained attribute-tuning framework for face swapping that first ensures identity preservation and then fine-tunes for attribute alignment, achieved through a decoupled condition injection. We further enhance fidelity by incorporating identity and adversarial losses in a post-training refinement stage. Our proposed identity-constrained diffusion-based face-swapping model outperforms existing methods in both qualitative and quantitative evaluations, demonstrating superior identity similarity and attribute consistency, achieving a new state-of-the-art performance in high-fidelity face swapping.
VividFace: A Diffusion-Based Hybrid Framework for High-Fidelity Video Face Swapping
Dec 15, 2024



Video face swapping is becoming increasingly popular across various applications, yet existing methods primarily focus on static images and struggle with video face swapping because of temporal consistency and complex scenarios. In this paper, we present the first diffusion-based framework specifically designed for video face swapping. Our approach introduces a novel image-video hybrid training framework that leverages both abundant static image data and temporal video sequences, addressing the inherent limitations of video-only training. The framework incorporates a specially designed diffusion model coupled with a VidFaceVAE that effectively processes both types of data to better maintain temporal coherence of the generated videos. To further disentangle identity and pose features, we construct the Attribute-Identity Disentanglement Triplet (AIDT) Dataset, where each triplet has three face images, with two images sharing the same pose and two sharing the same identity. Enhanced with a comprehensive occlusion augmentation, this dataset also improves robustness against occlusions. Additionally, we integrate 3D reconstruction techniques as input conditioning to our network for handling large pose variations. Extensive experiments demonstrate that our framework achieves superior performance in identity preservation, temporal consistency, and visual quality compared to existing methods, while requiring fewer inference steps. Our approach effectively mitigates key challenges in video face swapping, including temporal flickering, identity preservation, and robustness to occlusions and pose variations.
EasyRef: Omni-Generalized Group Image Reference for Diffusion Models via Multimodal LLM
Dec 12, 2024



Significant achievements in personalization of diffusion models have been witnessed. Conventional tuning-free methods mostly encode multiple reference images by averaging their image embeddings as the injection condition, but such an image-independent operation cannot perform interaction among images to capture consistent visual elements within multiple references. Although the tuning-based Low-Rank Adaptation (LoRA) can effectively extract consistent elements within multiple images through the training process, it necessitates specific finetuning for each distinct image group. This paper introduces EasyRef, a novel plug-and-play adaptation method that enables diffusion models to be conditioned on multiple reference images and the text prompt. To effectively exploit consistent visual elements within multiple images, we leverage the multi-image comprehension and instruction-following capabilities of the multimodal large language model (MLLM), prompting it to capture consistent visual elements based on the instruction. Besides, injecting the MLLM's representations into the diffusion process through adapters can easily generalize to unseen domains, mining the consistent visual elements within unseen data. To mitigate computational costs and enhance fine-grained detail preservation, we introduce an efficient reference aggregation strategy and a progressive training scheme. Finally, we introduce MRBench, a new multi-reference image generation benchmark. Experimental results demonstrate EasyRef surpasses both tuning-free methods like IP-Adapter and tuning-based methods like LoRA, achieving superior aesthetic quality and robust zero-shot generalization across diverse domains.
Pretrained Reversible Generation as Unsupervised Visual Representation Learning
Nov 29, 2024Recent generative models based on score matching and flow matching have significantly advanced generation tasks, but their potential in discriminative tasks remains underexplored. Previous approaches, such as generative classifiers, have not fully leveraged the capabilities of these models for discriminative tasks due to their intricate designs. We propose Pretrained Reversible Generation (PRG), which extracts unsupervised representations by reversing the generative process of a pretrained continuous flow model. PRG effectively reuses unsupervised generative models, leveraging their high capacity to serve as robust and generalizable feature extractors for downstream tasks. Our method consistently outperforms prior approaches across multiple benchmarks, achieving state-of-the-art performance among generative model-based methods, including 78\% top-1 accuracy on ImageNet. Extensive ablation studies further validate the effectiveness of our approach.
Exploring the Role of Large Language Models in Prompt Encoding for Diffusion Models
Jun 17, 2024Large language models (LLMs) based on decoder-only transformers have demonstrated superior text understanding capabilities compared to CLIP and T5-series models. However, the paradigm for utilizing current advanced LLMs in text-to-image diffusion models remains to be explored. We observed an unusual phenomenon: directly using a large language model as the prompt encoder significantly degrades the prompt-following ability in image generation. We identified two main obstacles behind this issue. One is the misalignment between the next token prediction training in LLM and the requirement for discriminative prompt features in diffusion models. The other is the intrinsic positional bias introduced by the decoder-only architecture. To deal with this issue, we propose a novel framework to fully harness the capabilities of LLMs. Through the carefully designed usage guidance, we effectively enhance the text representation capability for prompt encoding and eliminate its inherent positional bias. This allows us to integrate state-of-the-art LLMs into the text-to-image generation model flexibly. Furthermore, we also provide an effective manner to fuse multiple LLMs into our framework. Considering the excellent performance and scaling capabilities demonstrated by the transformer architecture, we further design an LLM-Infused Diffusion Transformer (LI-DiT) based on the framework. We conduct extensive experiments to validate LI-DiT across model size and data size. Benefiting from the inherent ability of the LLMs and our innovative designs, the prompt understanding performance of LI-DiT easily surpasses state-of-the-art open-source models as well as mainstream closed-source commercial models including Stable Diffusion 3, DALL-E 3, and Midjourney V6. The powerful LI-DiT-10B will be available after further optimization and security checks.
MoVA: Adapting Mixture of Vision Experts to Multimodal Context
Apr 19, 2024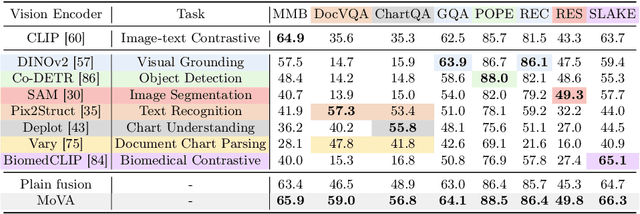
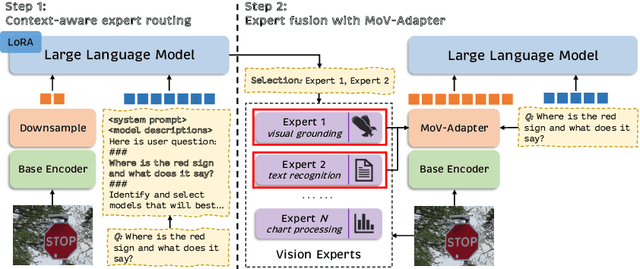

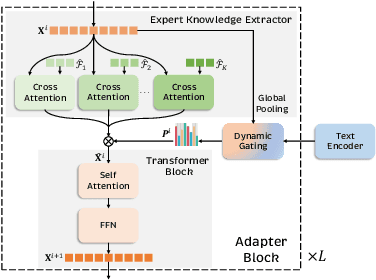
As the key component in multimodal large language models (MLLMs), the ability of the visual encoder greatly affects MLLM's understanding on diverse image content. Although some large-scale pretrained vision encoders such as vision encoders in CLIP and DINOv2 have brought promising performance, we found that there is still no single vision encoder that can dominate various image content understanding, e.g., the CLIP vision encoder leads to outstanding results on general image understanding but poor performance on document or chart content. To alleviate the bias of CLIP vision encoder, we first delve into the inherent behavior of different pre-trained vision encoders and then propose the MoVA, a powerful and novel MLLM, adaptively routing and fusing task-specific vision experts with a coarse-to-fine mechanism. In the coarse-grained stage, we design a context-aware expert routing strategy to dynamically select the most suitable vision experts according to the user instruction, input image, and expertise of vision experts. This benefits from the powerful model function understanding ability of the large language model (LLM) equipped with expert-routing low-rank adaptation (LoRA). In the fine-grained stage, we elaborately conduct the mixture-of-vision-expert adapter (MoV-Adapter) to extract and fuse task-specific knowledge from various experts. This coarse-to-fine paradigm effectively leverages representations from experts based on multimodal context and model expertise, further enhancing the generalization ability. We conduct extensive experiments to evaluate the effectiveness of the proposed approach. Without any bells and whistles, MoVA can achieve significant performance gains over current state-of-the-art methods in a wide range of challenging multimodal benchmarks. Codes and models will be available at https://github.com/TempleX98/MoVA.
MedFLIP: Medical Vision-and-Language Self-supervised Fast Pre-Training with Masked Autoencoder
Mar 07, 2024Within the domain of medical analysis, extensive research has explored the potential of mutual learning between Masked Autoencoders(MAEs) and multimodal data. However, the impact of MAEs on intermodality remains a key challenge. We introduce MedFLIP, a Fast Language-Image Pre-training method for Medical analysis. We explore MAEs for zero-shot learning with crossed domains, which enhances the model ability to learn from limited data, a common scenario in medical diagnostics. We verify that masking an image does not affect intermodal learning. Furthermore, we propose the SVD loss to enhance the representation learning for characteristics of medical images, aiming to improve classification accuracy by leveraging the structural intricacies of such data. Lastly, we validate using language will improve the zero-shot performance for the medical image analysis. MedFLIP scaling of the masking process marks an advancement in the field, offering a pathway to rapid and precise medical image analysis without the traditional computational bottlenecks. Through experiments and validation, MedFLIP demonstrates efficient performance improvements, setting an explored standard for future research and application in medical diagnostics.
Towards Large-scale Masked Face Recognition
Oct 25, 2023


During the COVID-19 coronavirus epidemic, almost everyone is wearing masks, which poses a huge challenge for deep learning-based face recognition algorithms. In this paper, we will present our \textbf{championship} solutions in ICCV MFR WebFace260M and InsightFace unconstrained tracks. We will focus on four challenges in large-scale masked face recognition, i.e., super-large scale training, data noise handling, masked and non-masked face recognition accuracy balancing, and how to design inference-friendly model architecture. We hope that the discussion on these four aspects can guide future research towards more robust masked face recognition systems.
Rethinking Robust Representation Learning Under Fine-grained Noisy Faces
Aug 08, 2022



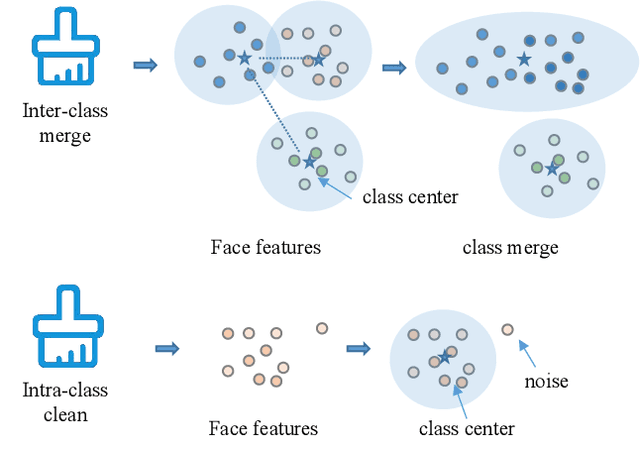
Learning robust feature representation from large-scale noisy faces stands out as one of the key challenges in high-performance face recognition. Recent attempts have been made to cope with this challenge by alleviating the intra-class conflict and inter-class conflict. However, the unconstrained noise type in each conflict still makes it difficult for these algorithms to perform well. To better understand this, we reformulate the noise type of each class in a more fine-grained manner as N-identities|K^C-clusters. Different types of noisy faces can be generated by adjusting the values of \nkc. Based on this unified formulation, we found that the main barrier behind the noise-robust representation learning is the flexibility of the algorithm under different N, K, and C. For this potential problem, we propose a new method, named Evolving Sub-centers Learning~(ESL), to find optimal hyperplanes to accurately describe the latent space of massive noisy faces. More specifically, we initialize M sub-centers for each class and ESL encourages it to be automatically aligned to N-identities|K^C-clusters faces via producing, merging, and dropping operations. Images belonging to the same identity in noisy faces can effectively converge to the same sub-center and samples with different identities will be pushed away. We inspect its effectiveness with an elaborate ablation study on the synthetic noisy dataset with different N, K, and C. Without any bells and whistles, ESL can achieve significant performance gains over state-of-the-art methods on large-scale noisy faces